Rola pośredników w ruchu HTTP
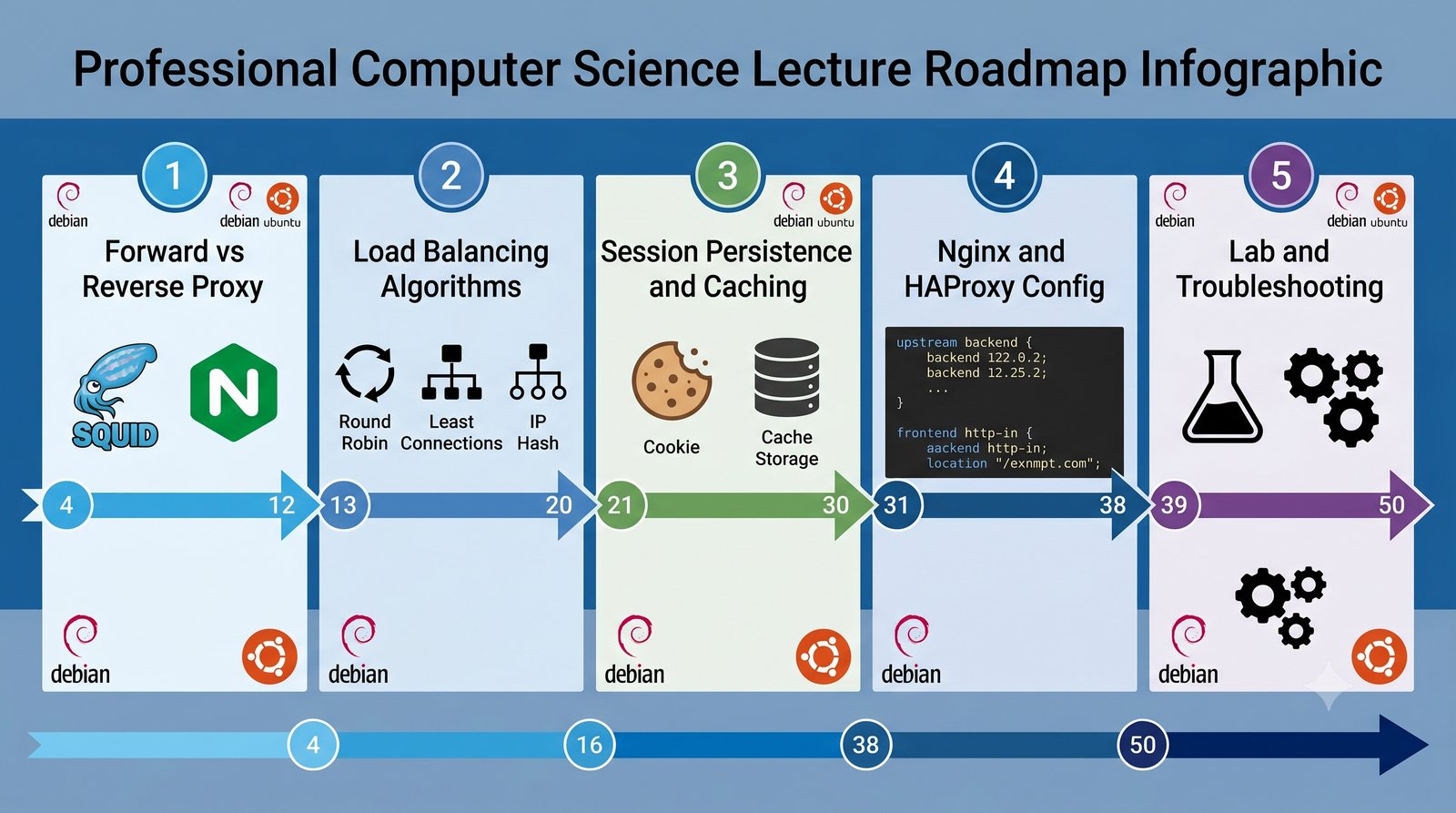
Rola pośredników w ruchu HTTP, buforowanie, Load Balancing z Nginx i HAProxy
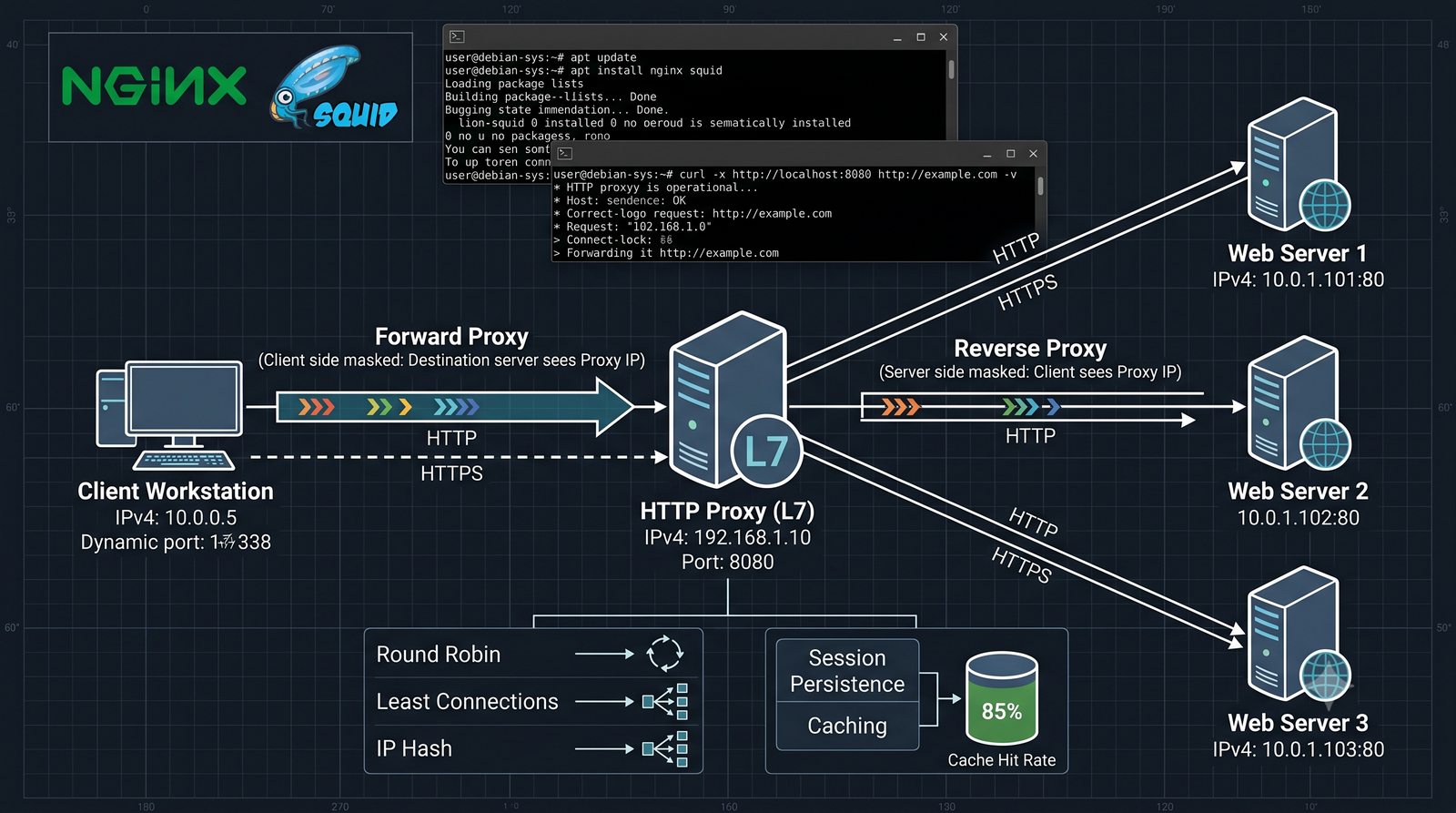
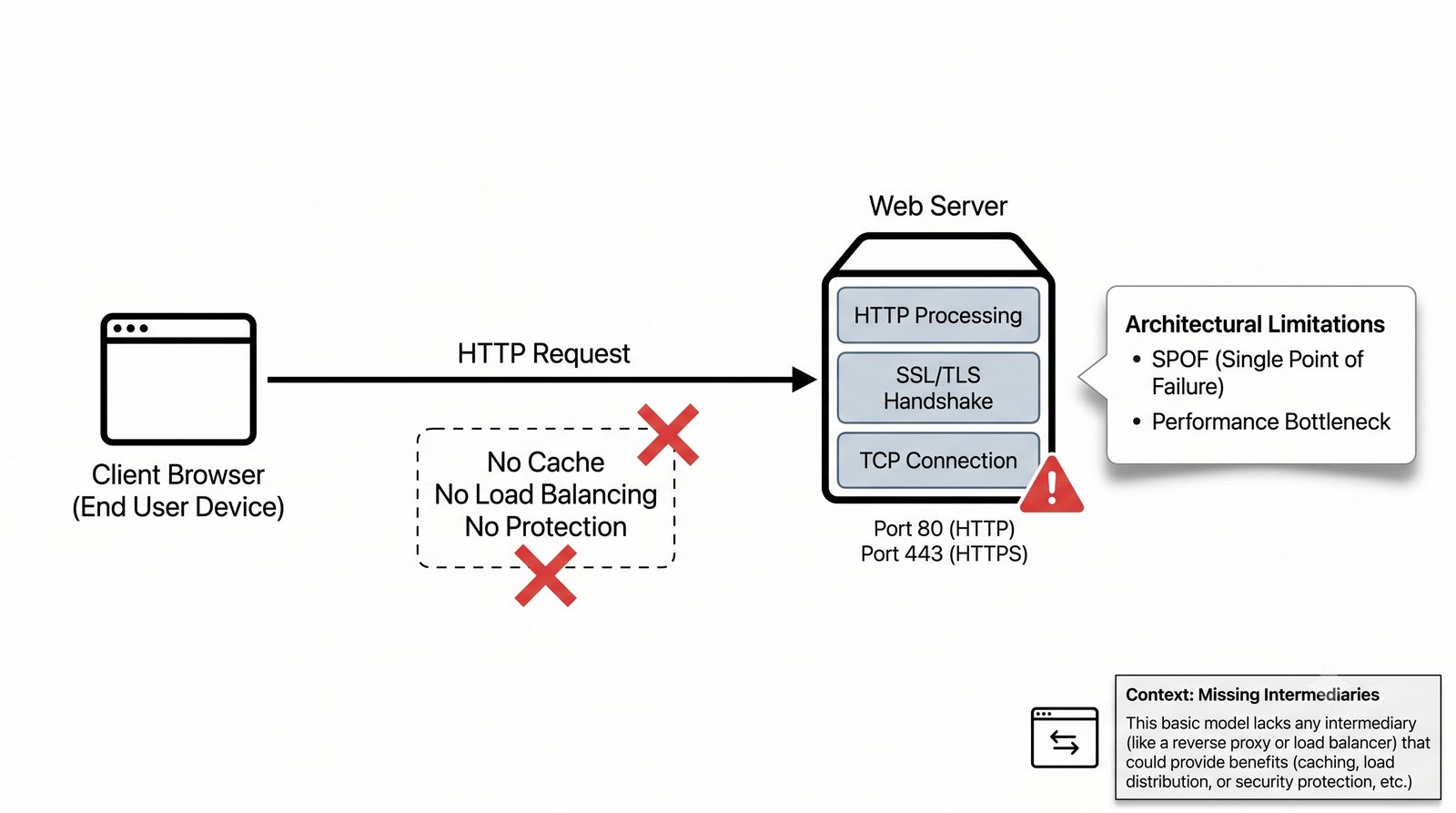
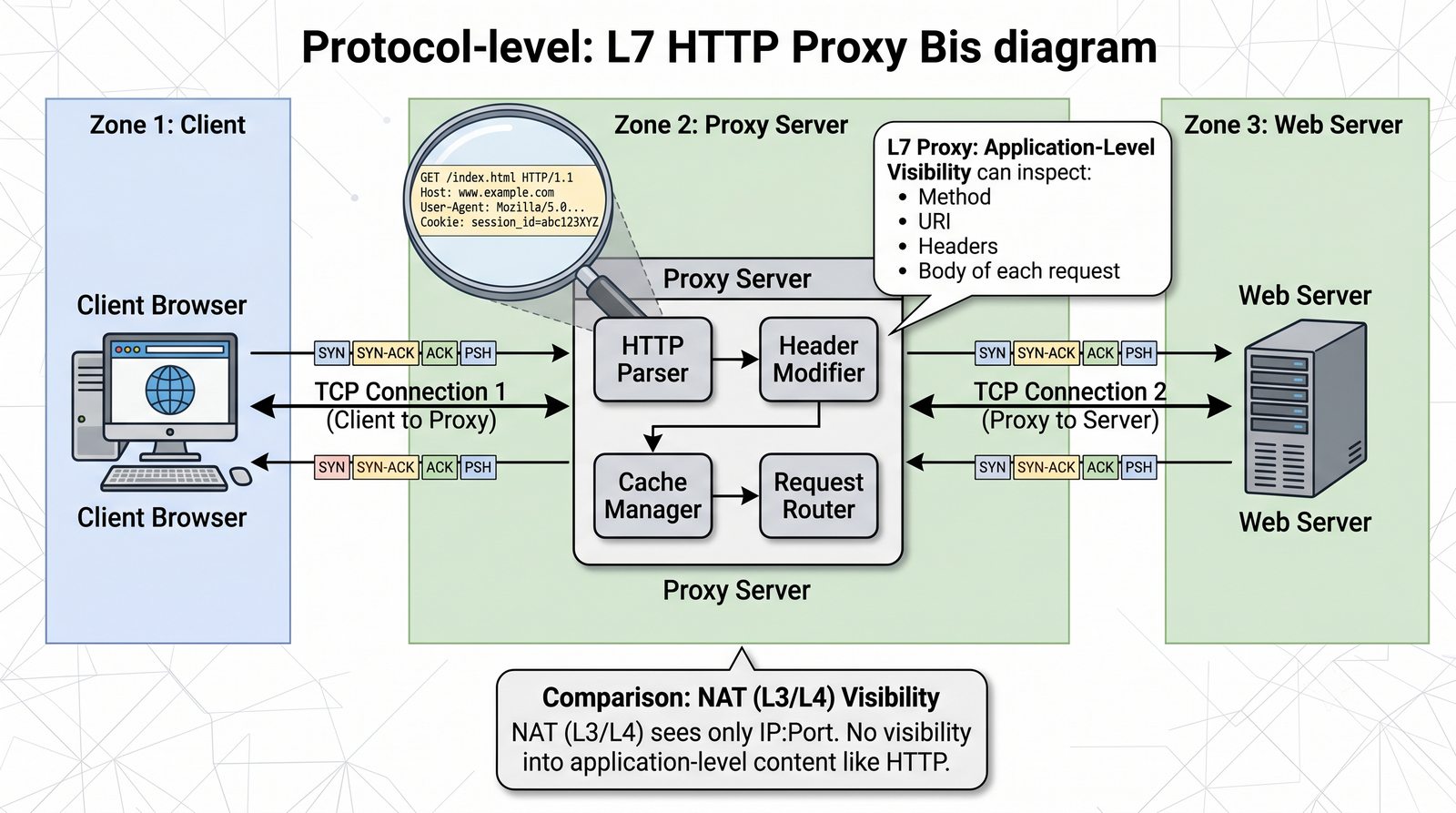
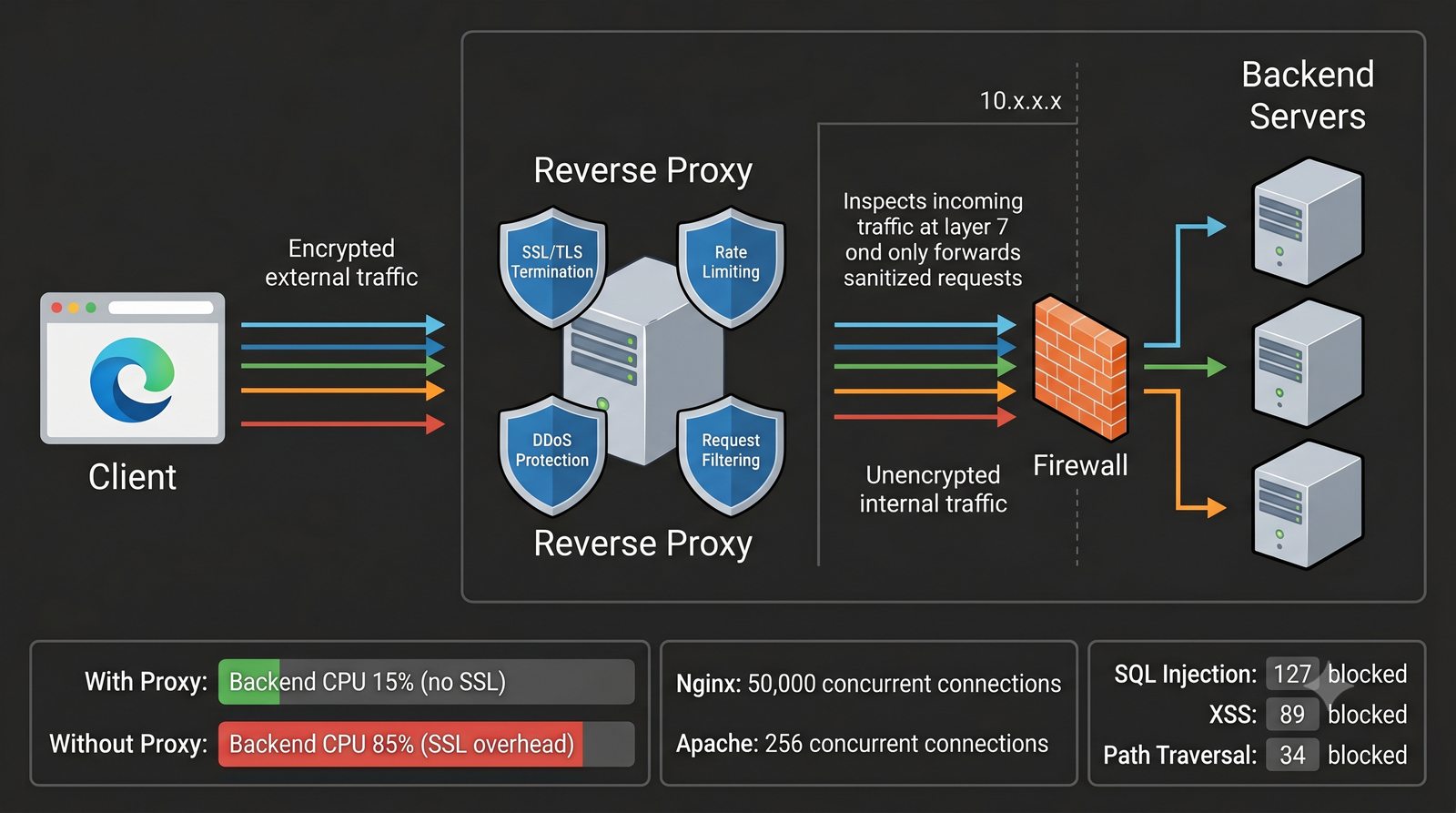
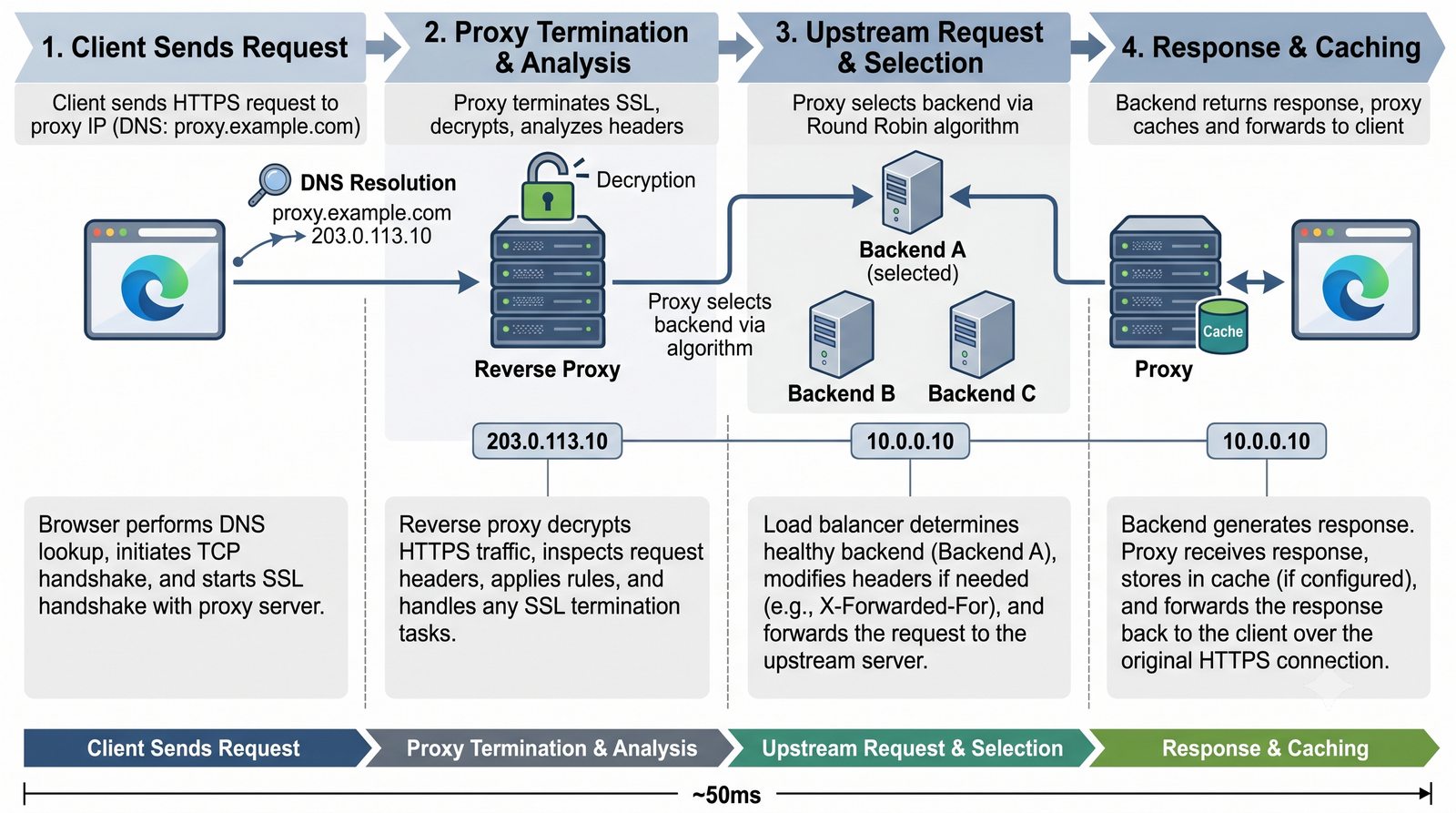
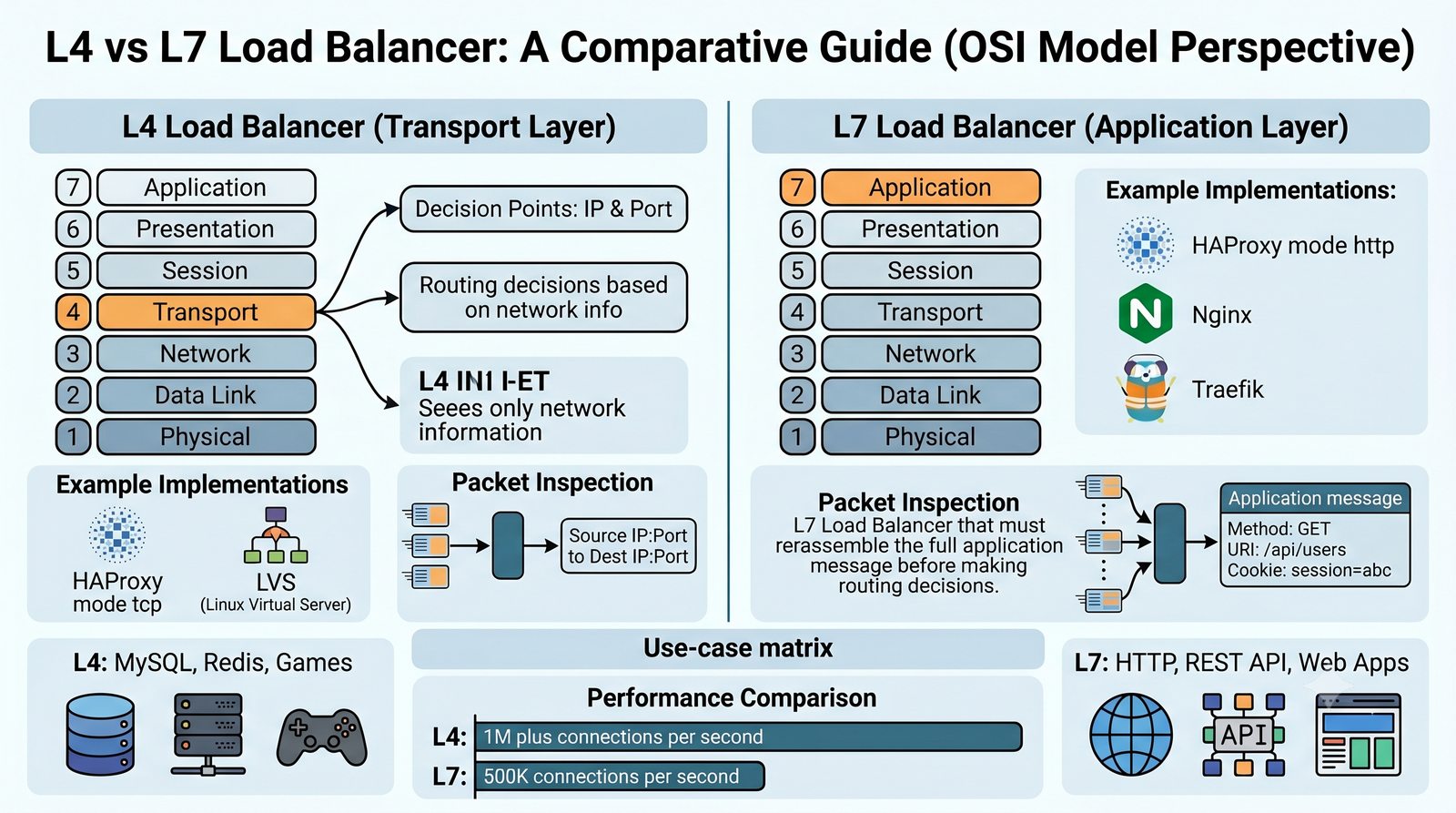
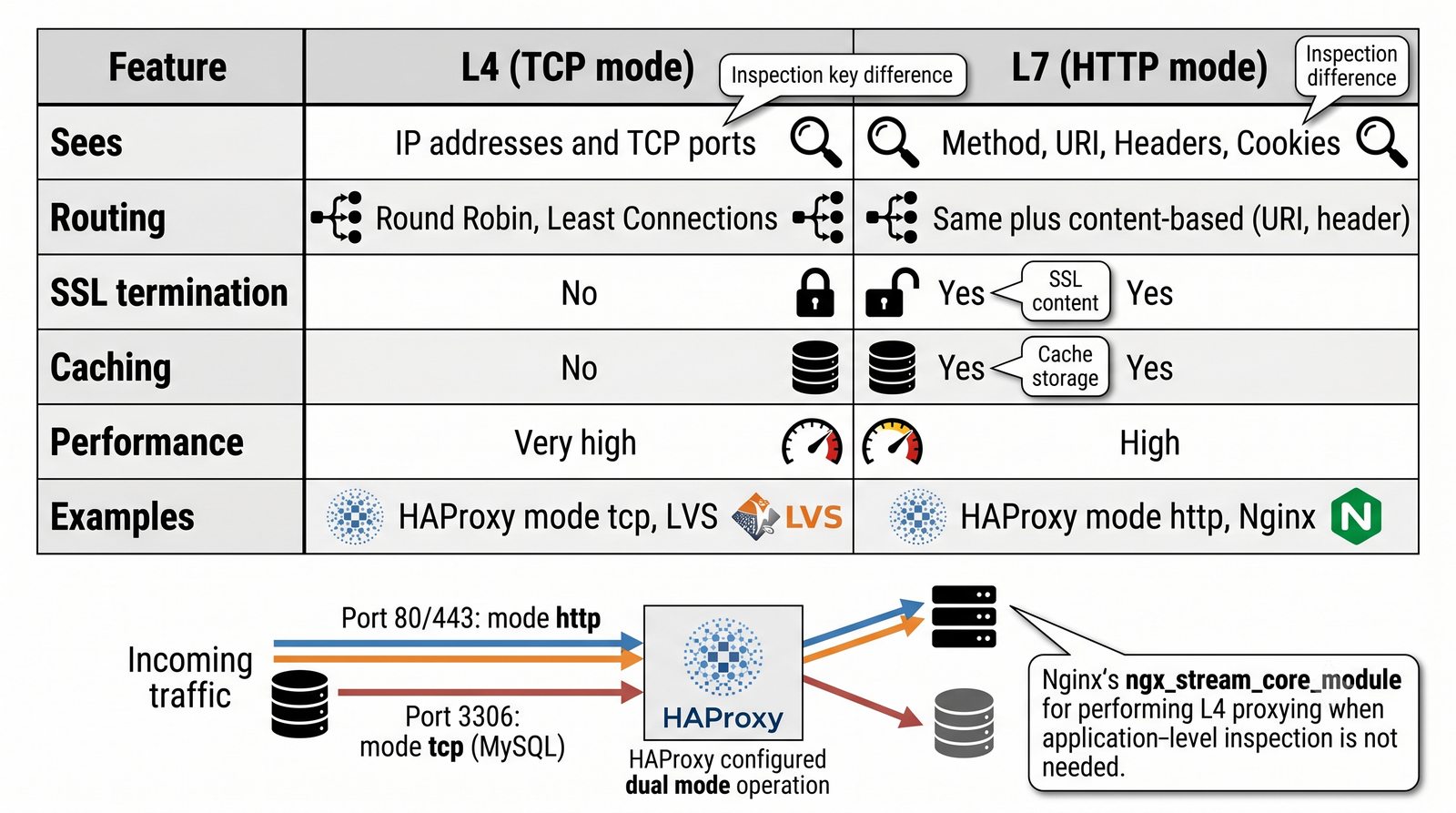
- Proxy (pośrednik) to serwer pośredniczący w komunikacji HTTP między klientem a serwerem docelowym, działający na warstwie L7 (aplikacji) modelu OSI
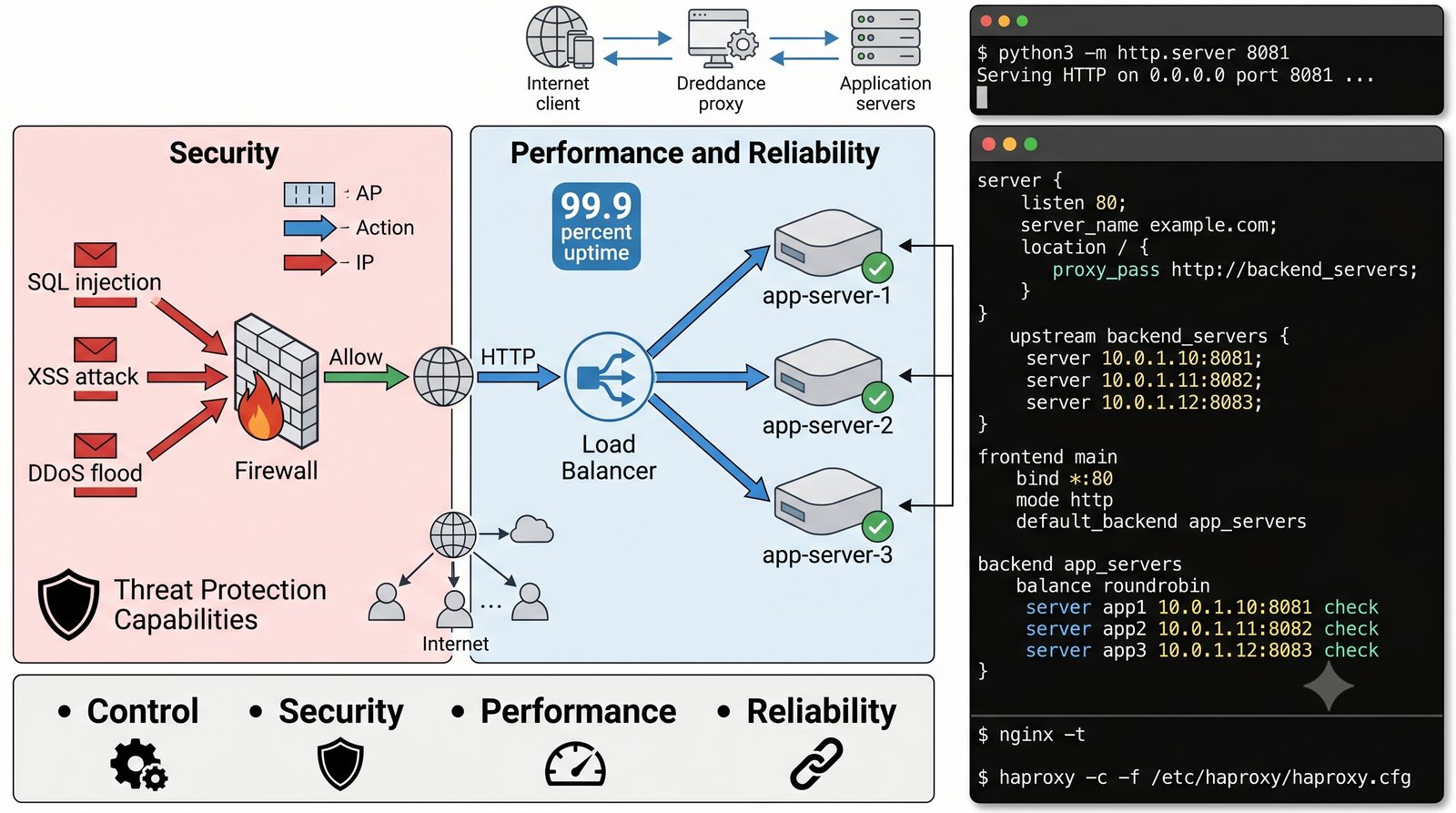
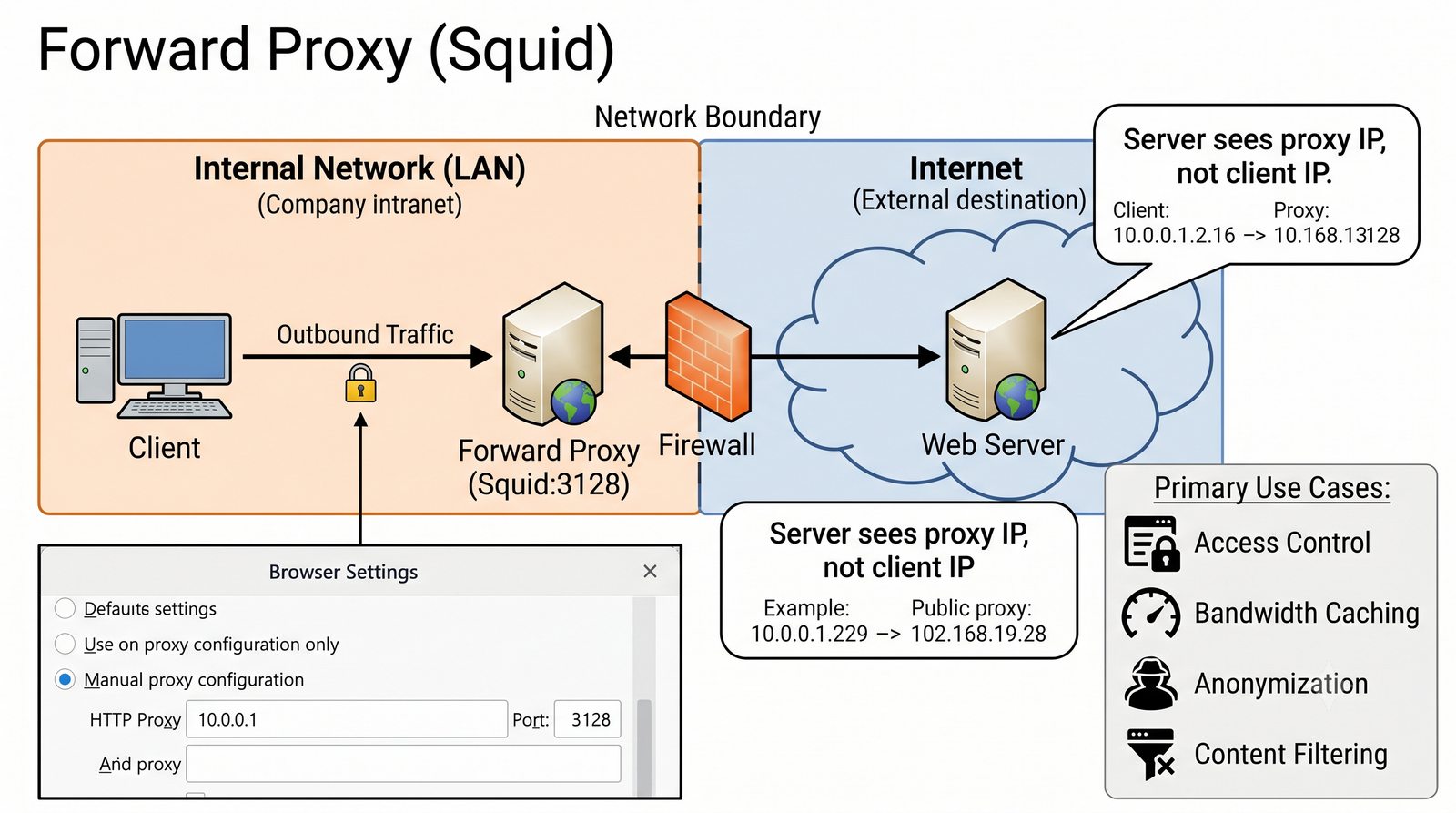
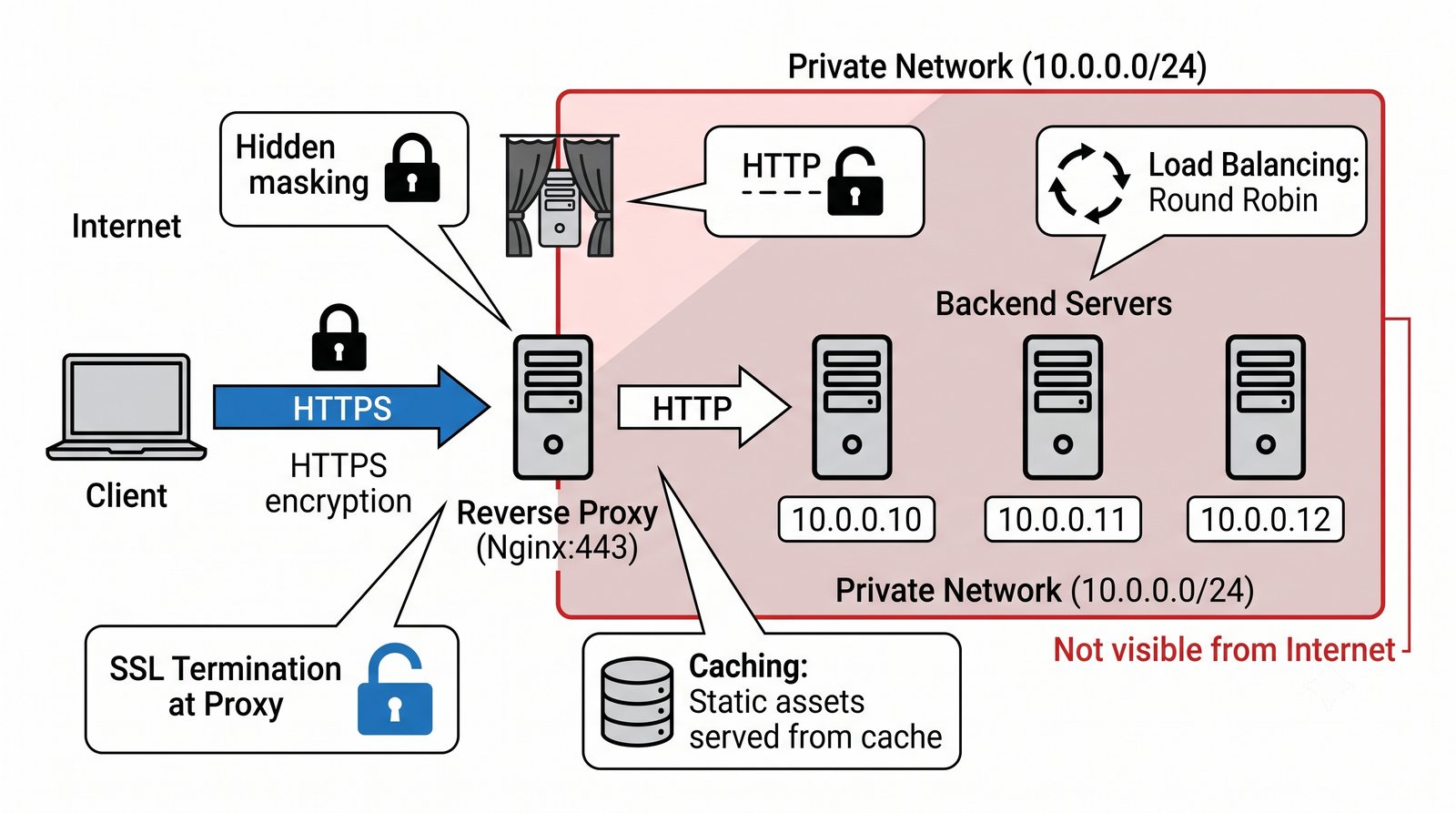
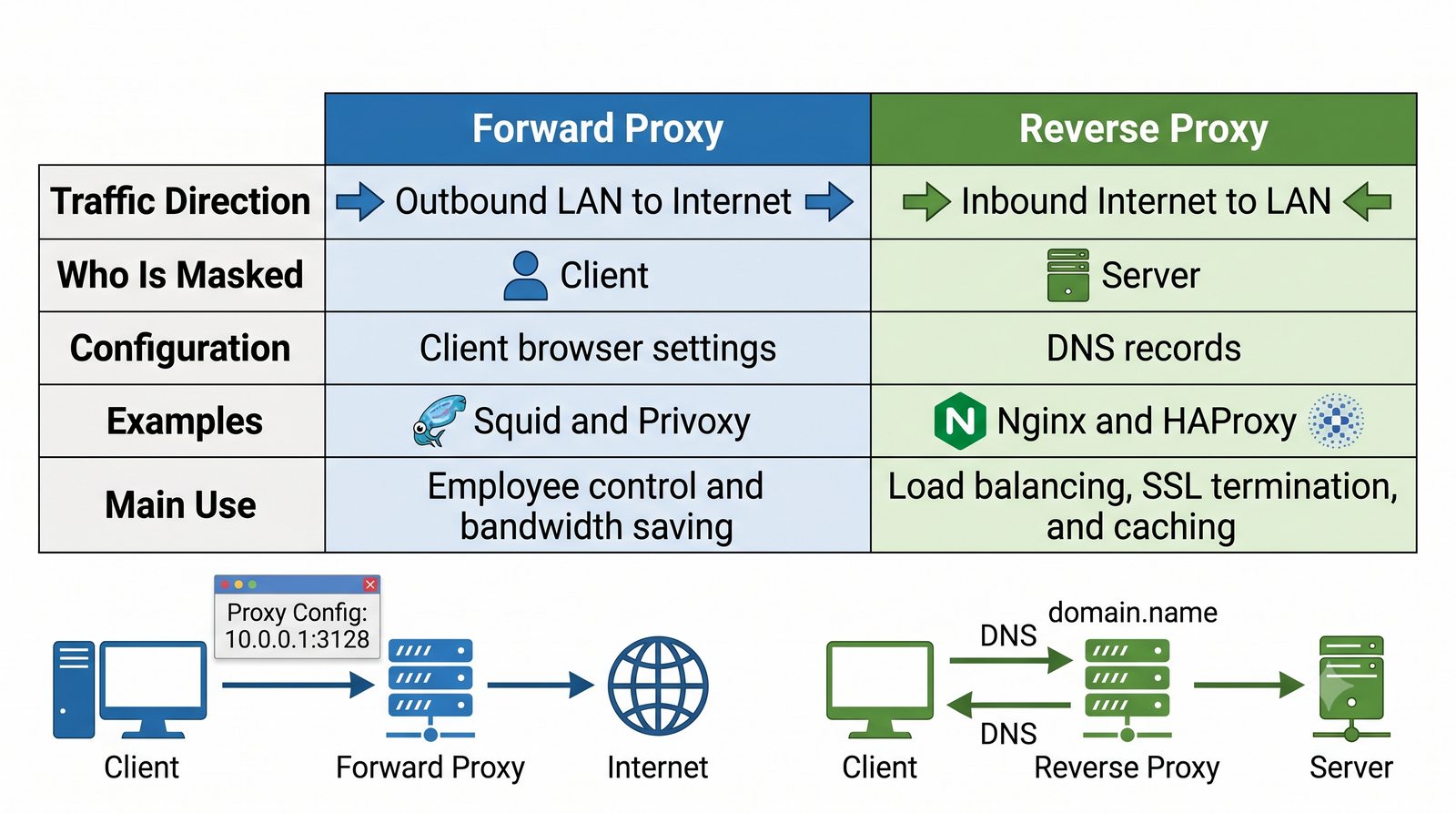
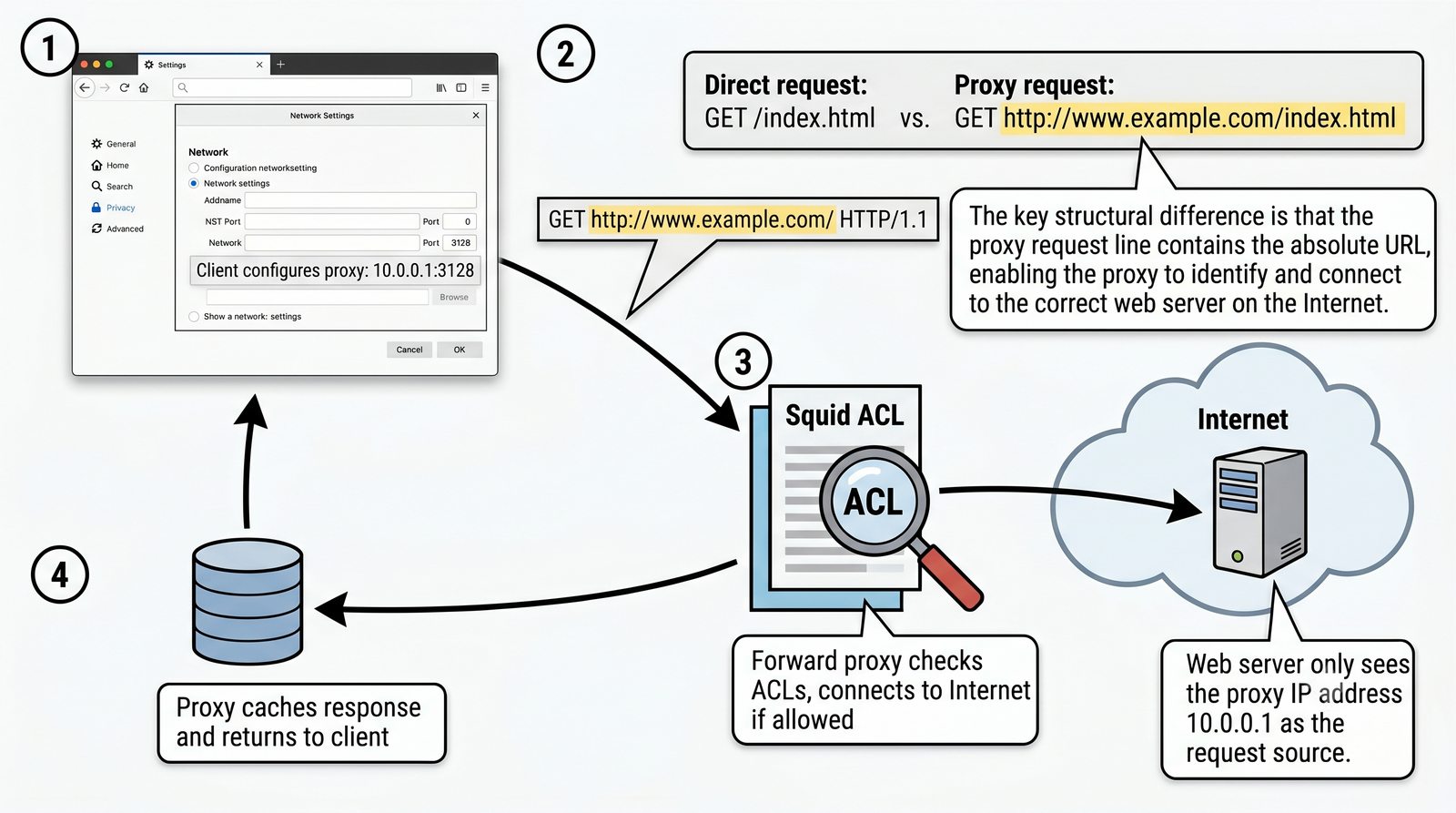
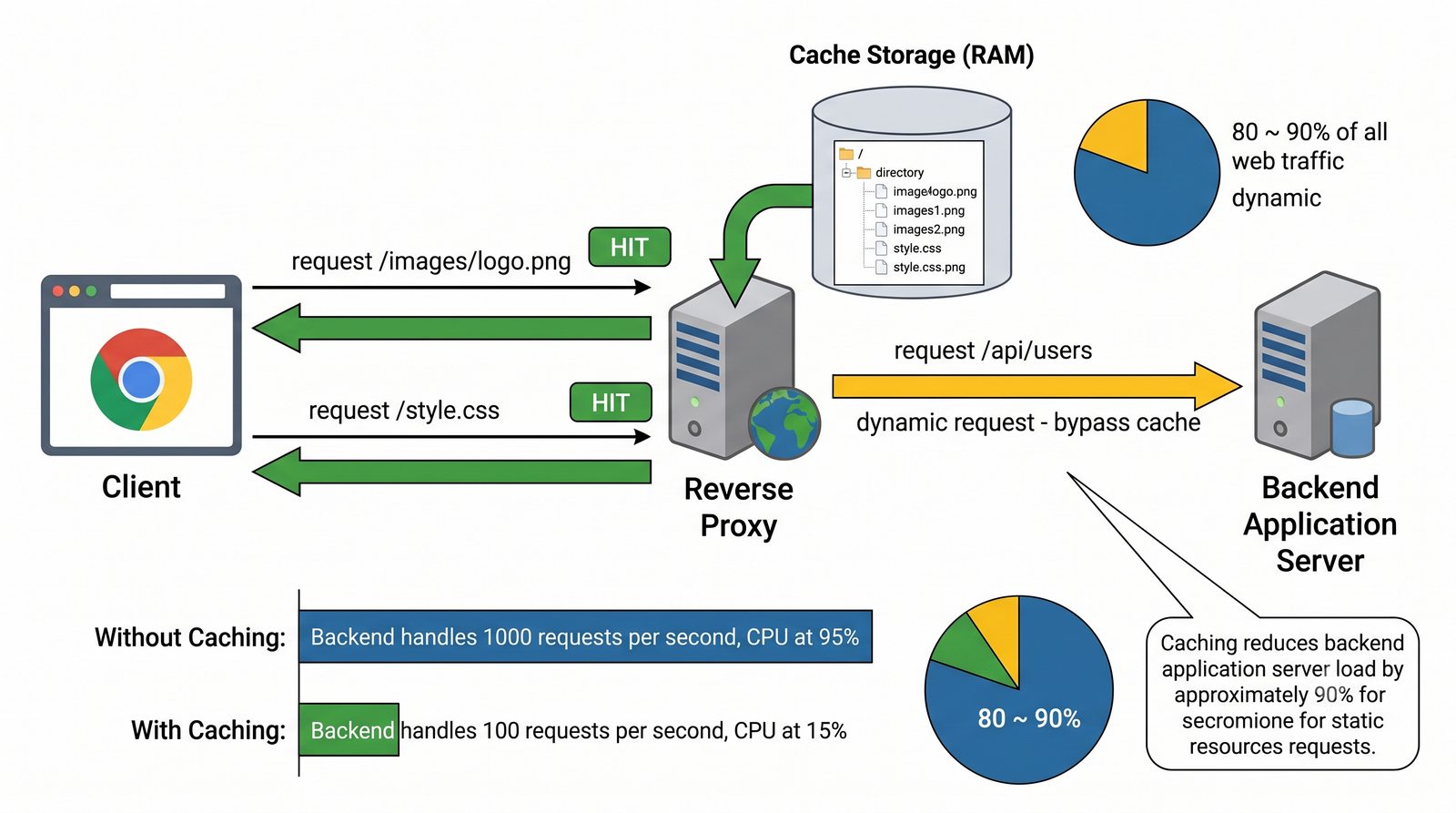
- Dwa fundamentalne typy: Forward Proxy (pośrednik wychodzący - maskowanie wyjścia, kontrola pracowników) oraz Reverse Proxy (pośrednik odwrotny - maskowanie wejścia, odciążenie serwerów WWW)
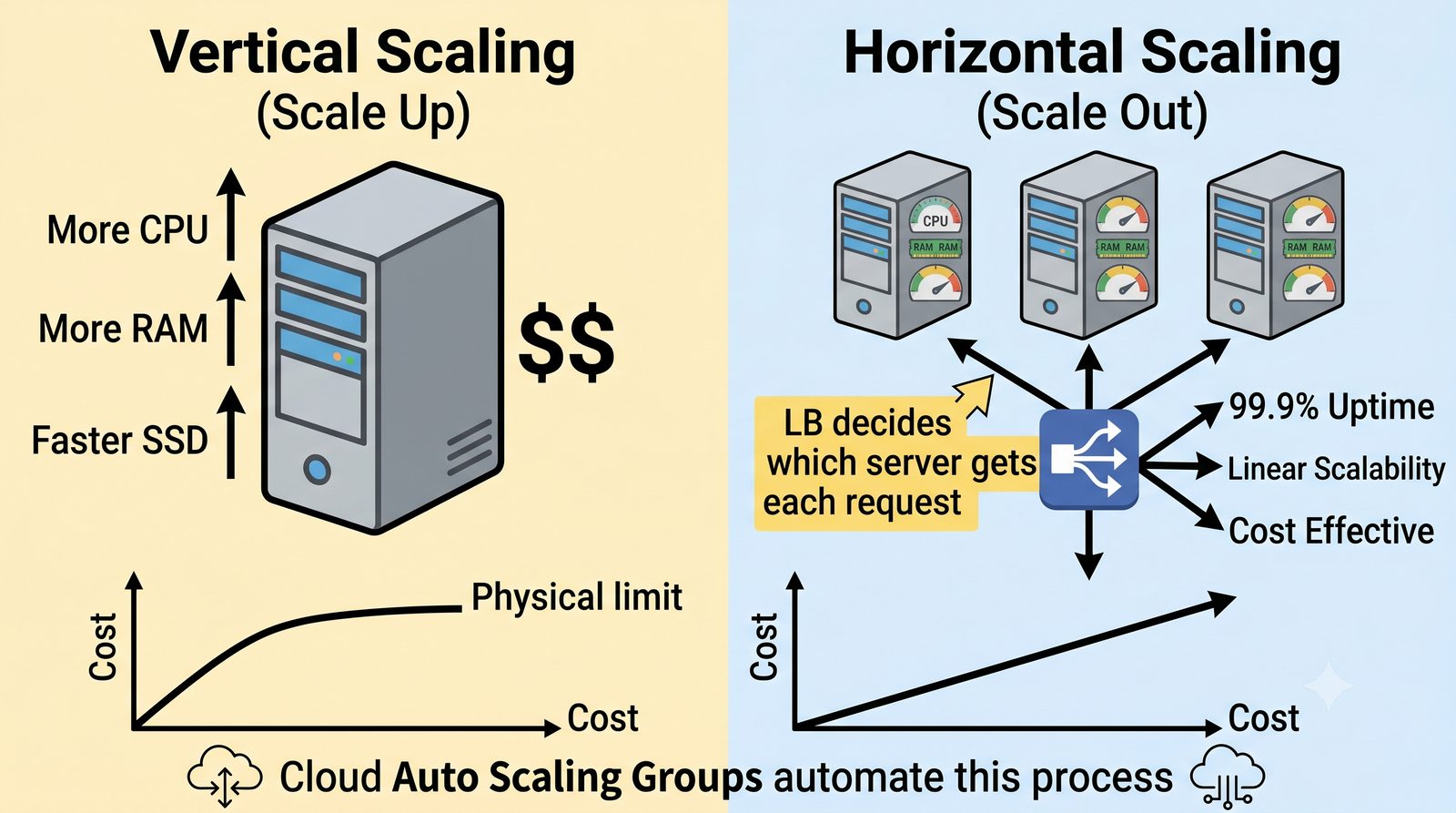
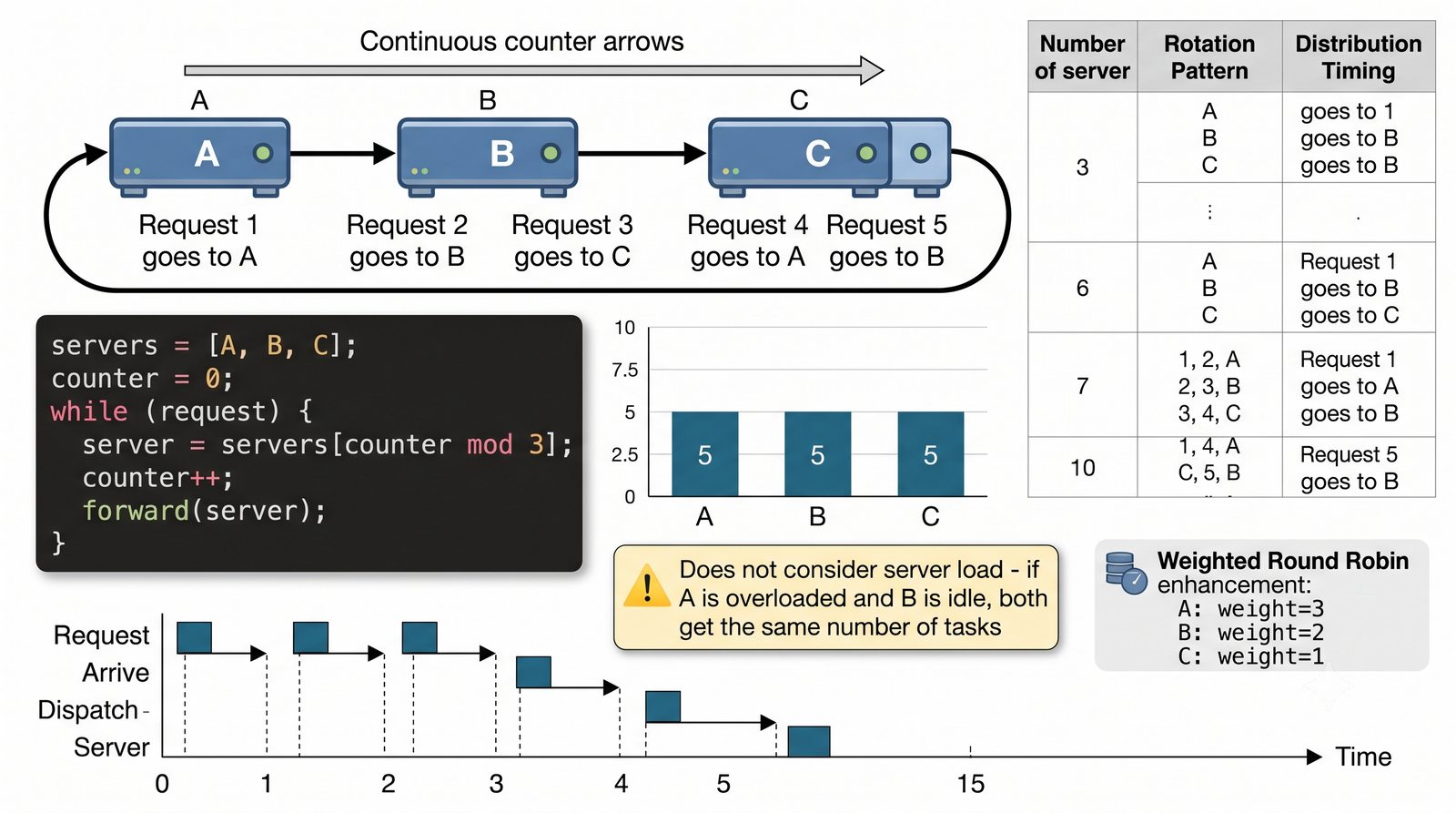
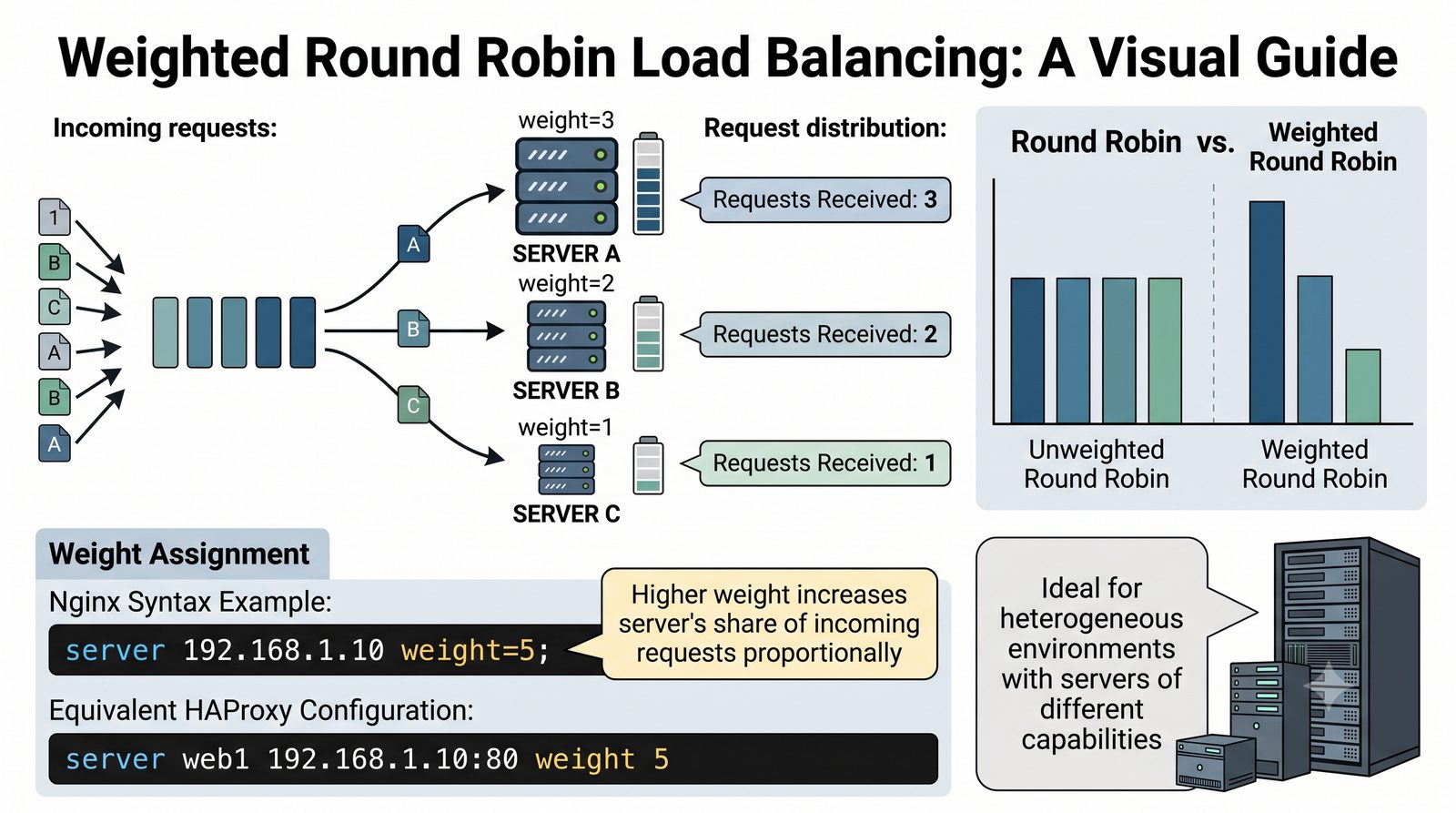
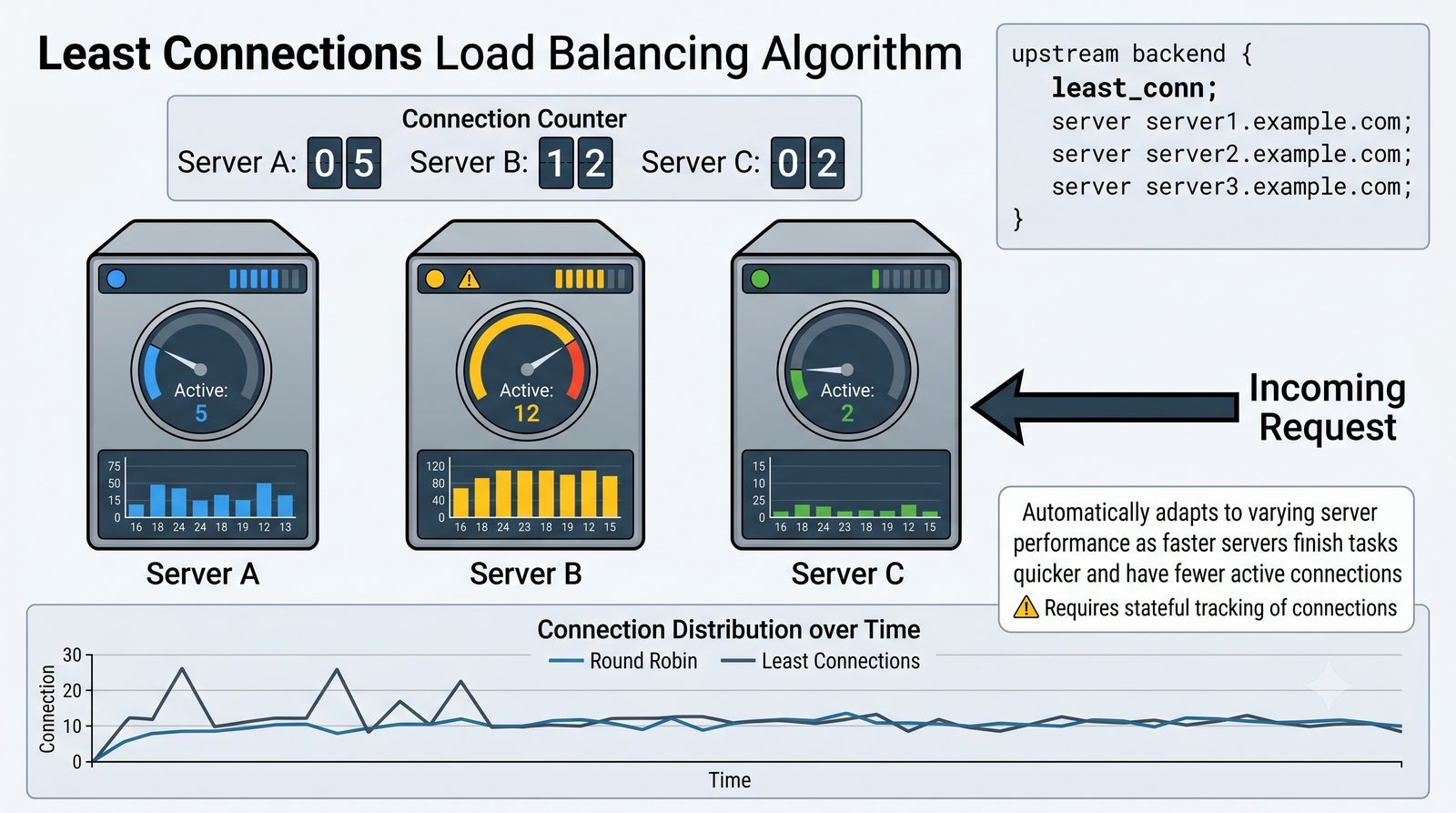
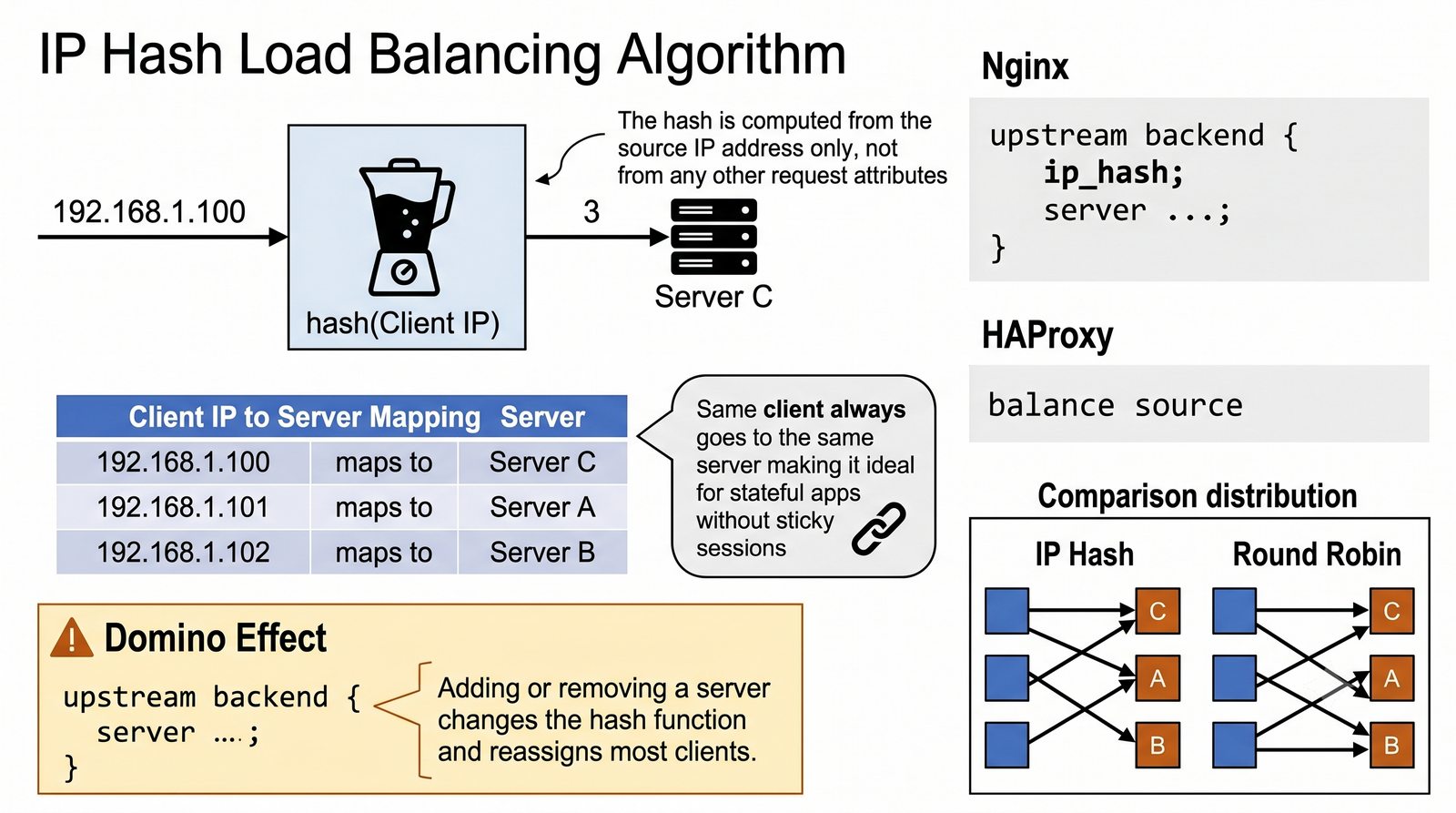
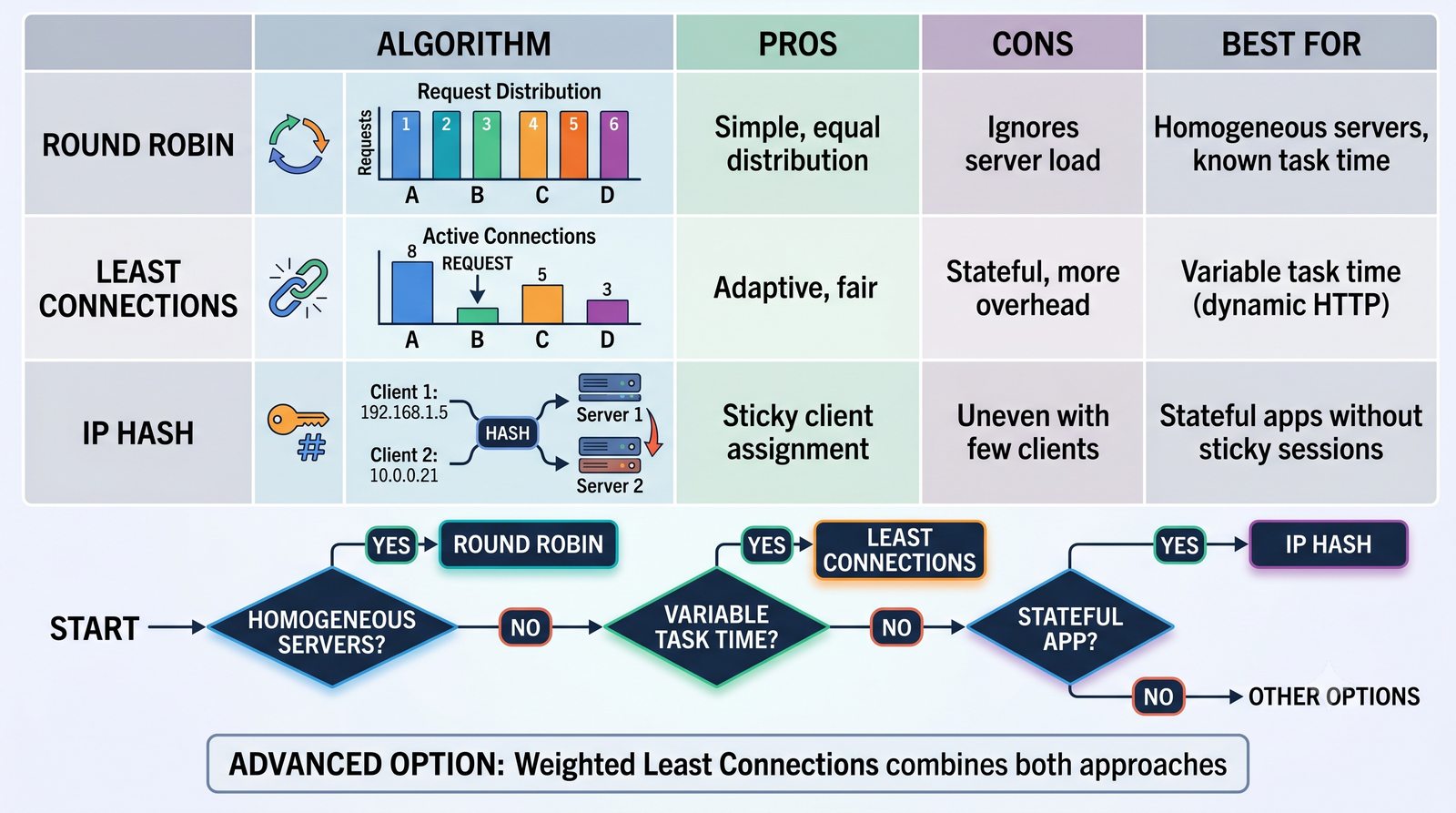
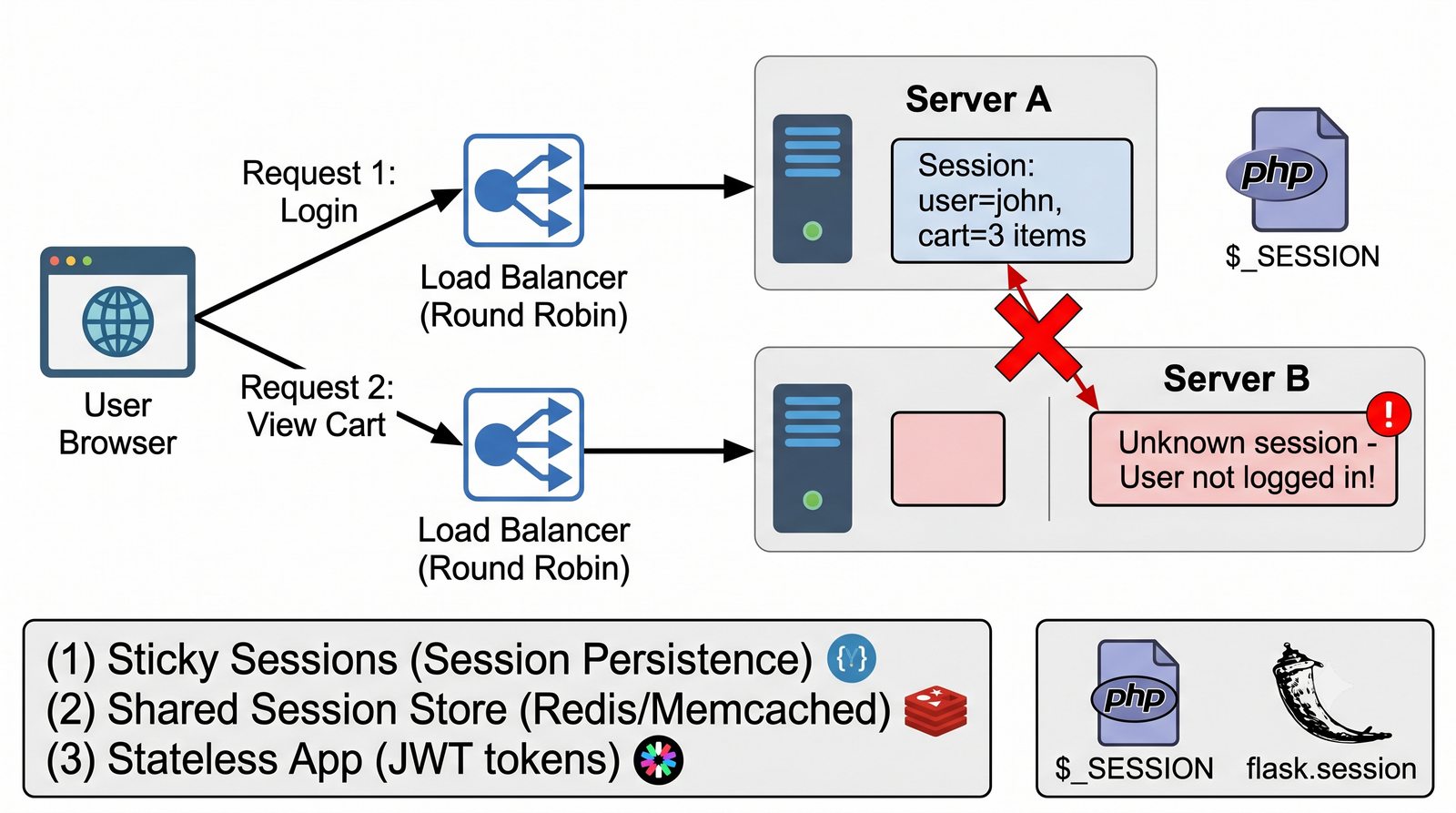
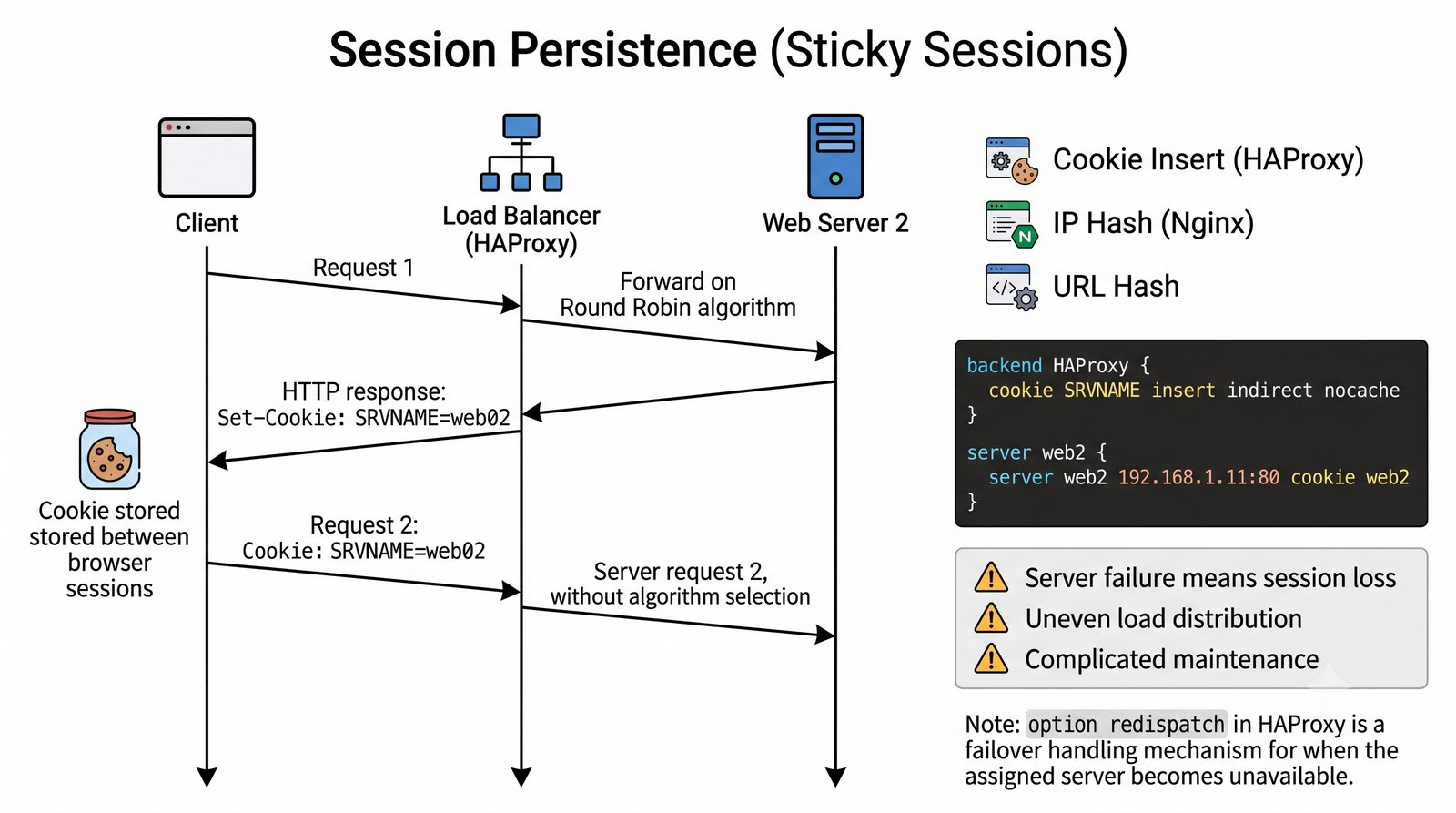
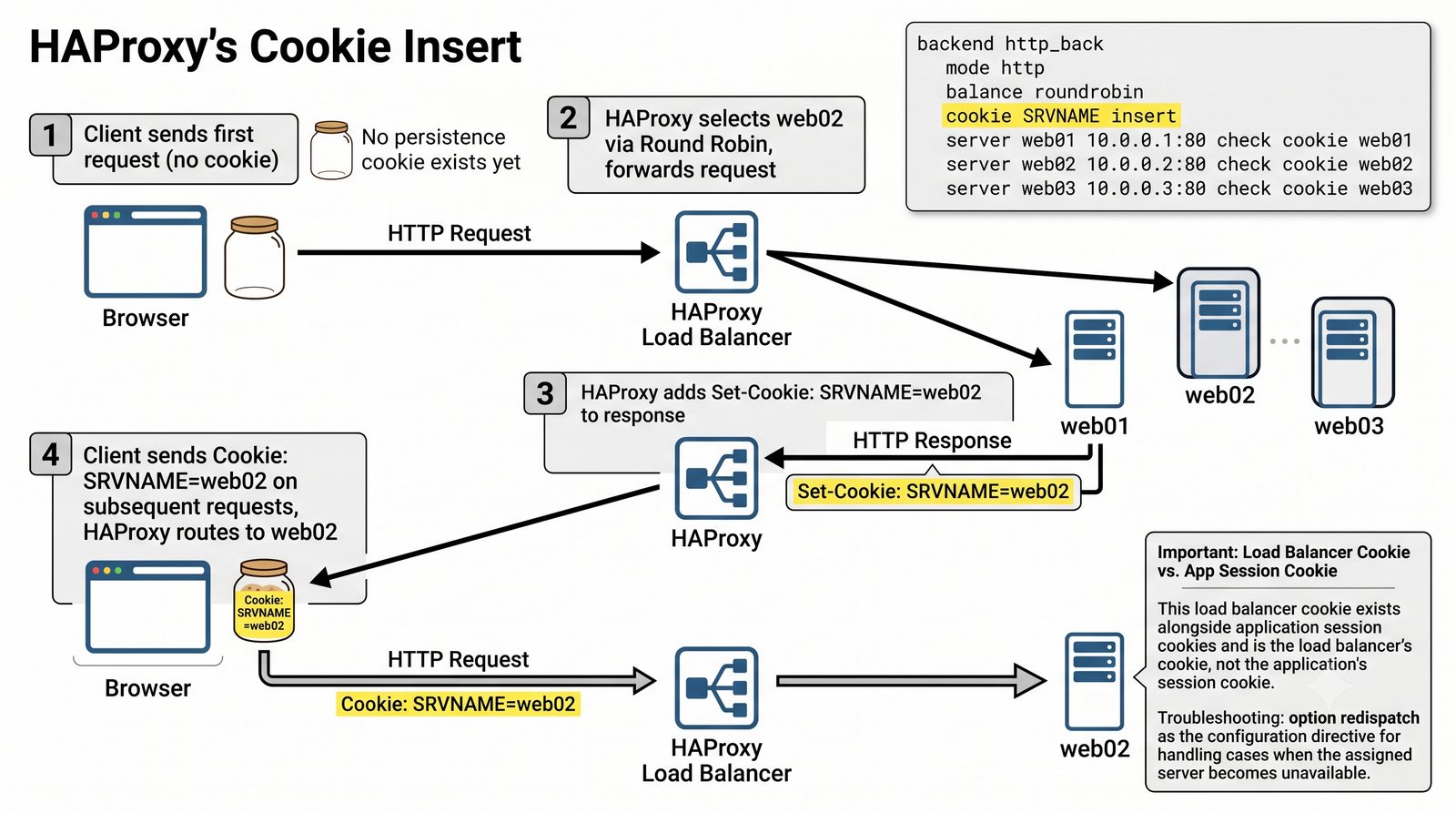
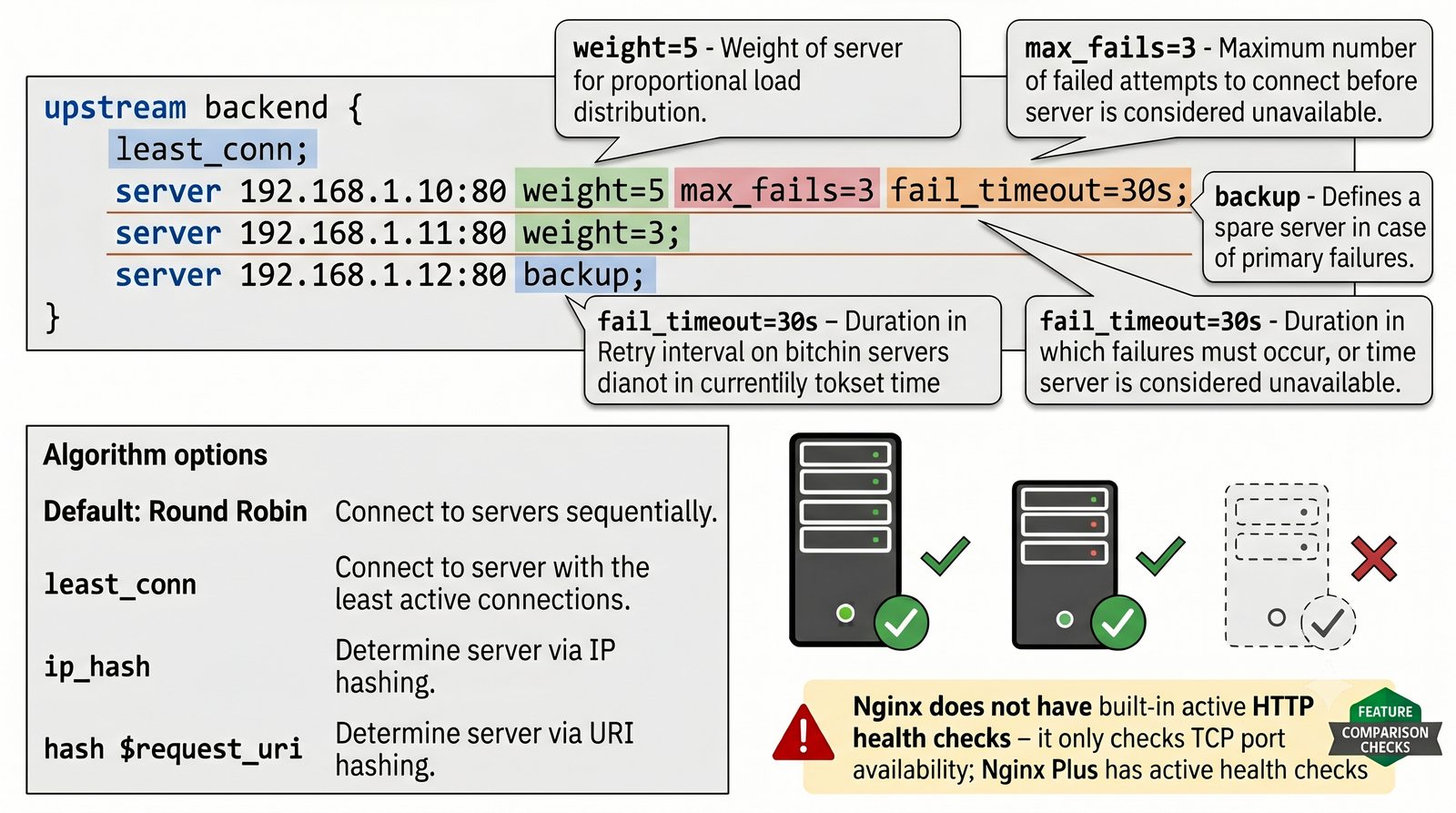
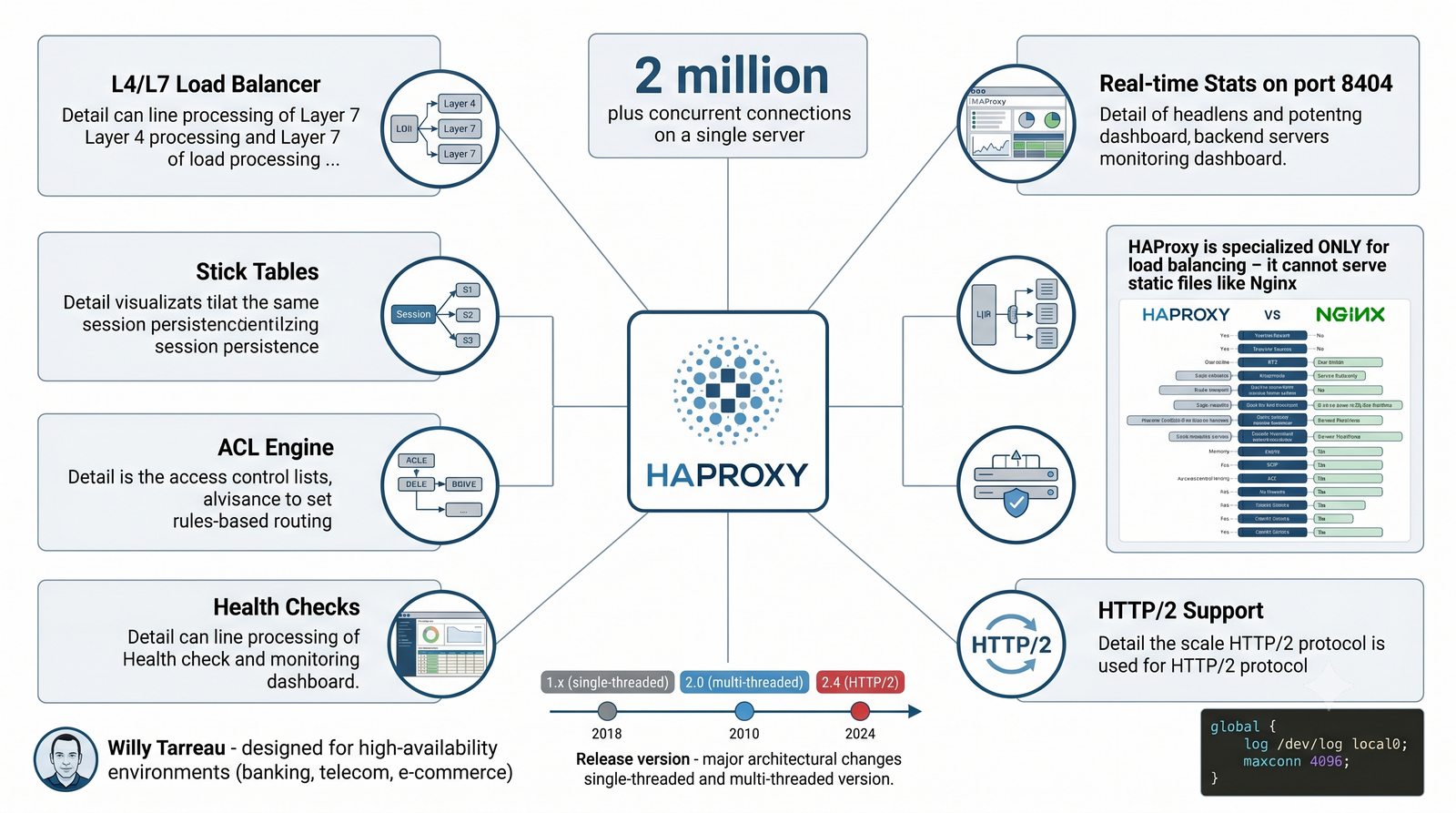
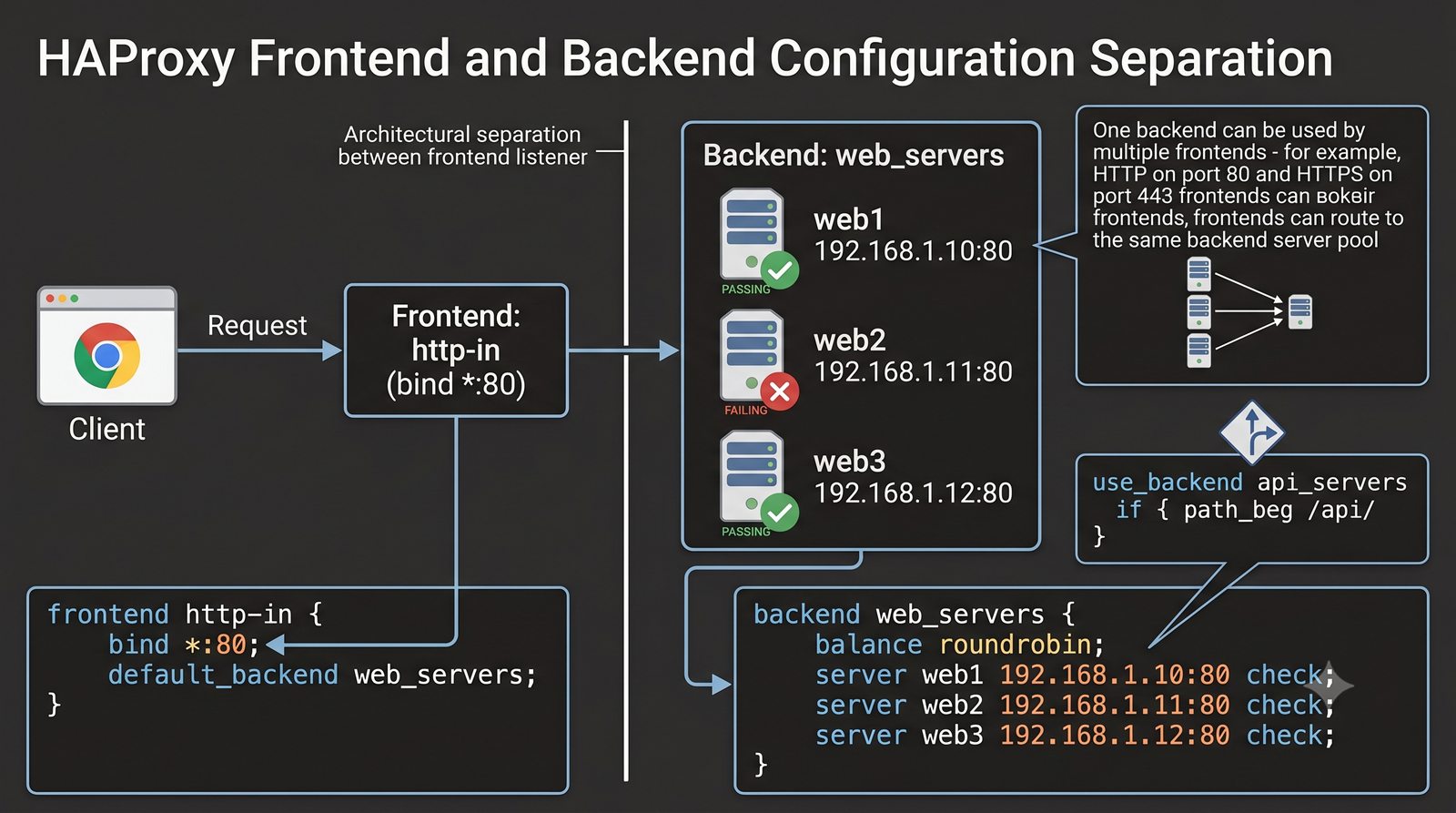
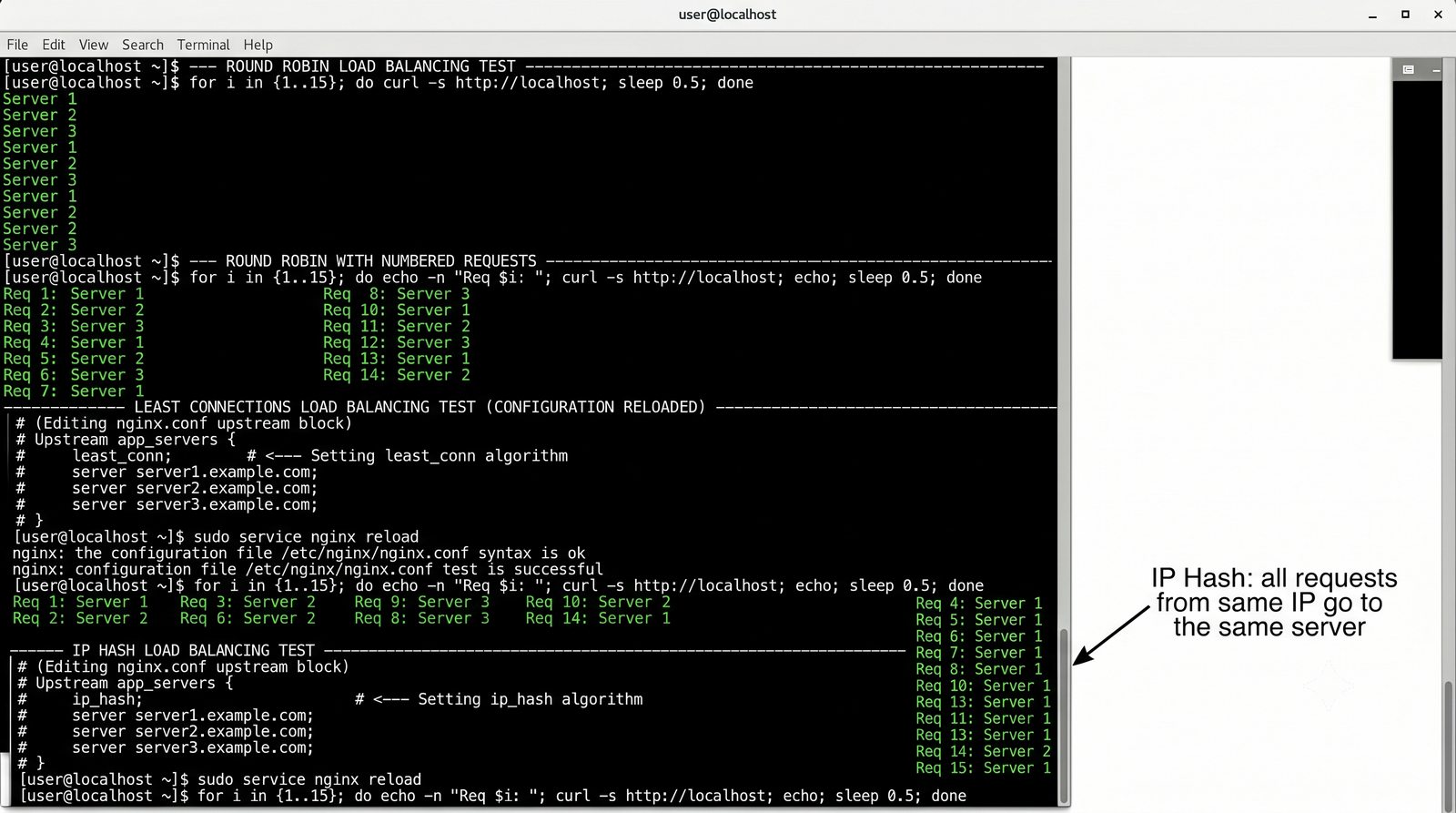
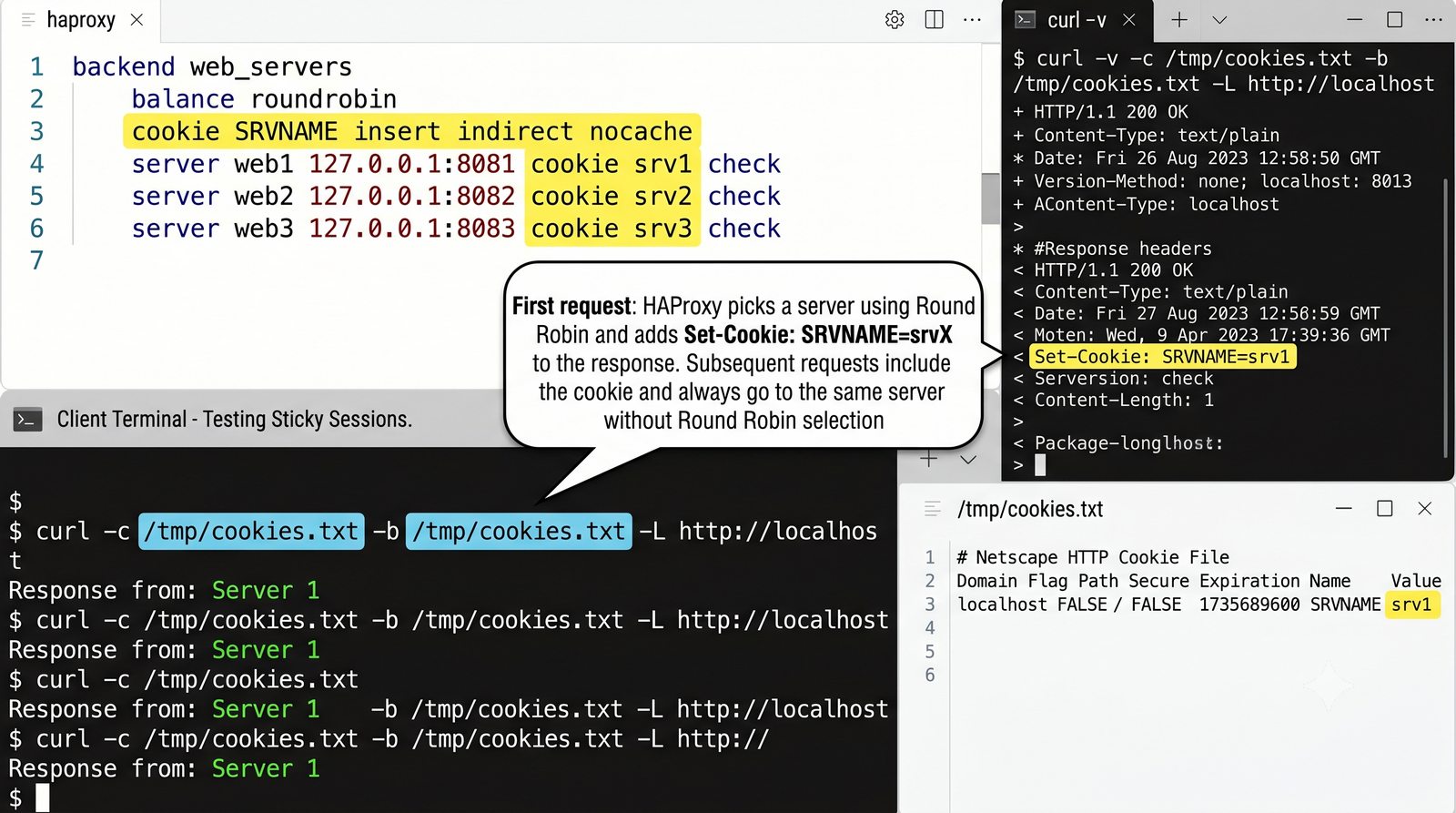
- Prezentacja obejmuje algorytmy load balancingu (Round Robin, Least Connections, IP Hash), mechanizmy session persistence oraz caching na warstwie proxy
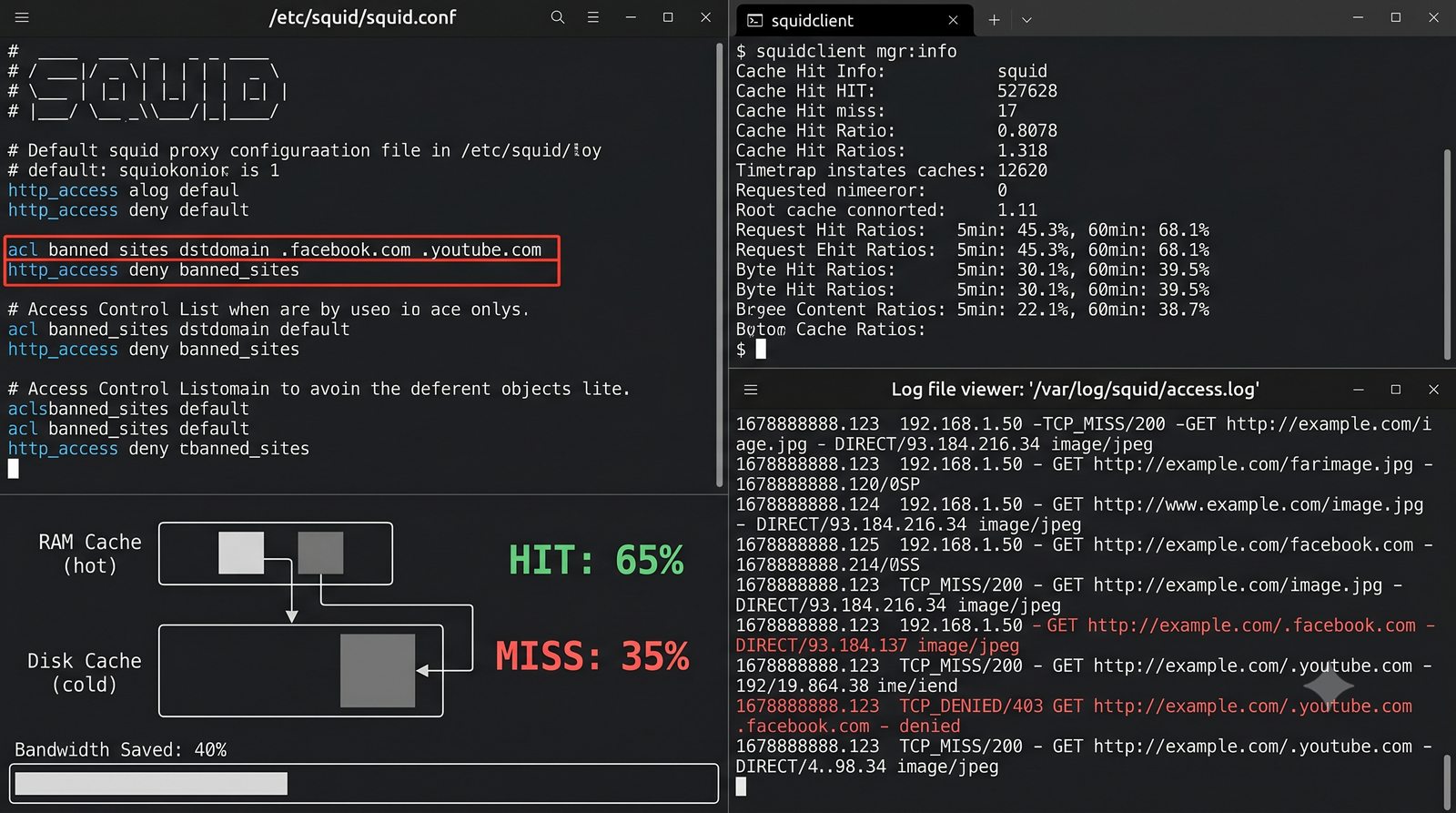
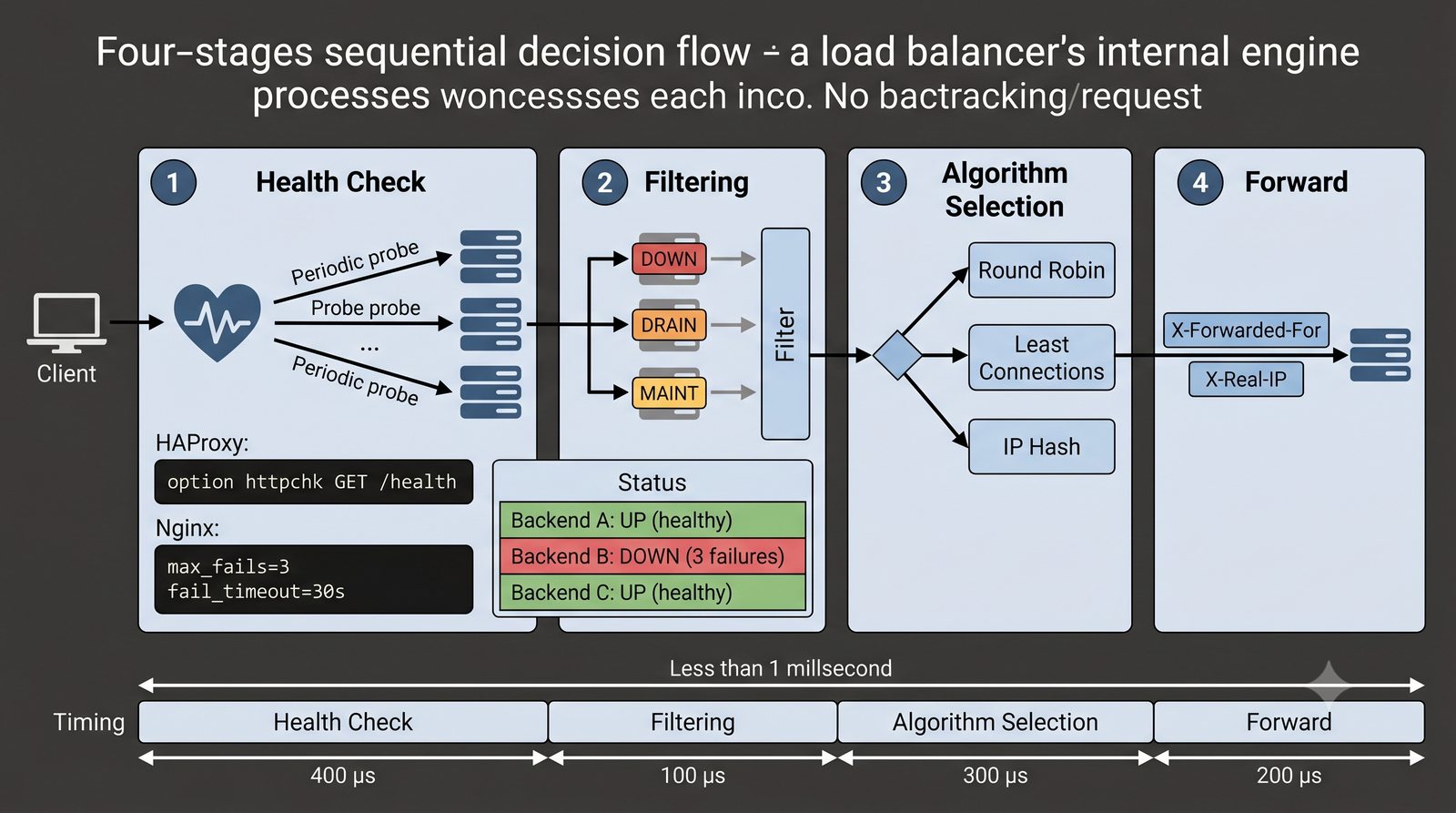
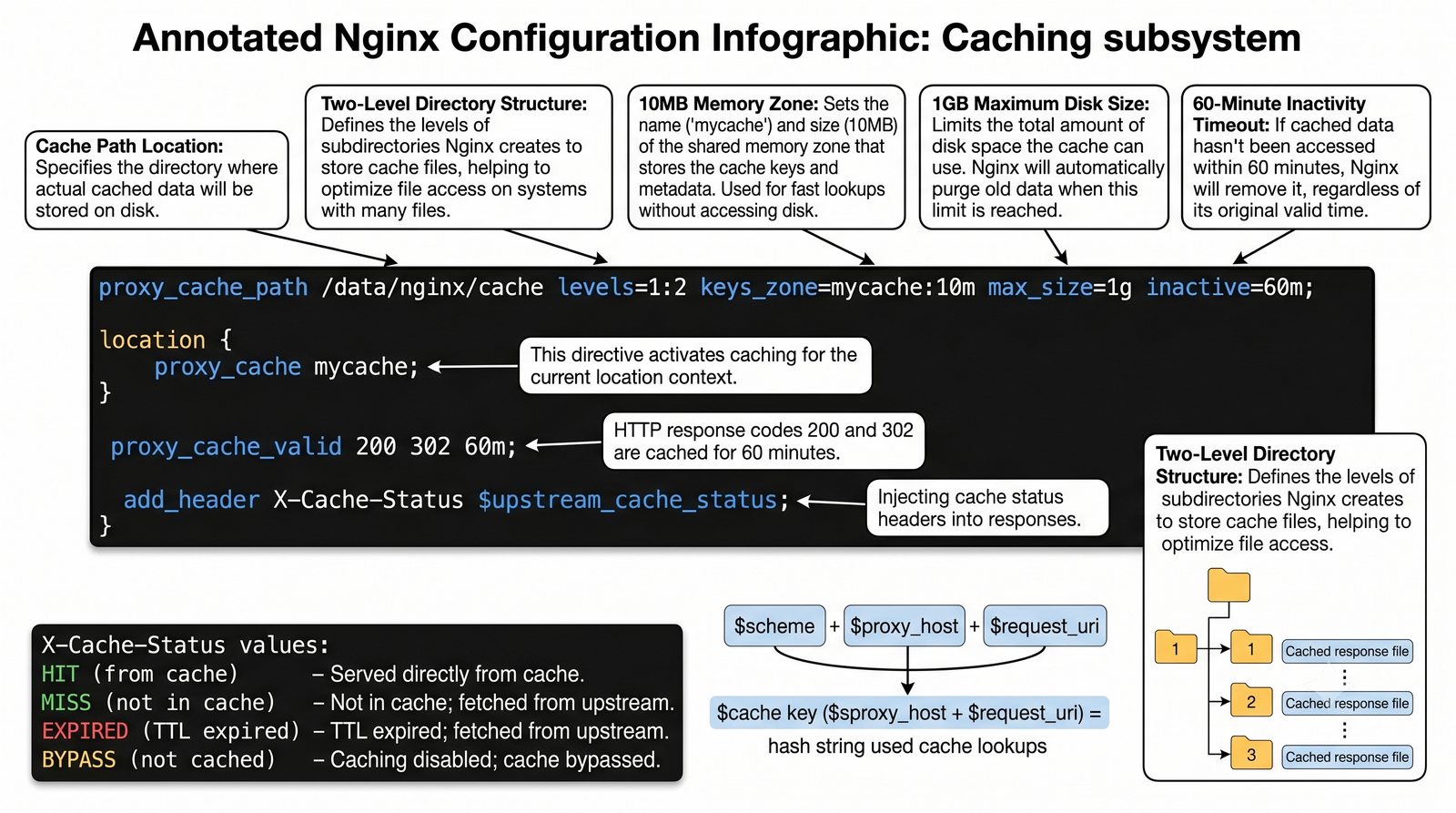
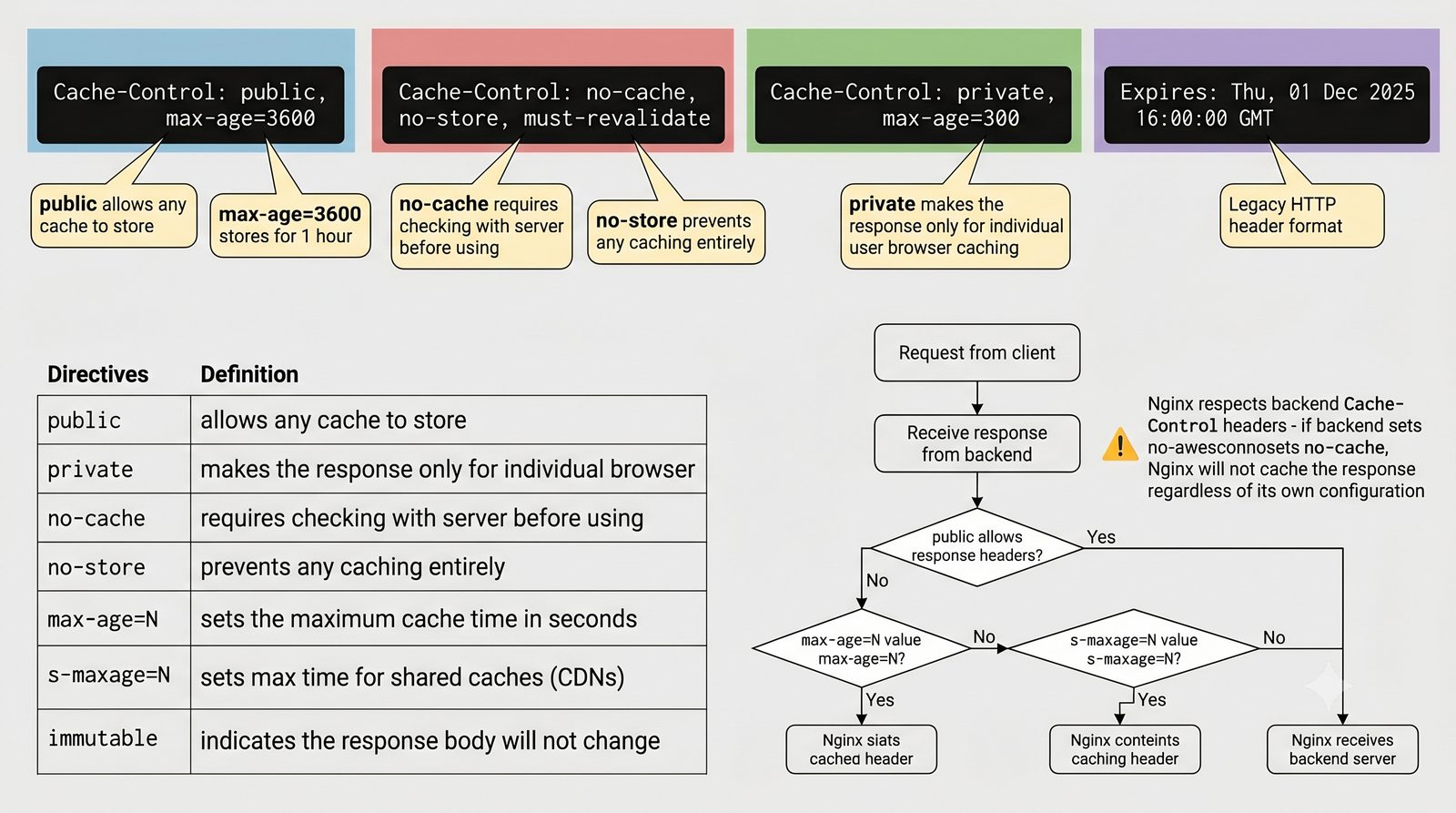
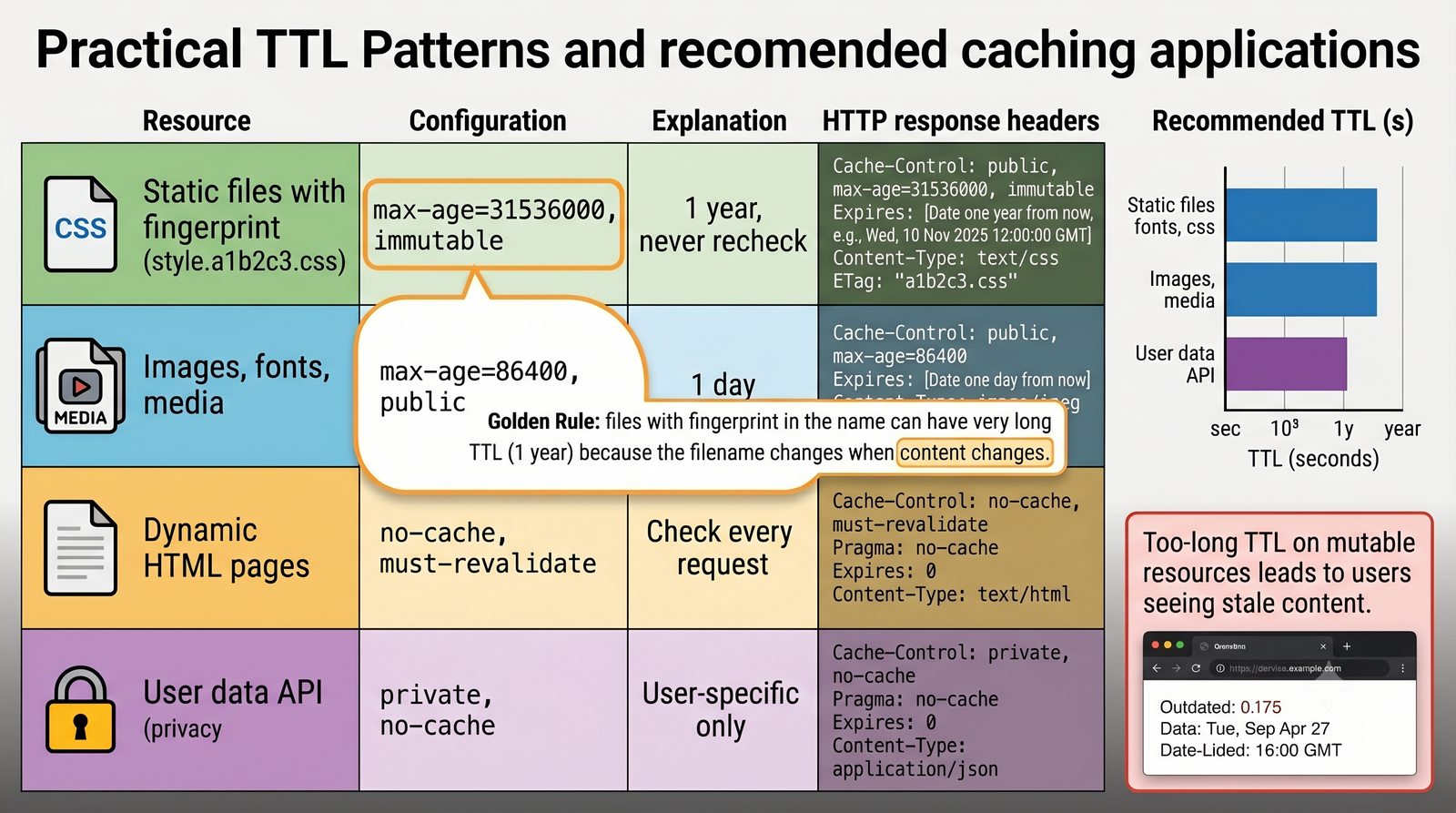
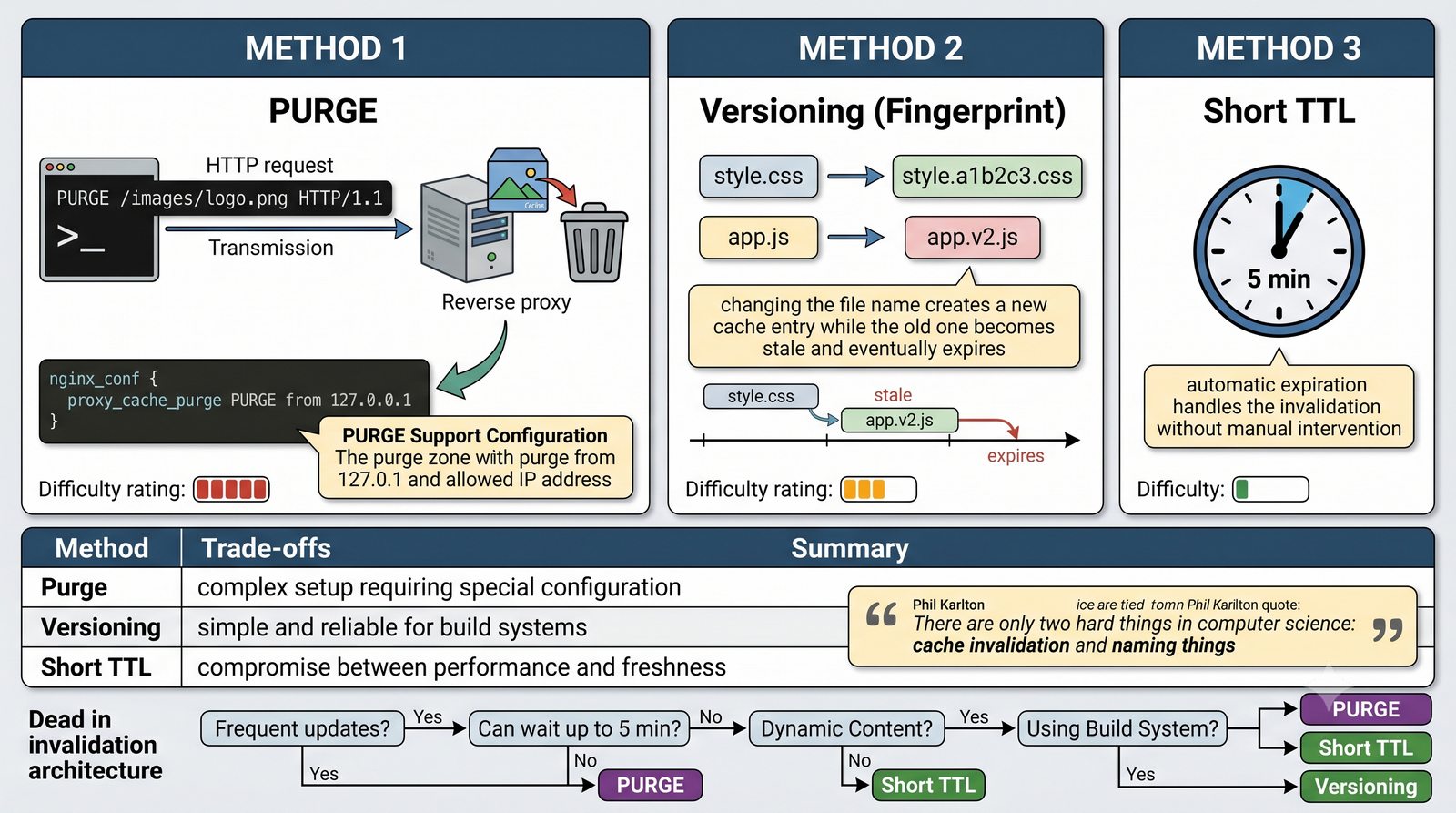
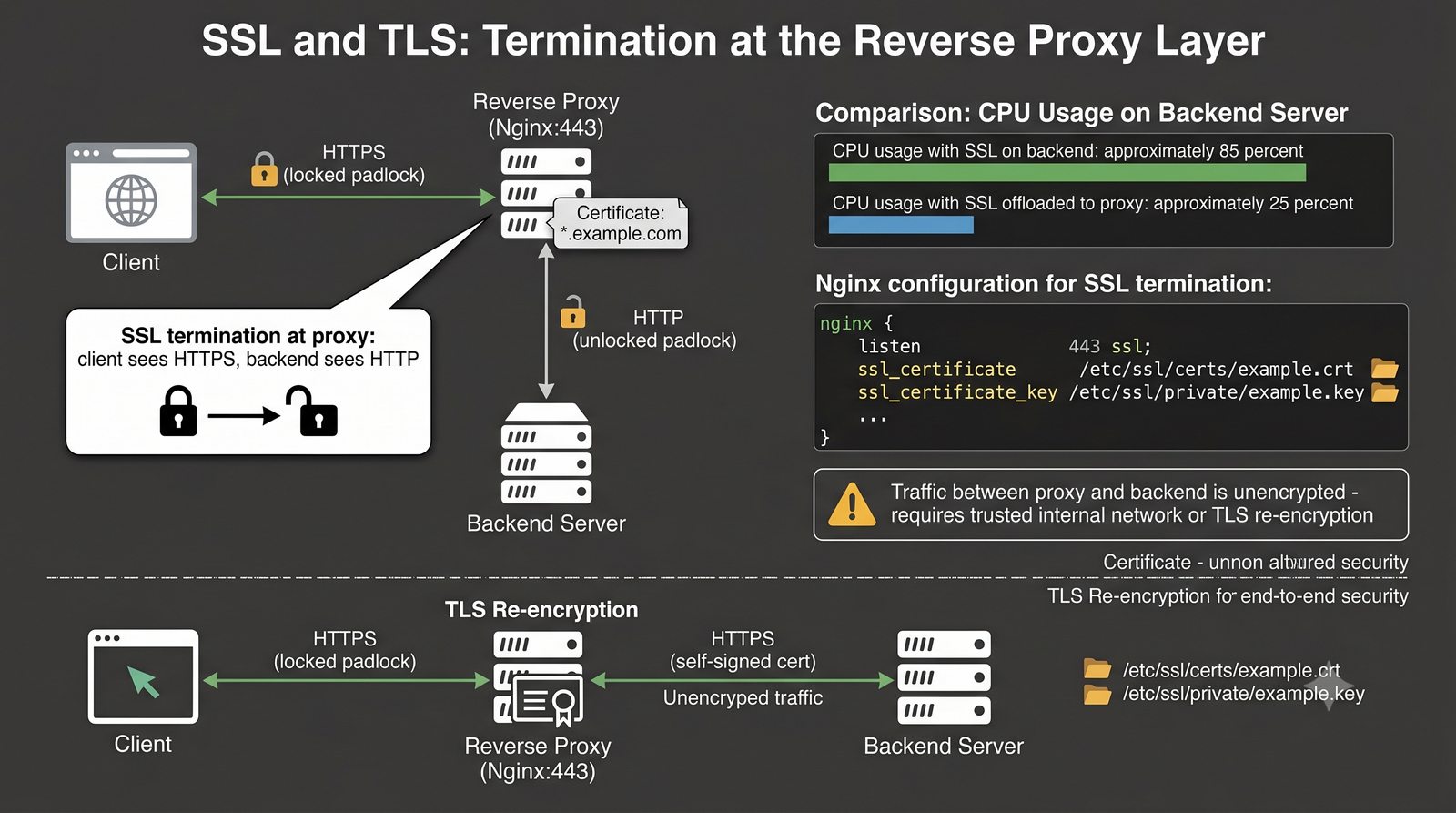
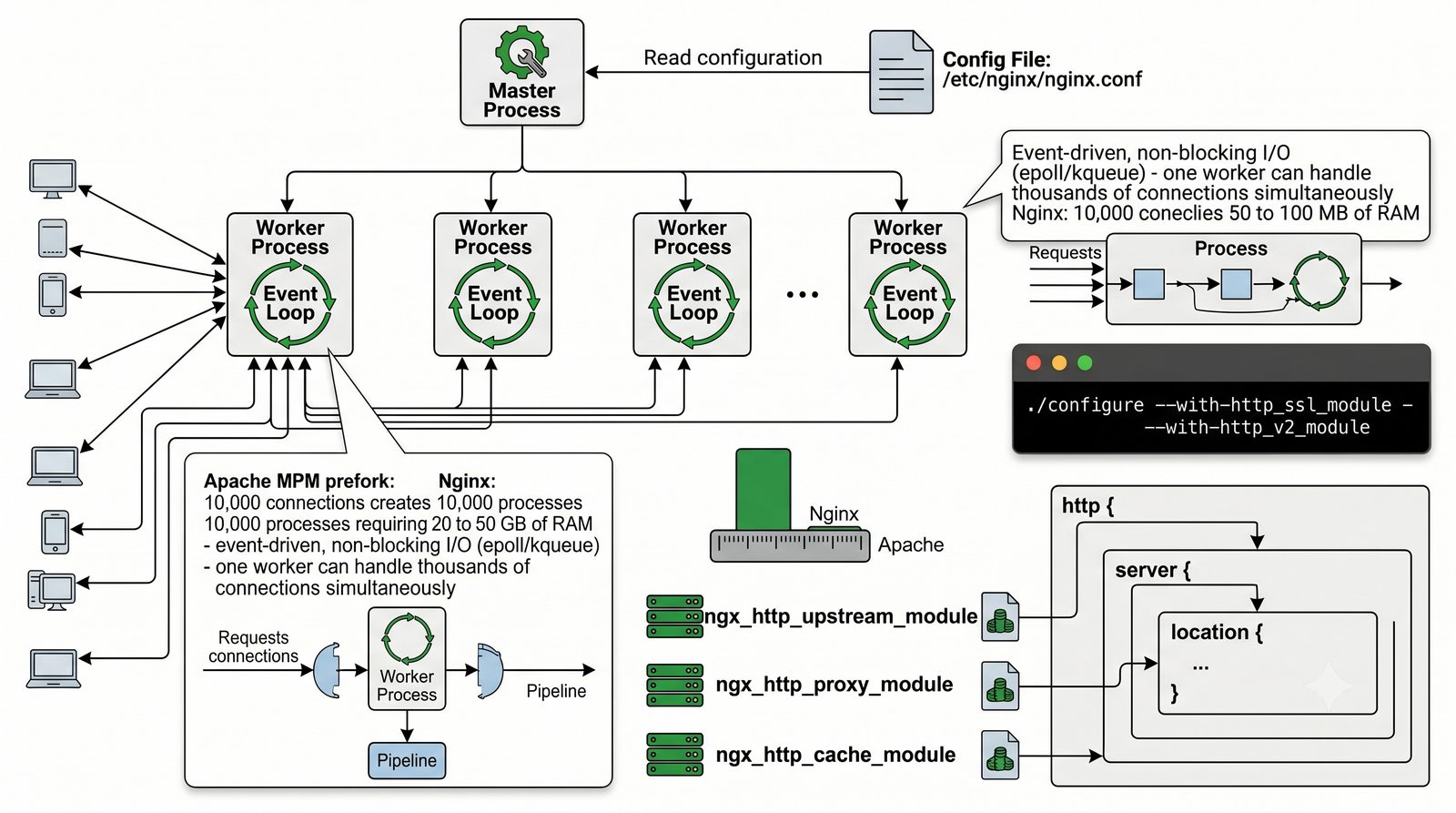
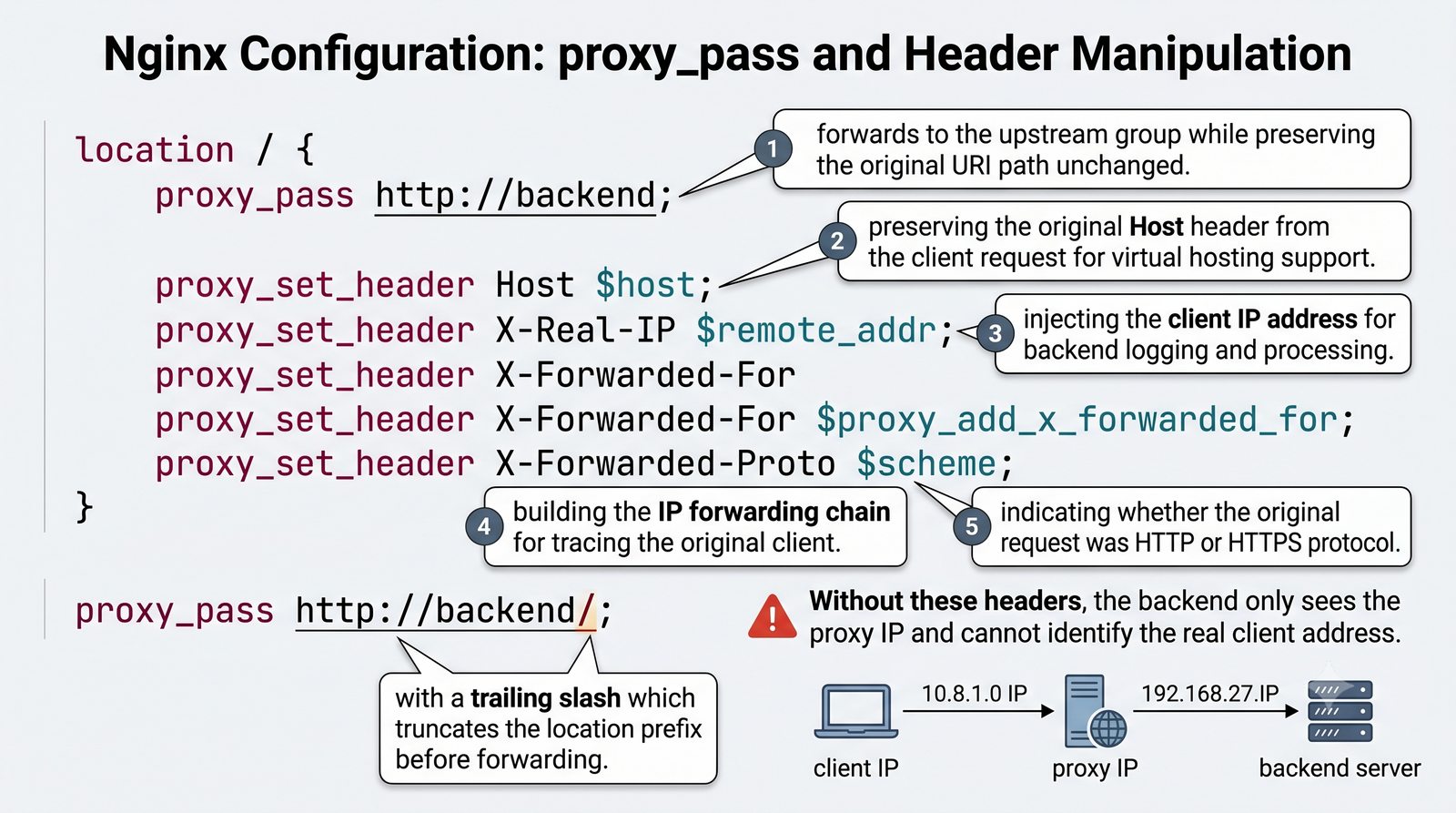
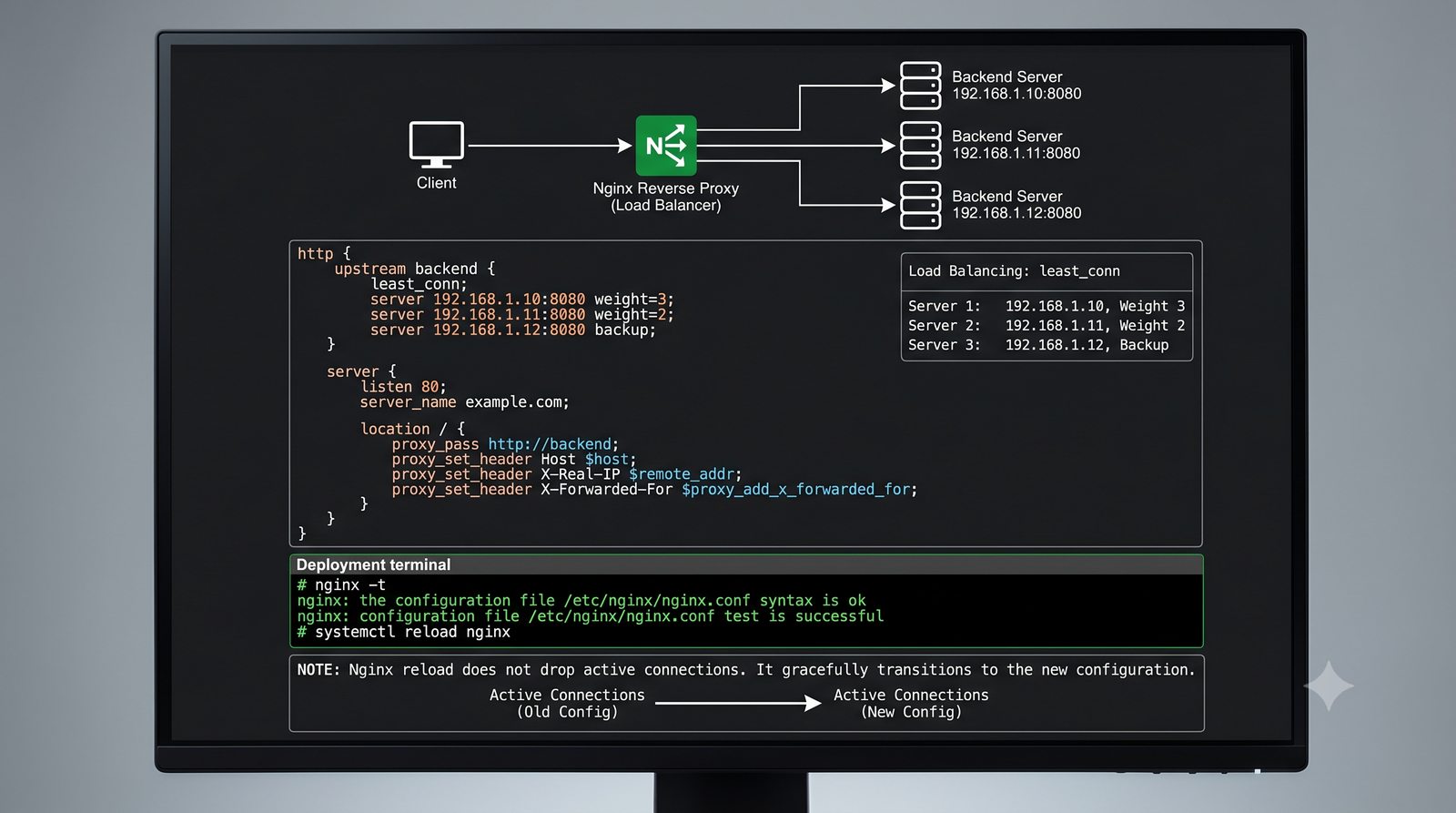
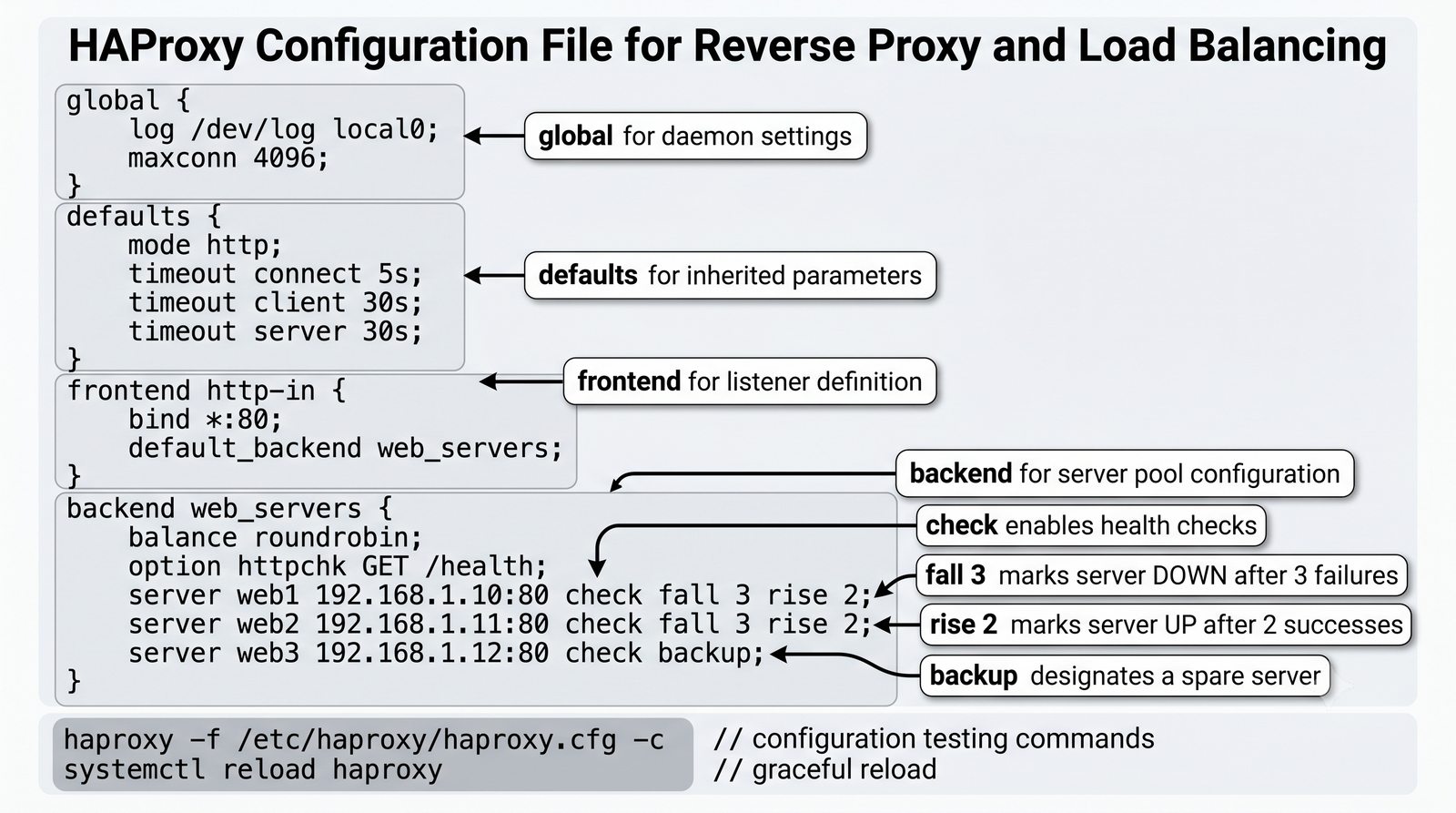
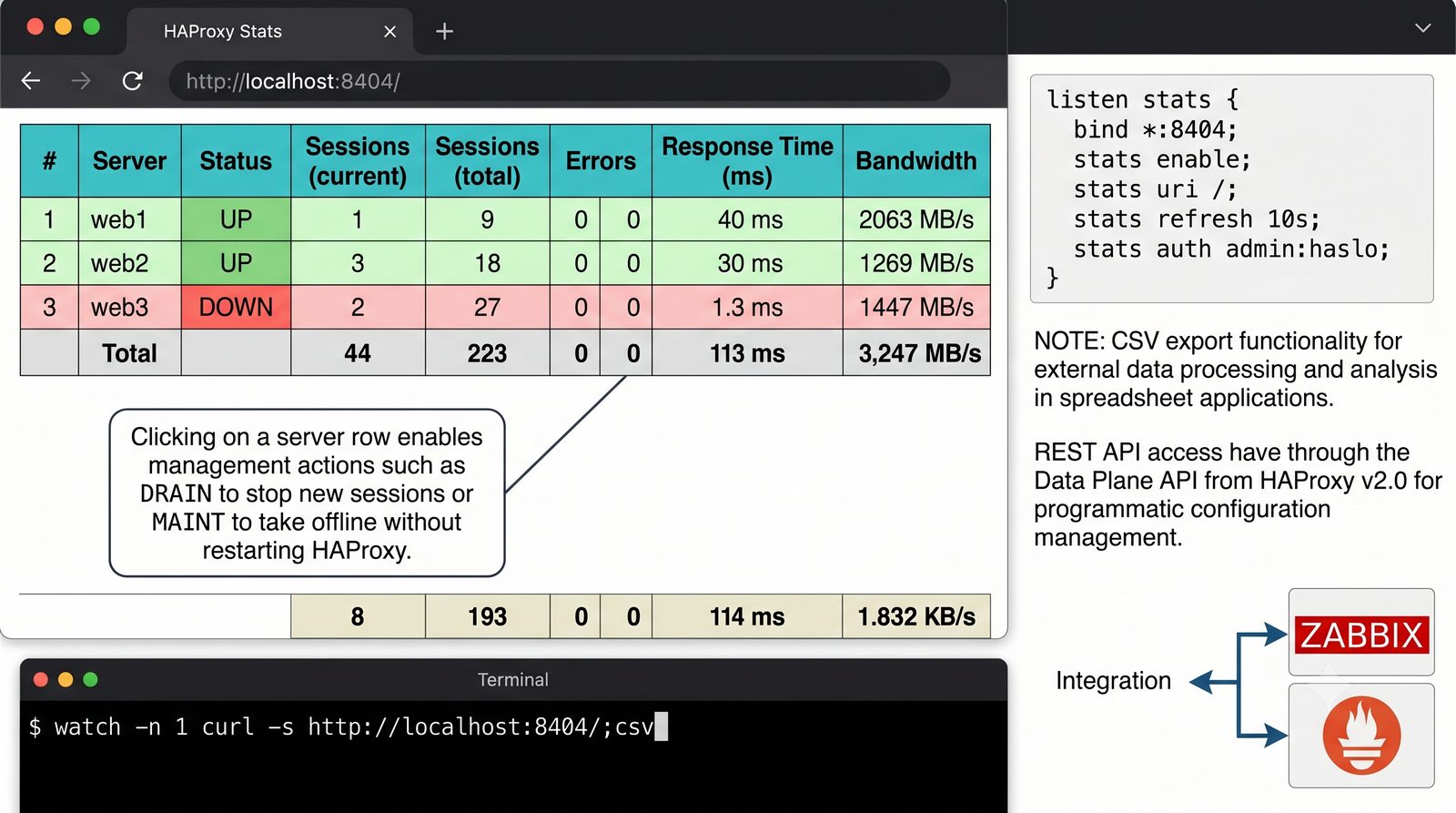
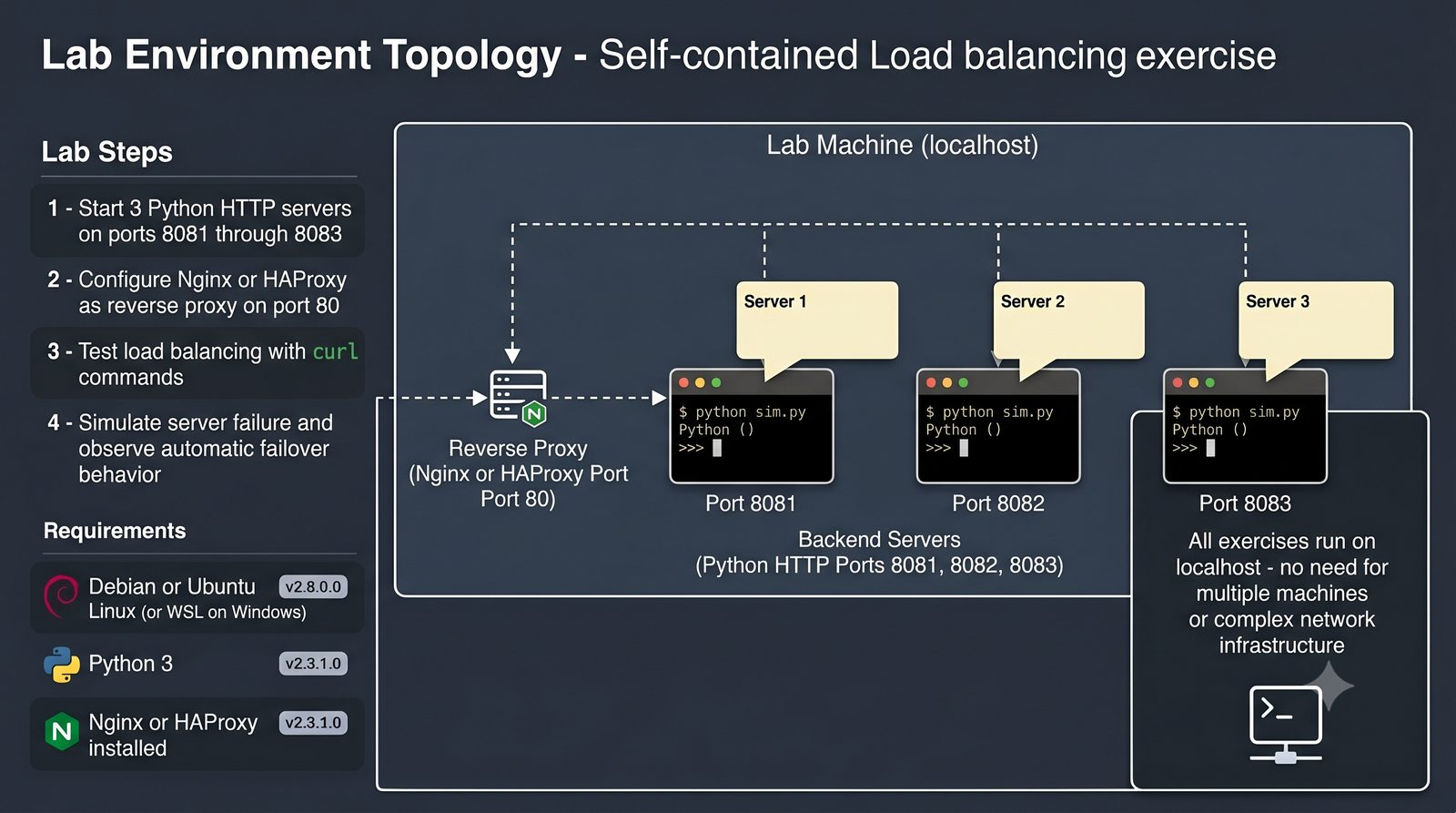
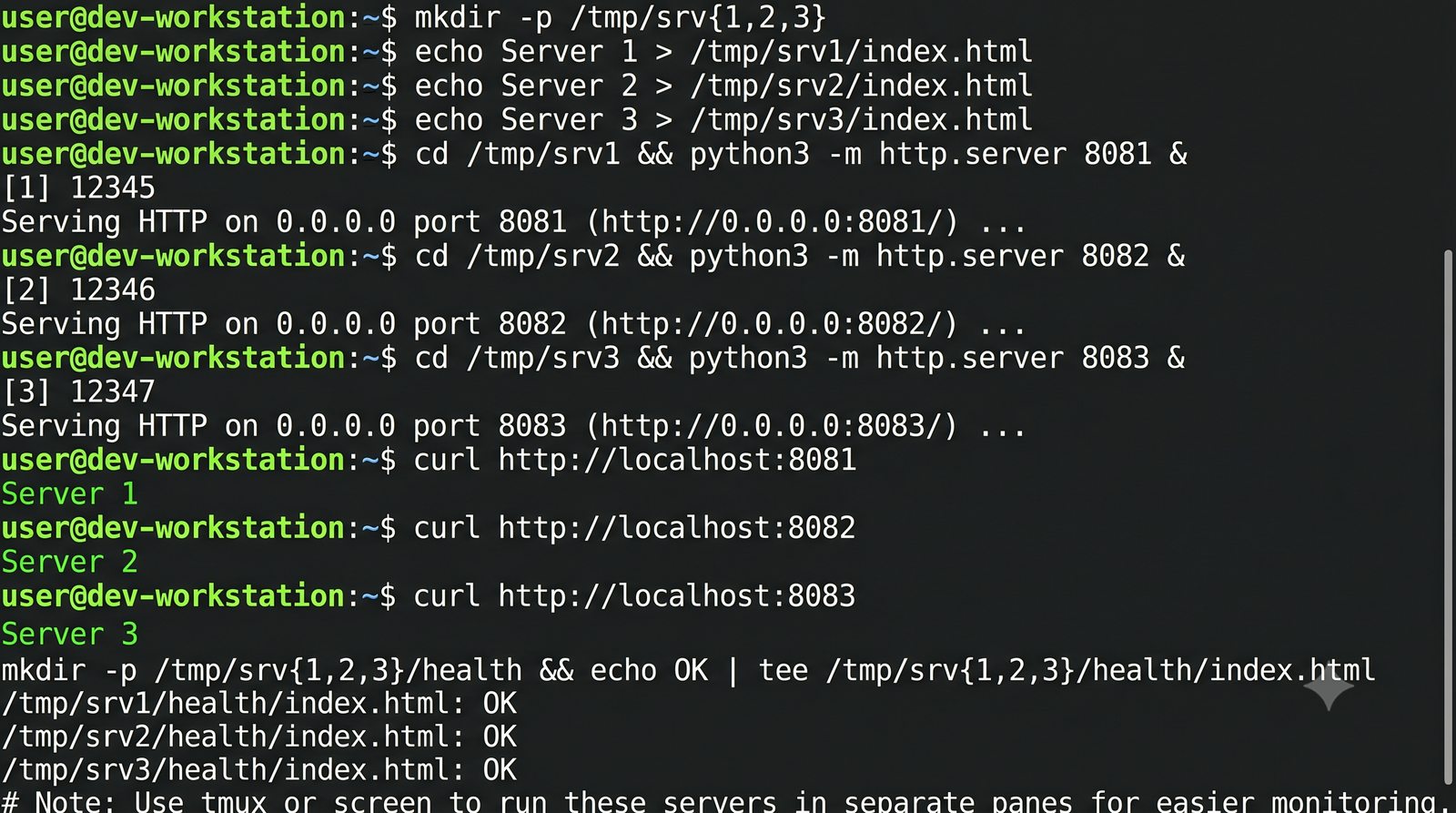
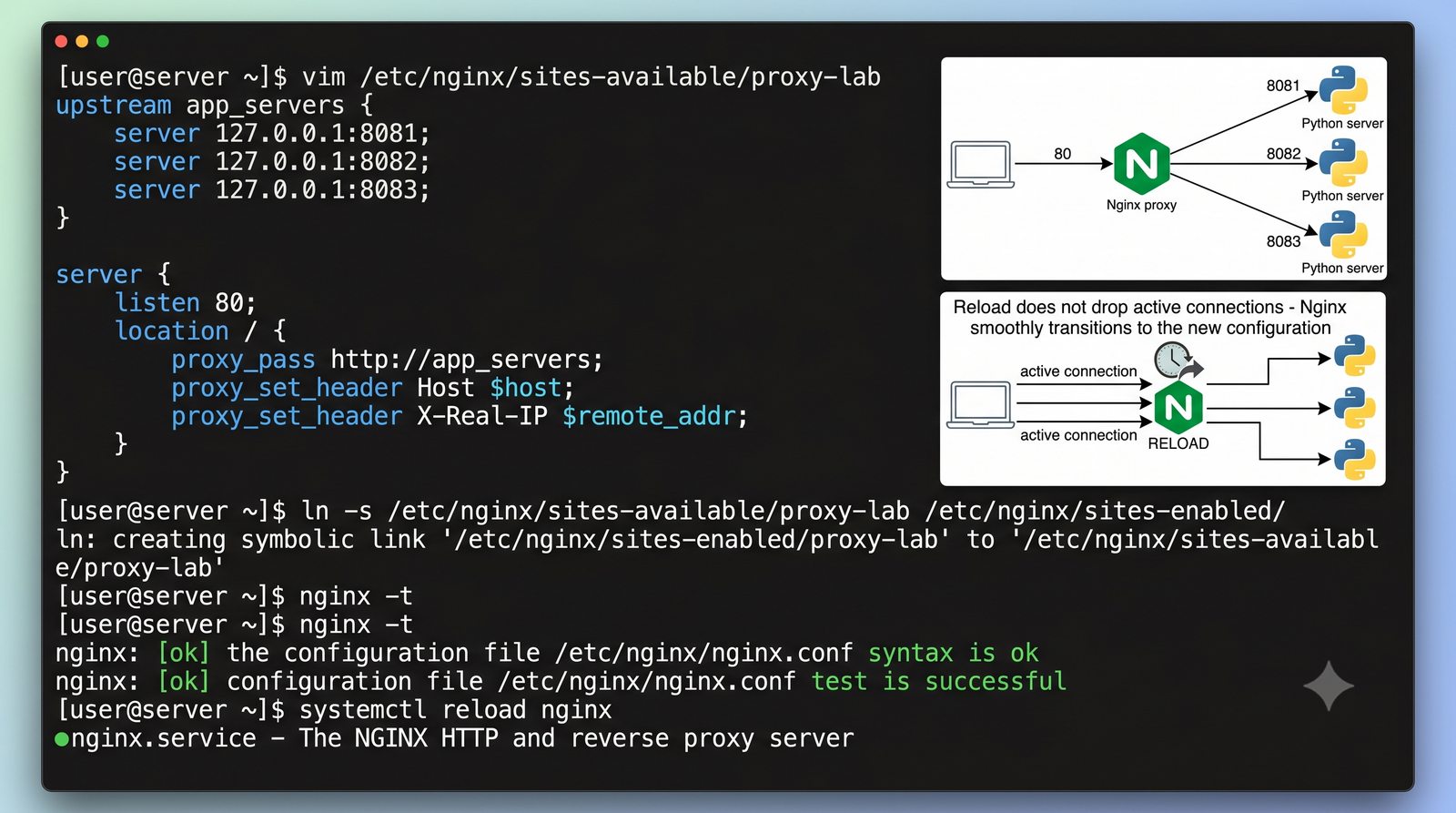
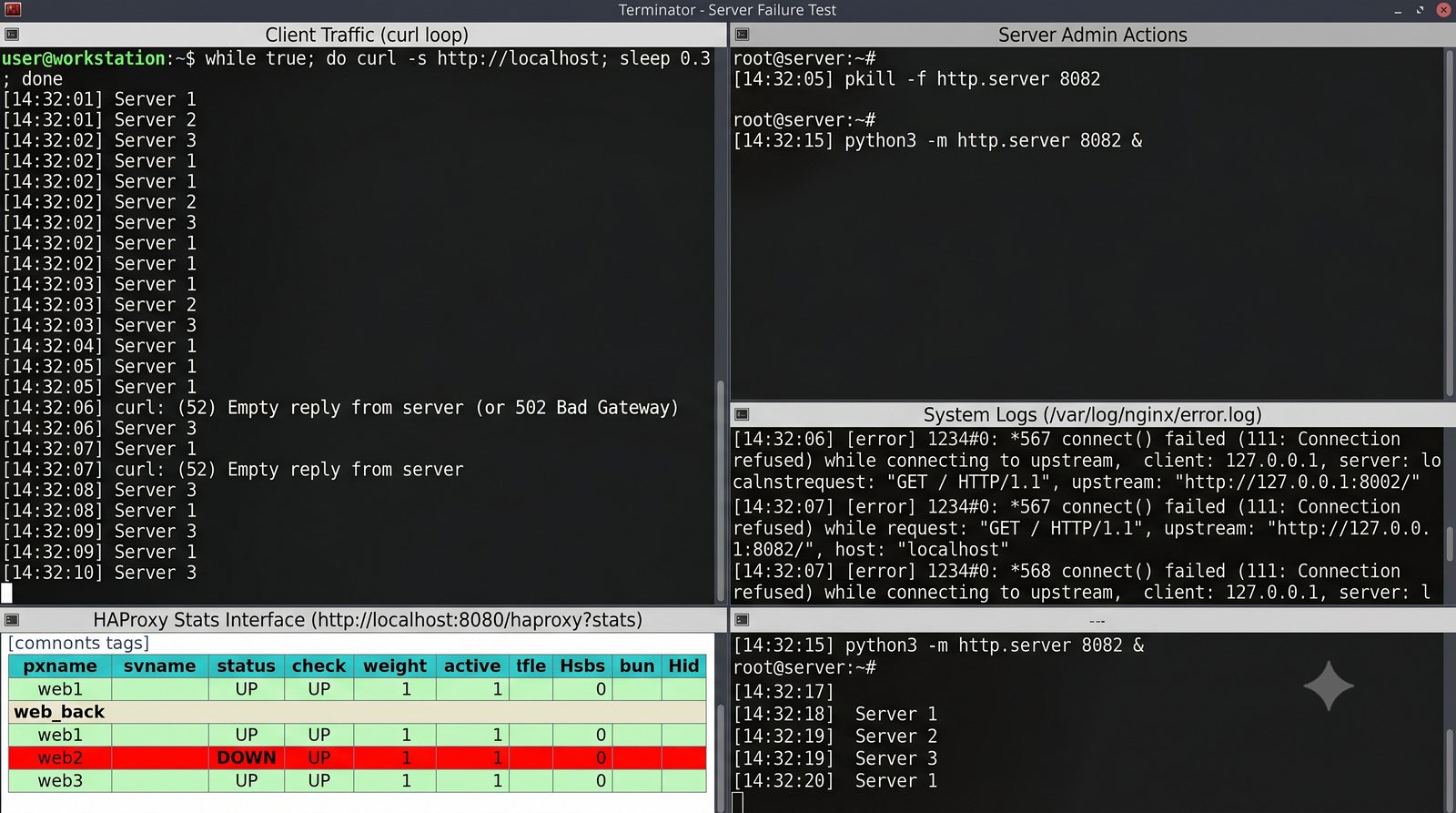
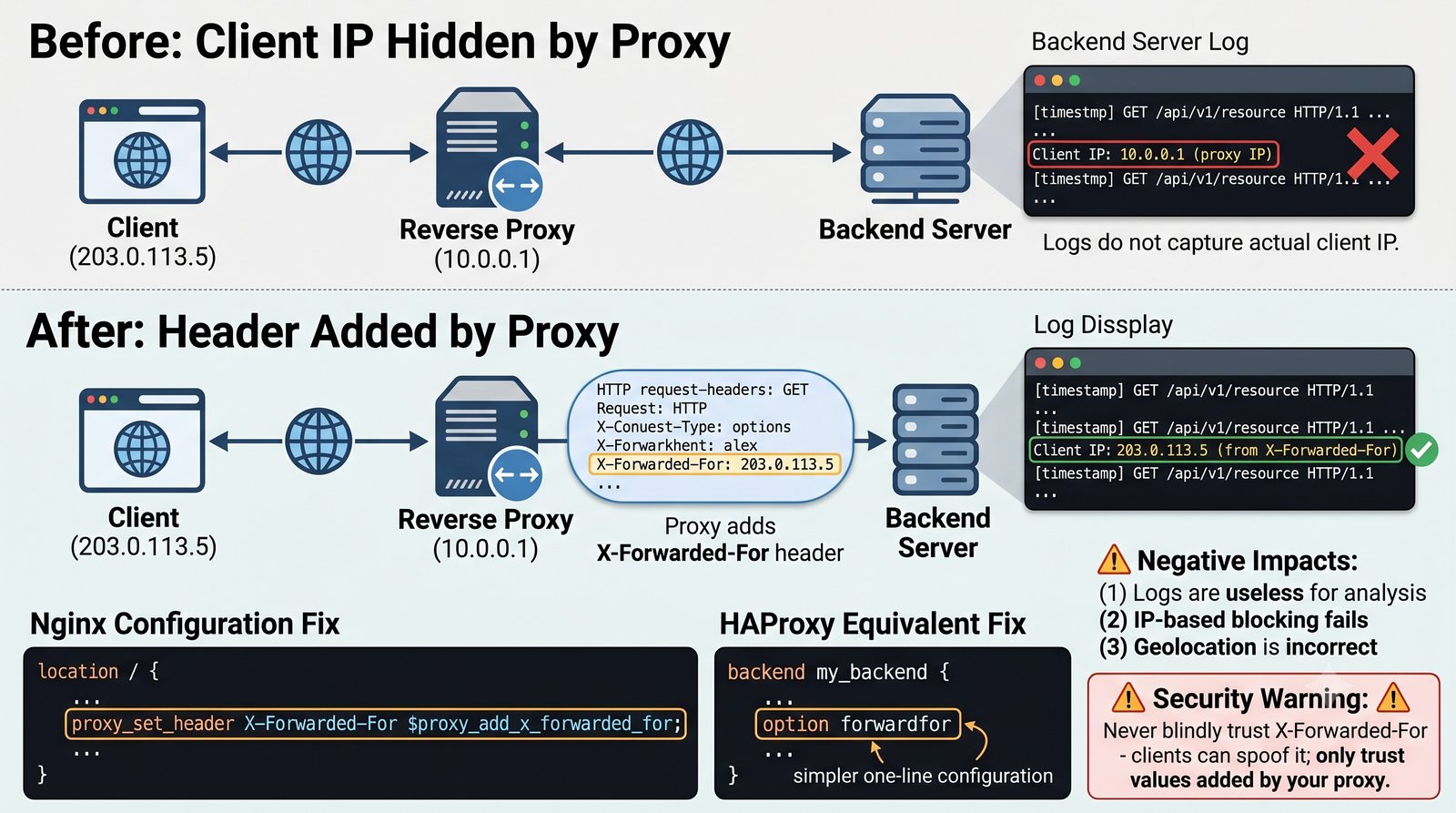
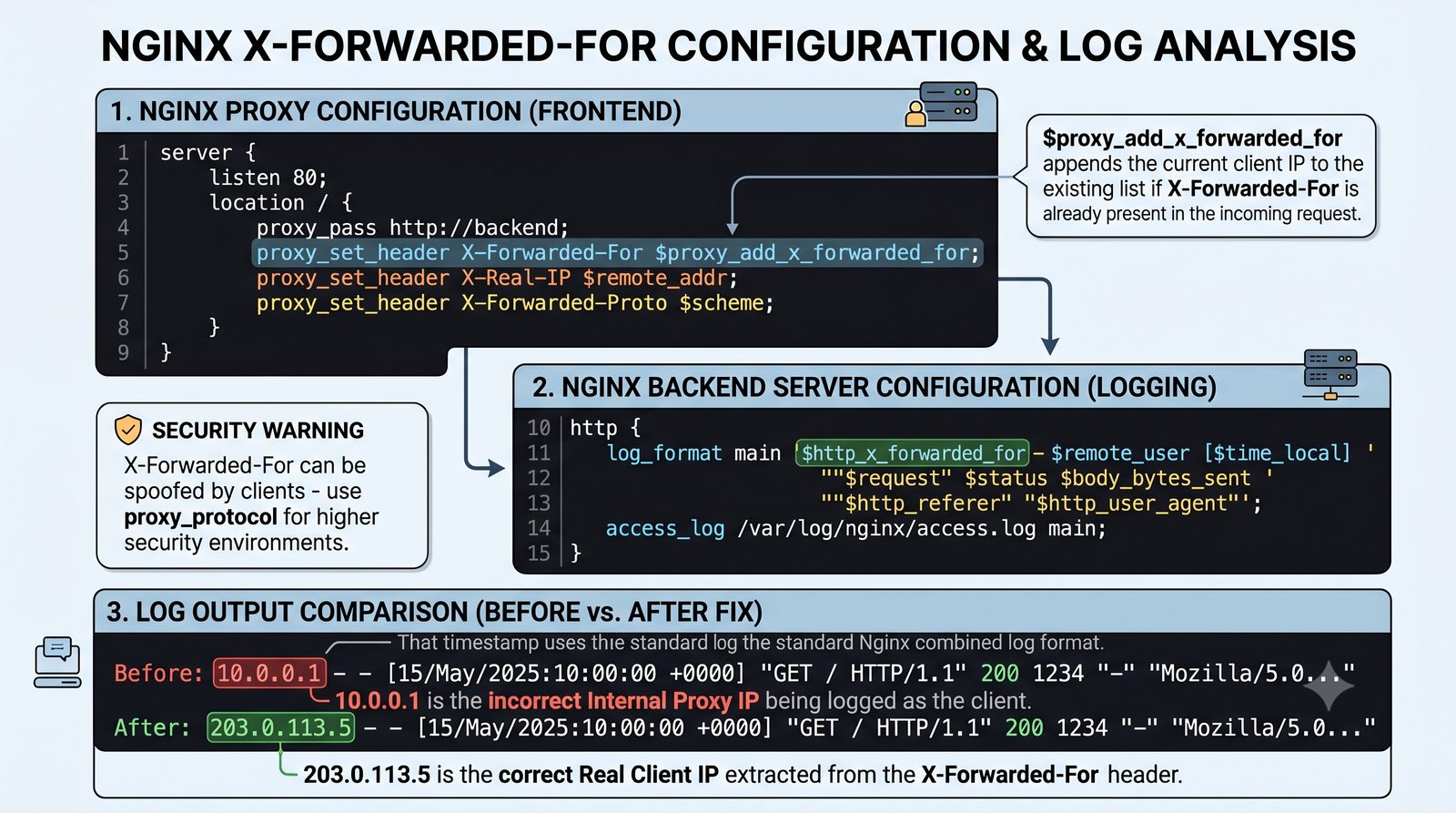
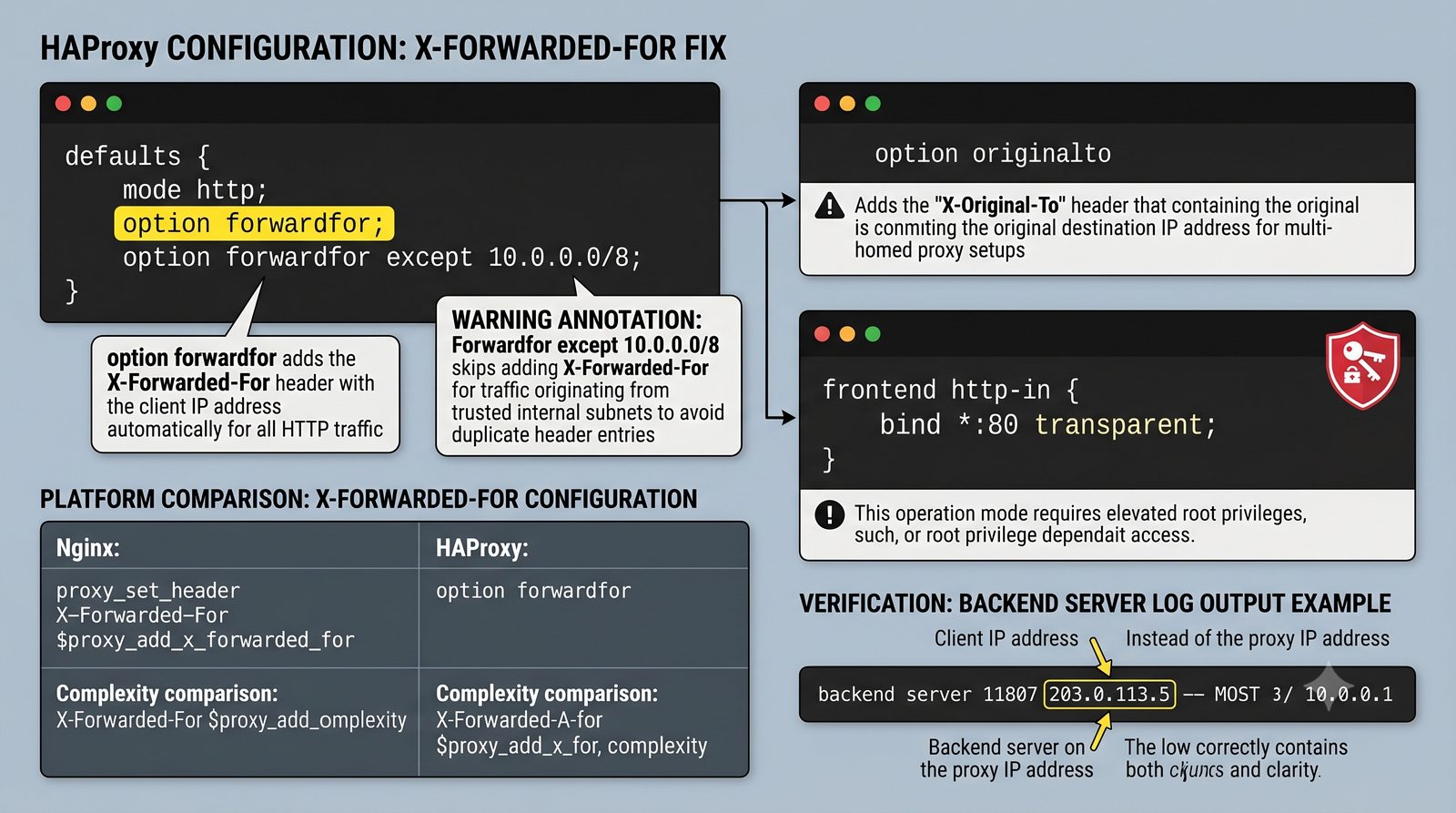
- Materiał zawiera praktyczne laboratorium: konfiguracja Nginx jako Reverse Proxy, testowanie dystrybucji ruchu, troubleshooting nagłówków X-Forwarded-For oraz diagnostyka martwych serwerów backendu