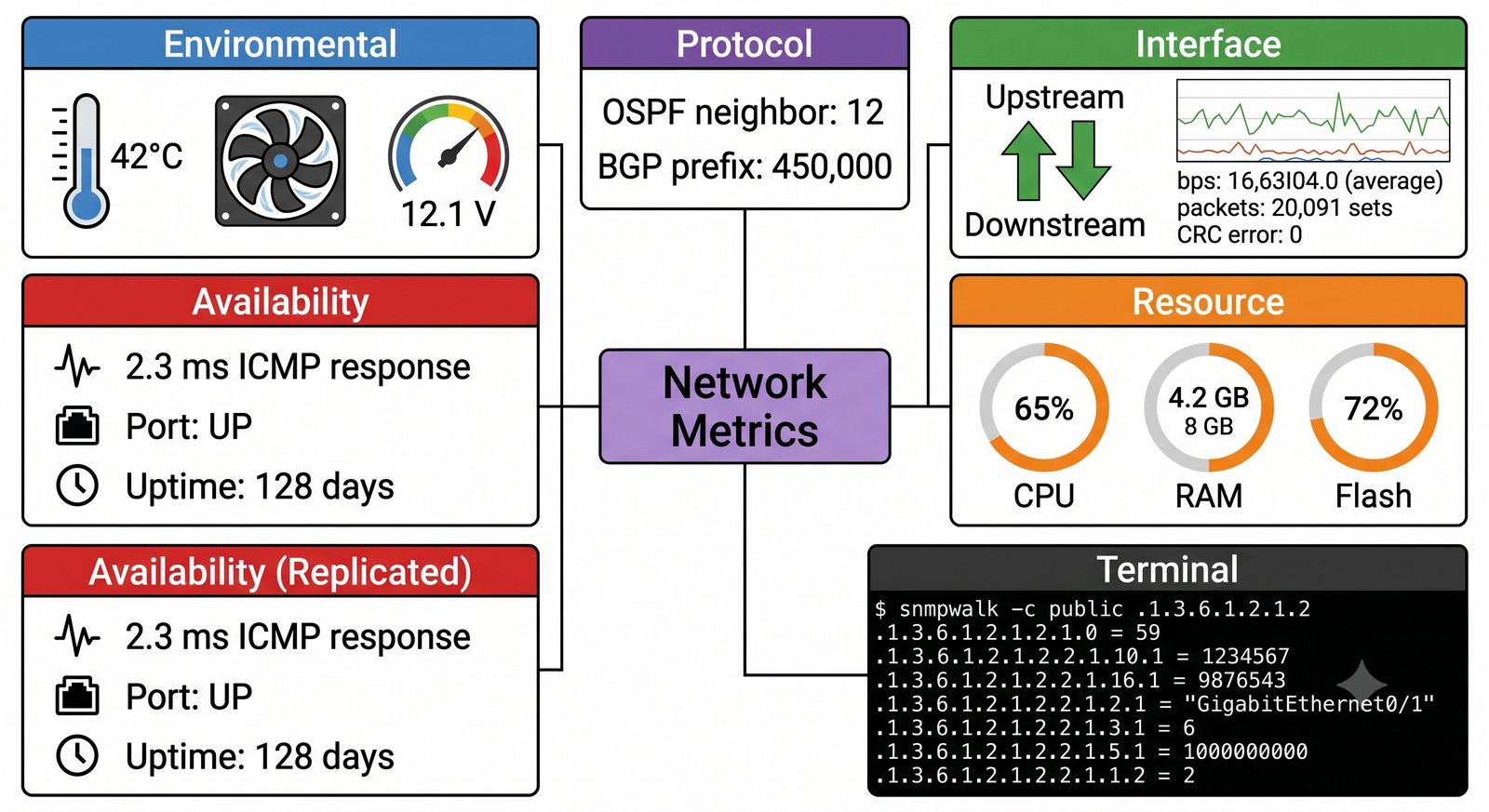
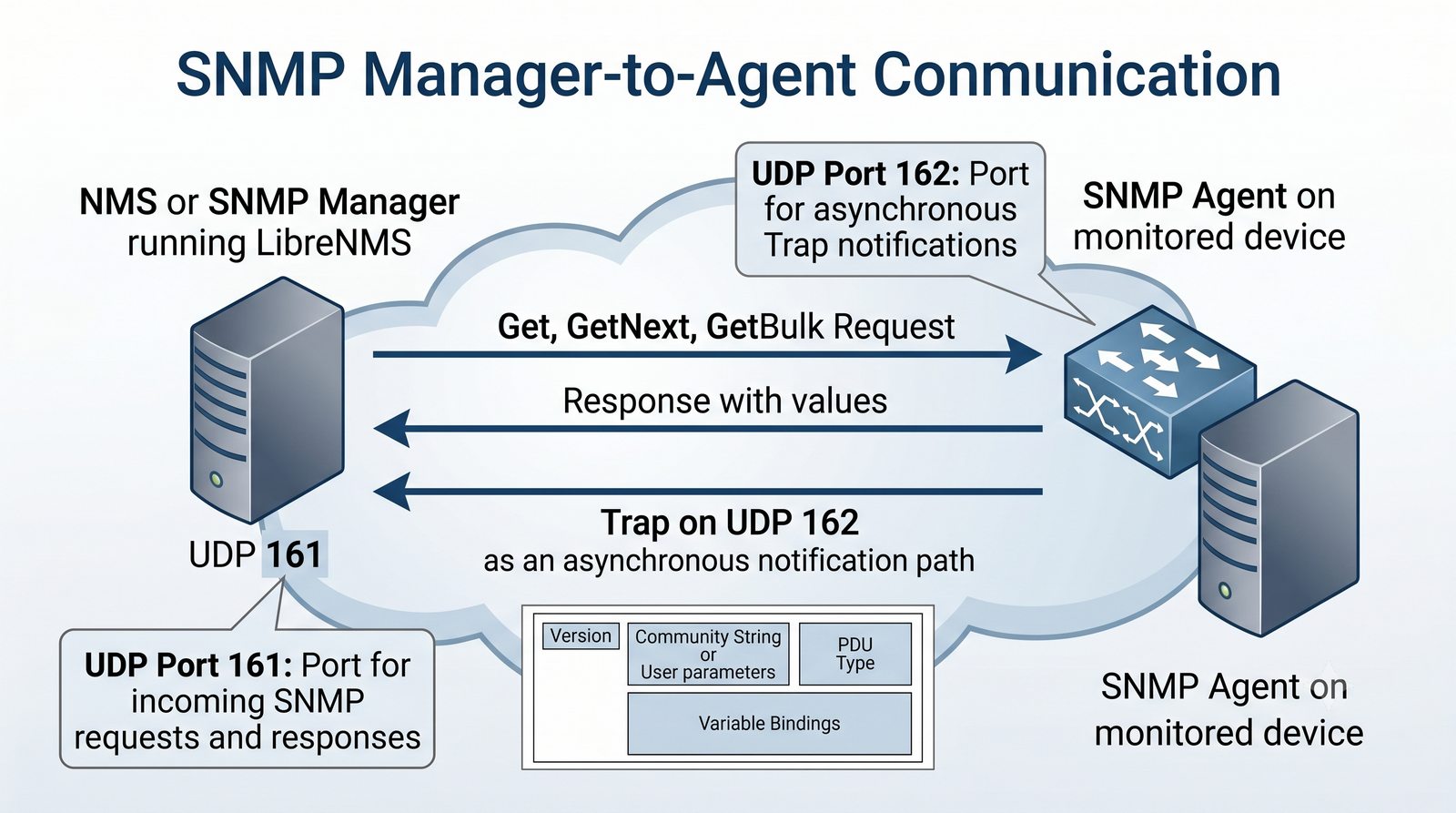
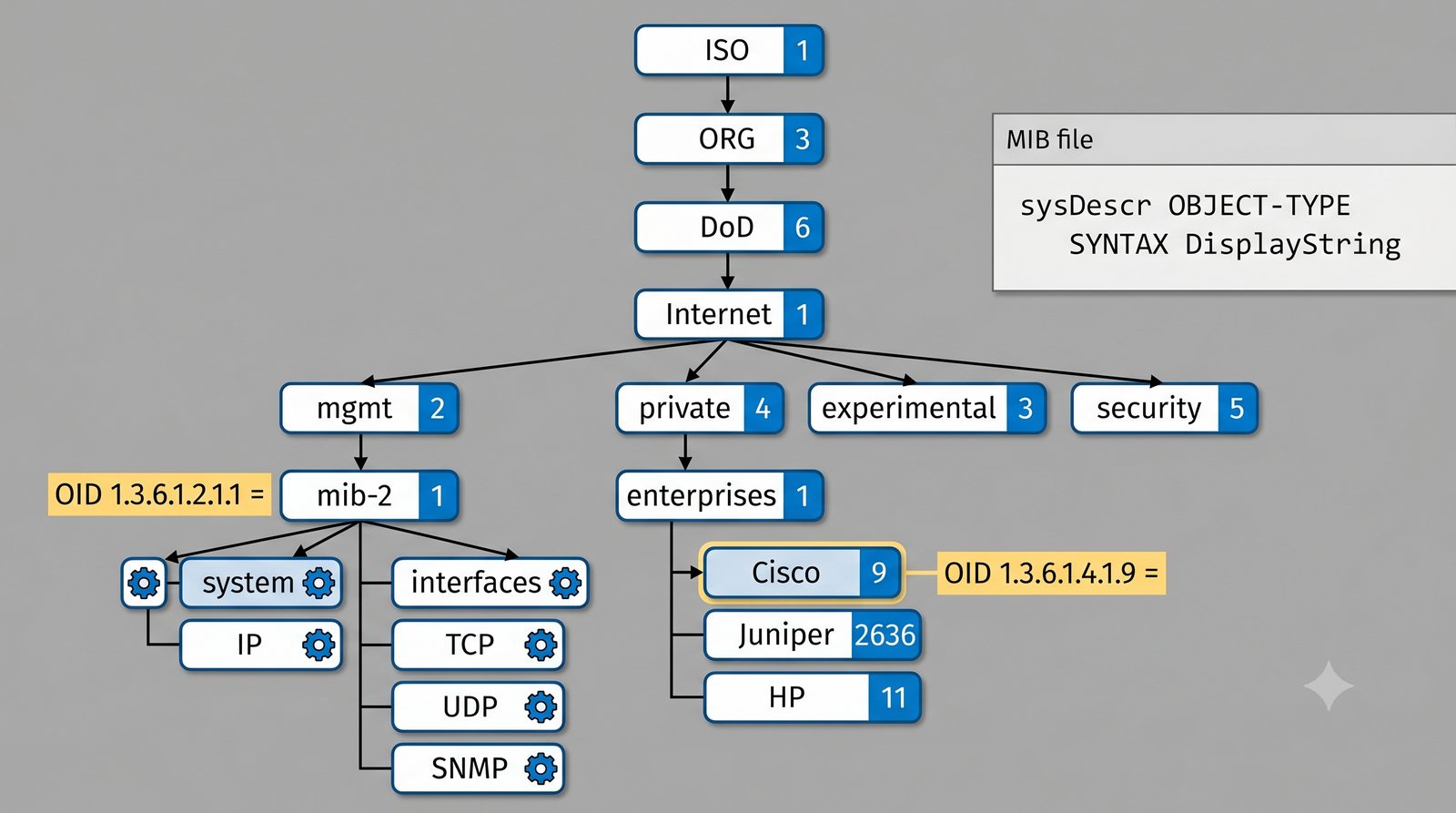
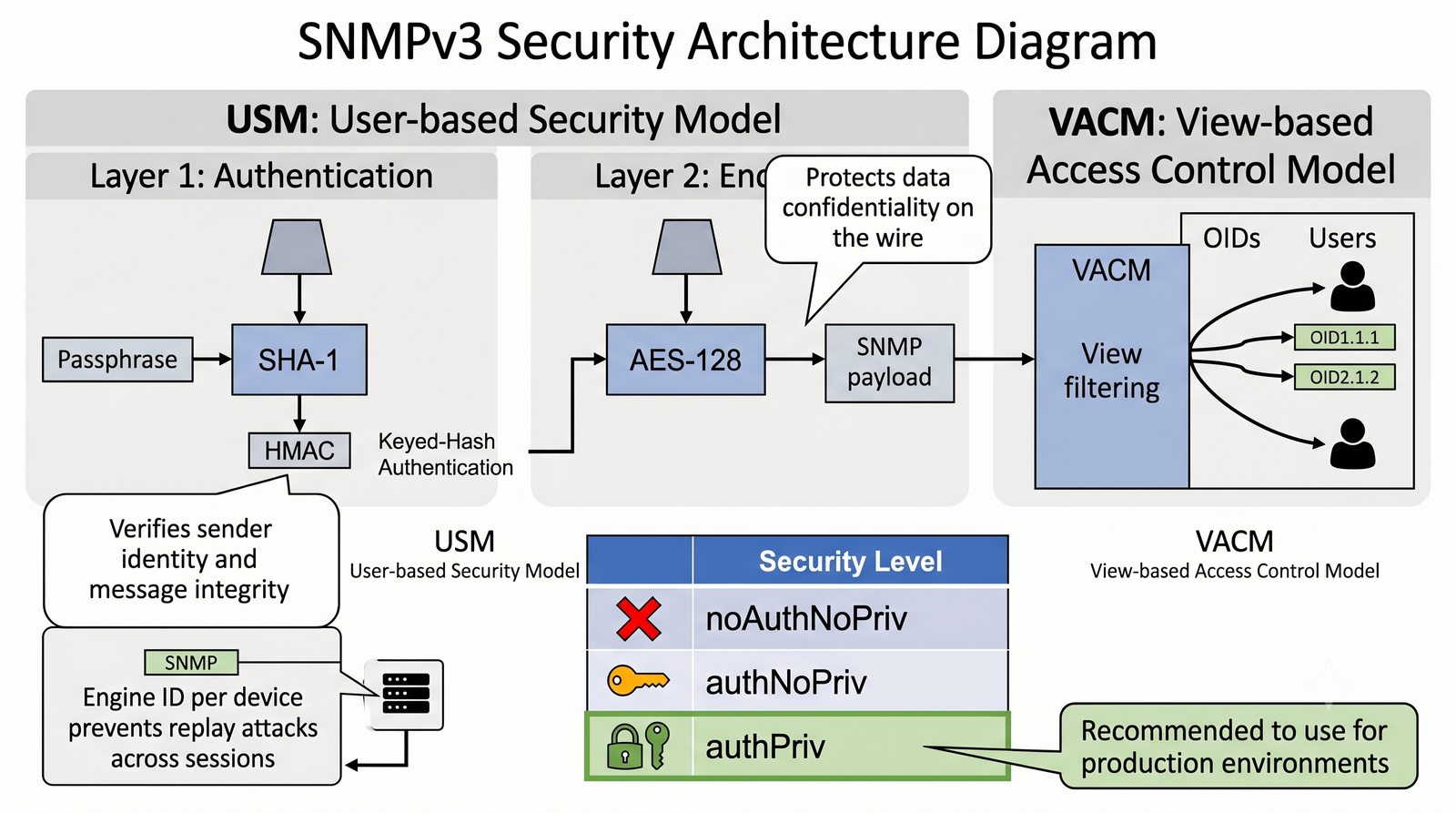
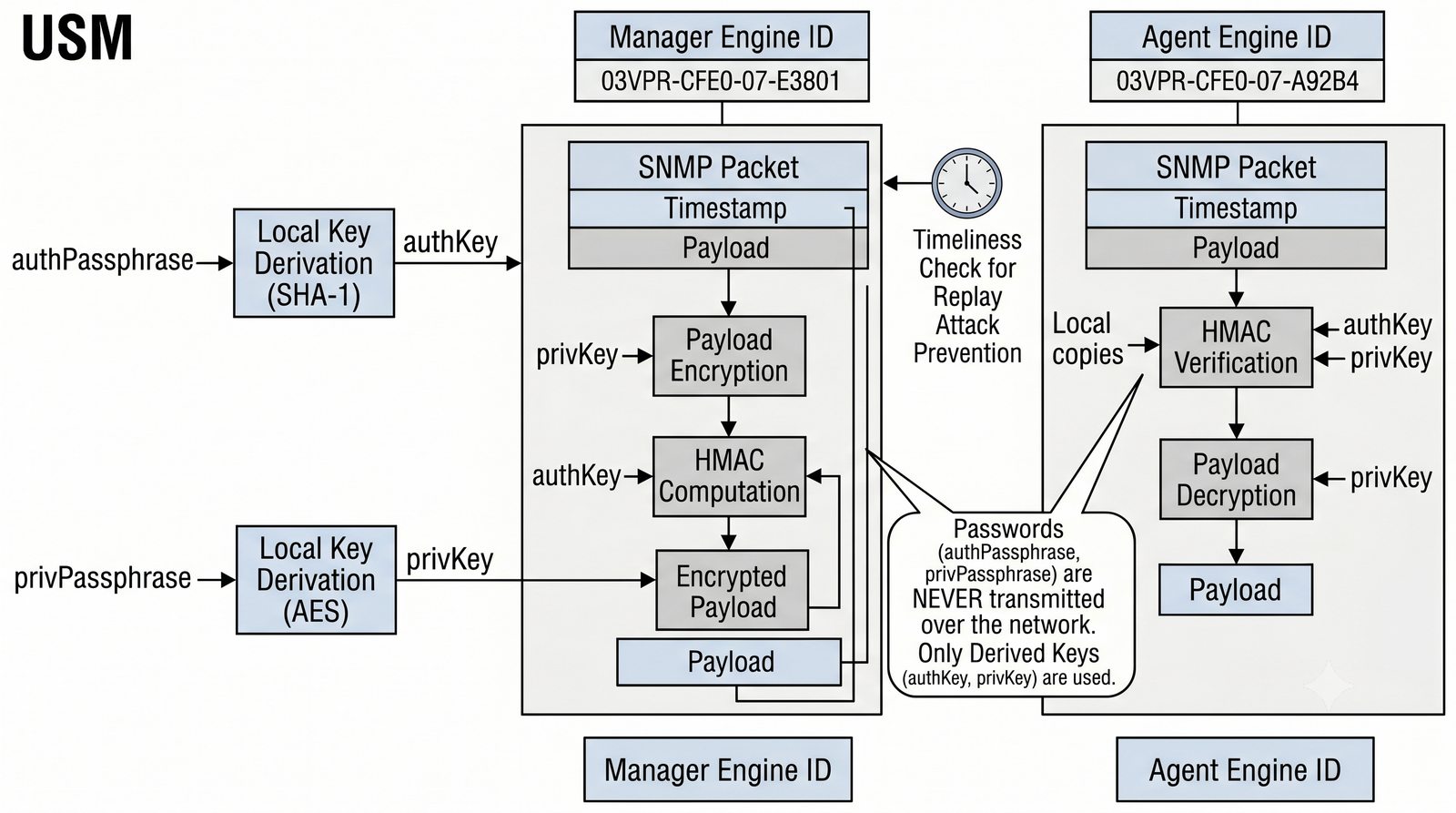
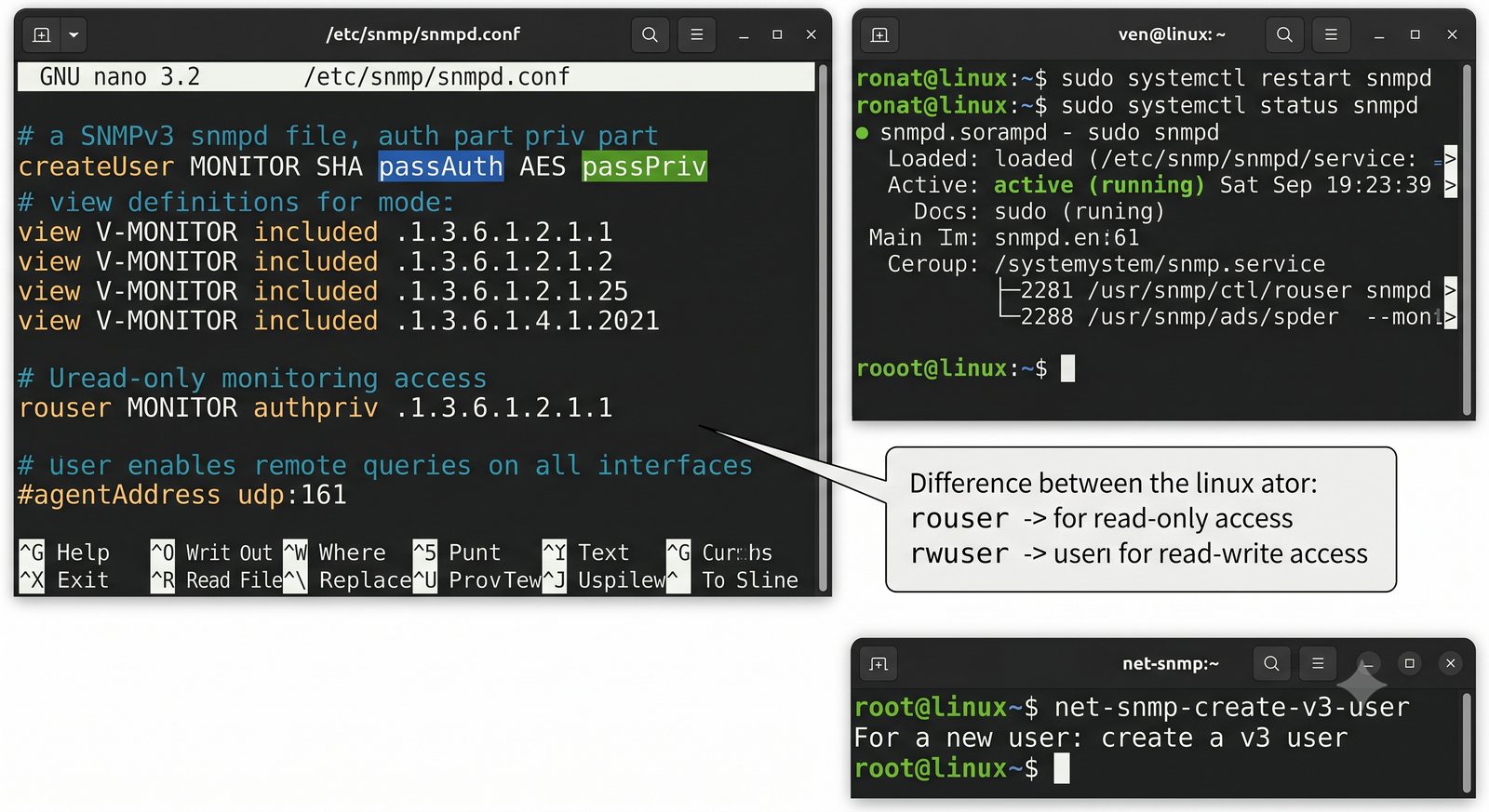
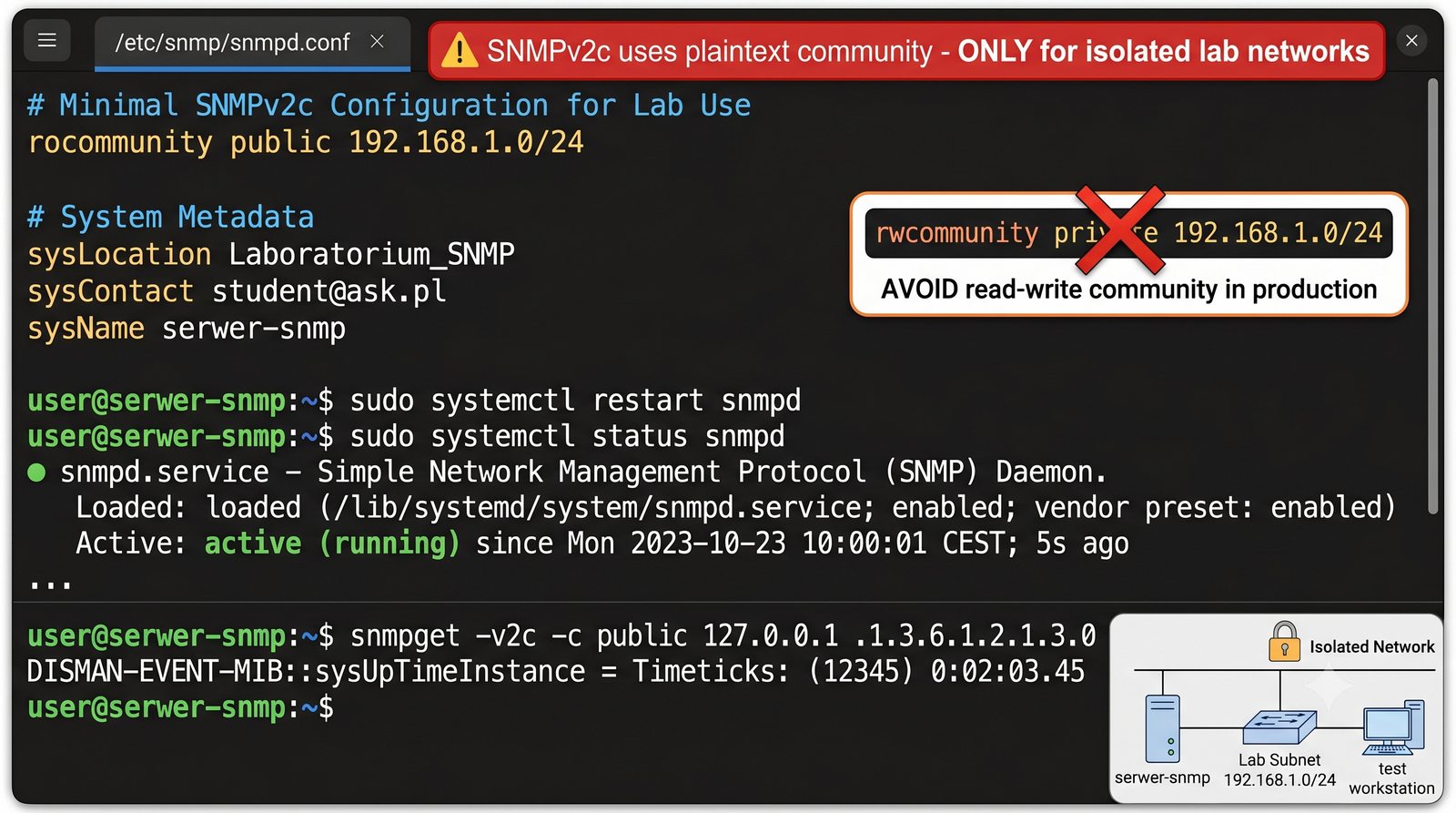
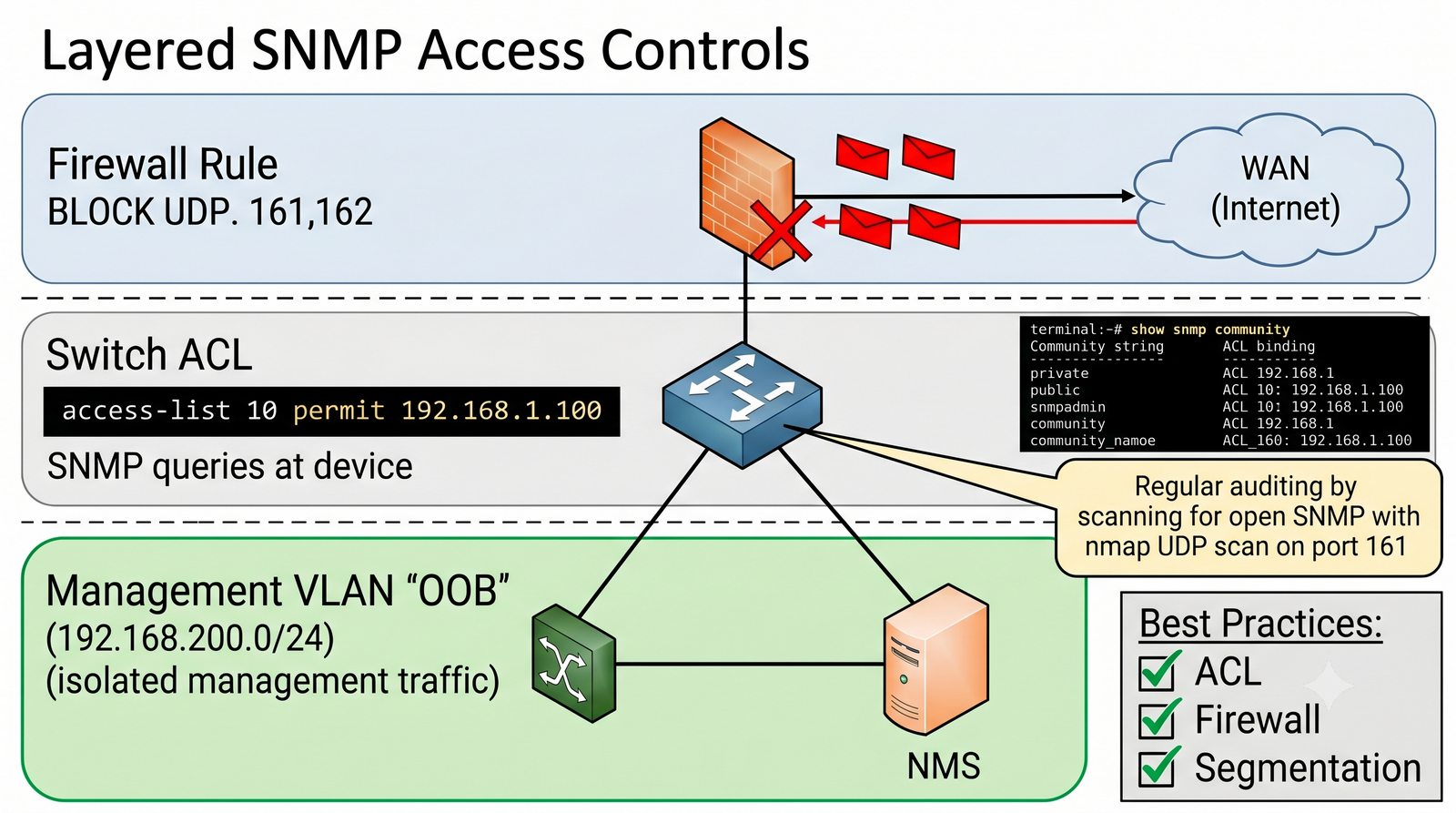
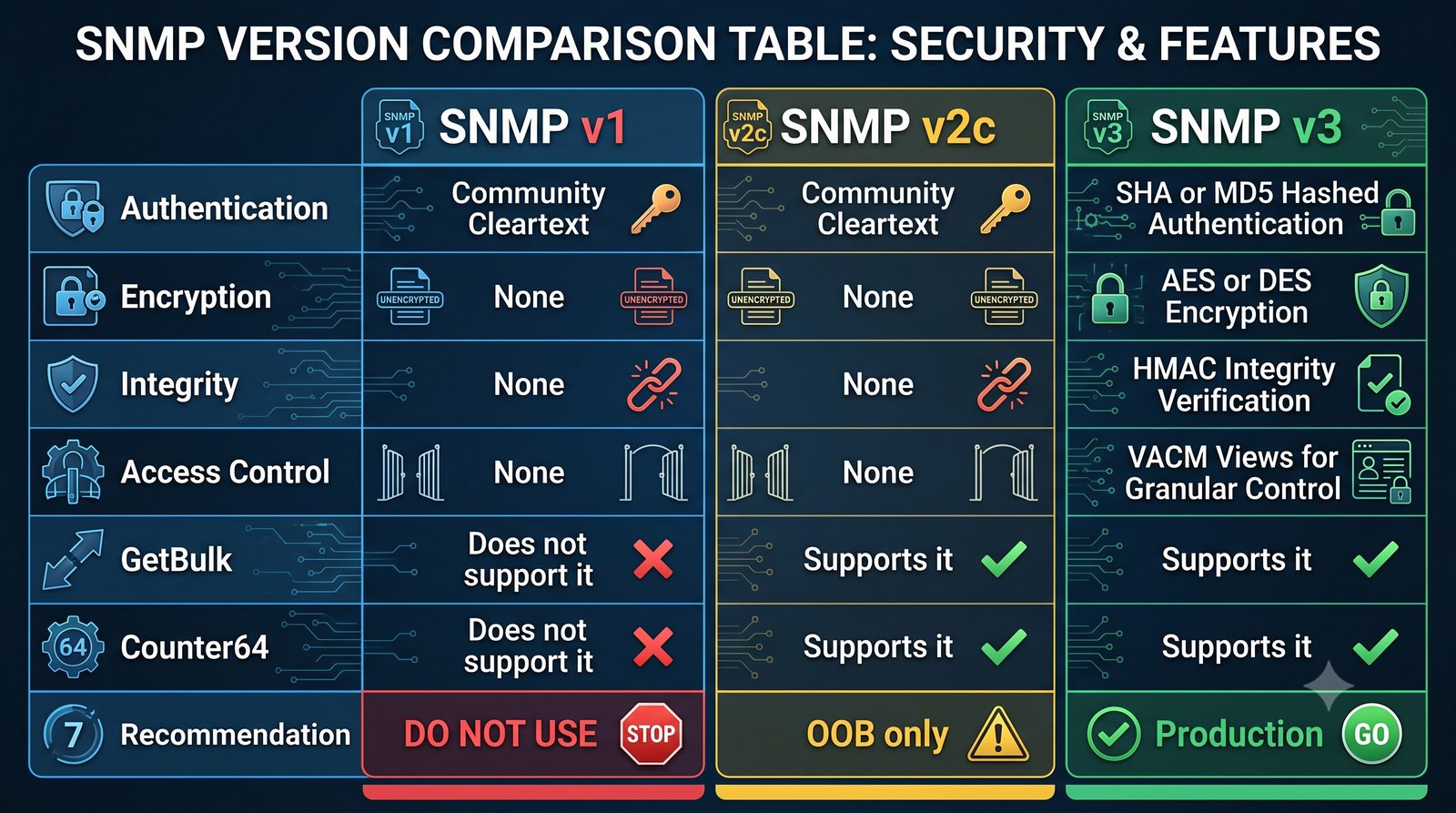
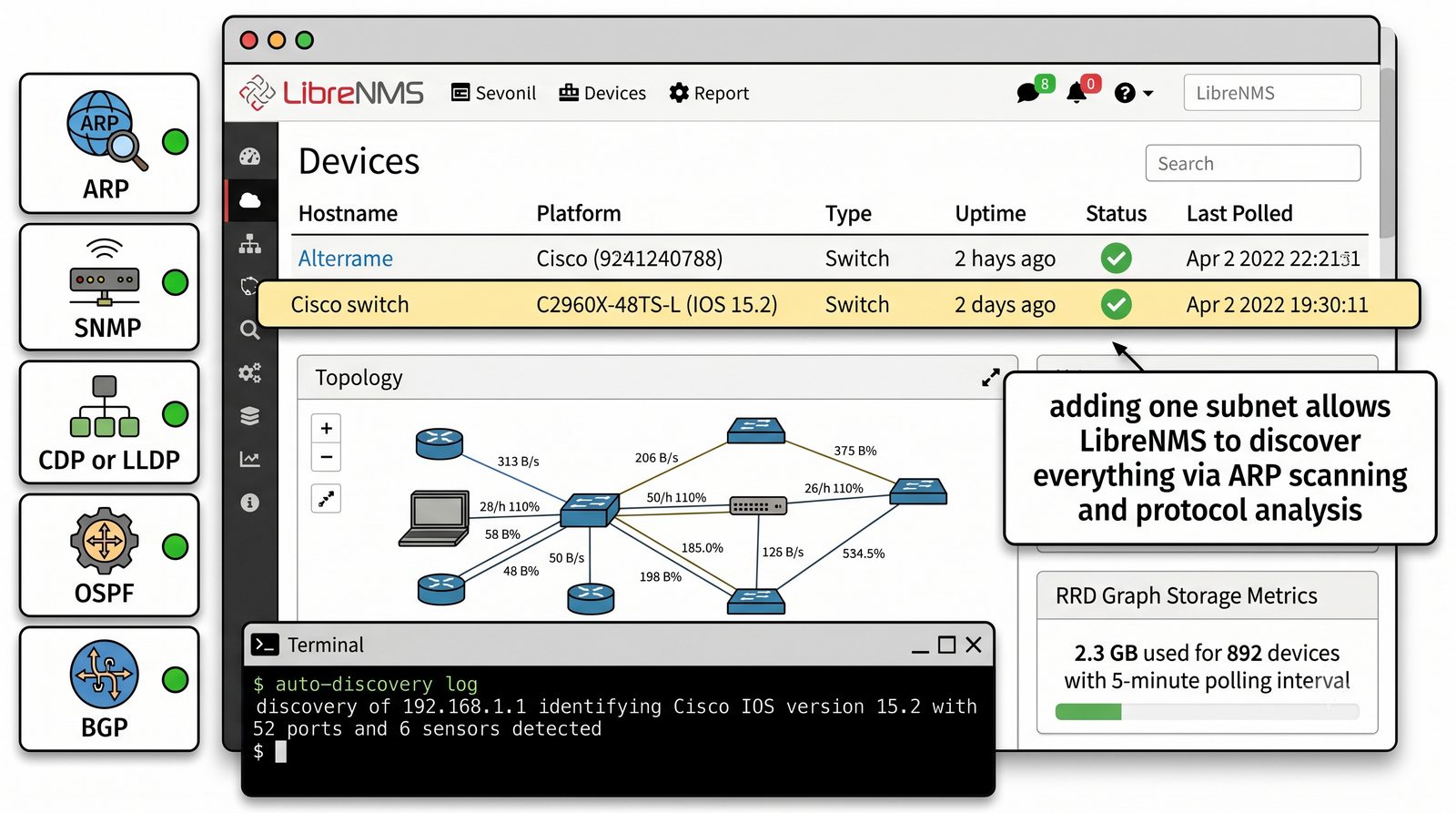
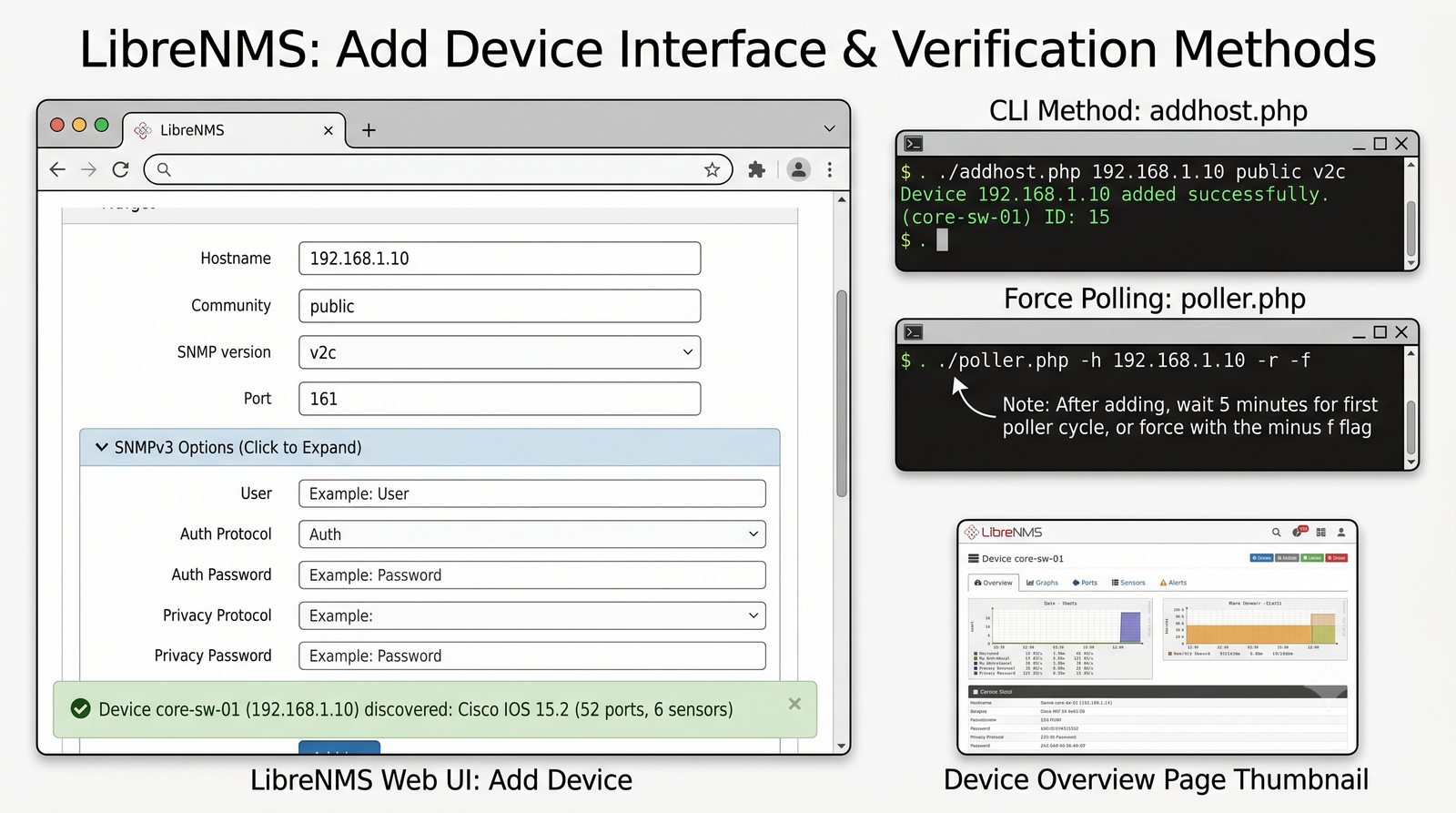
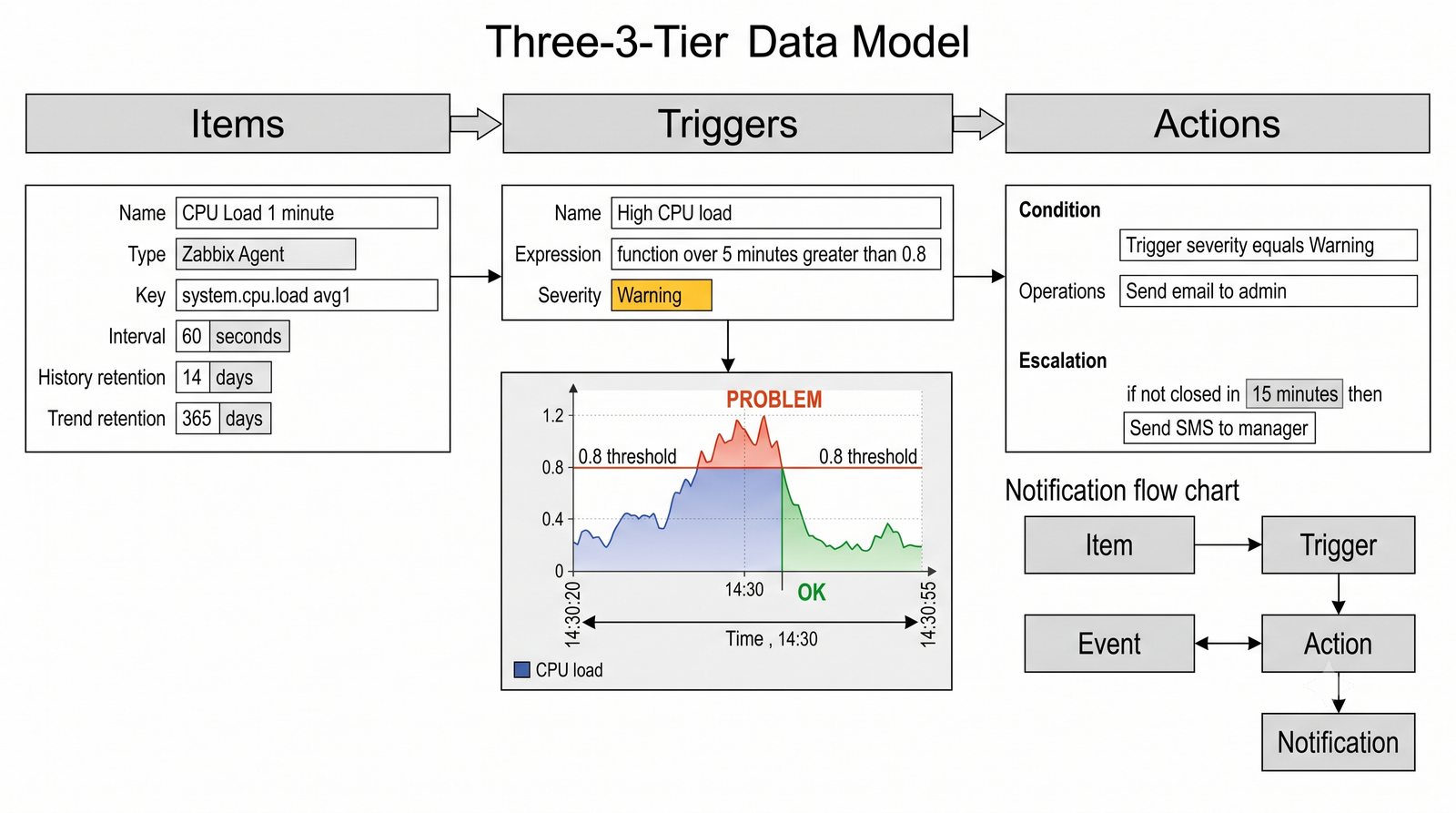
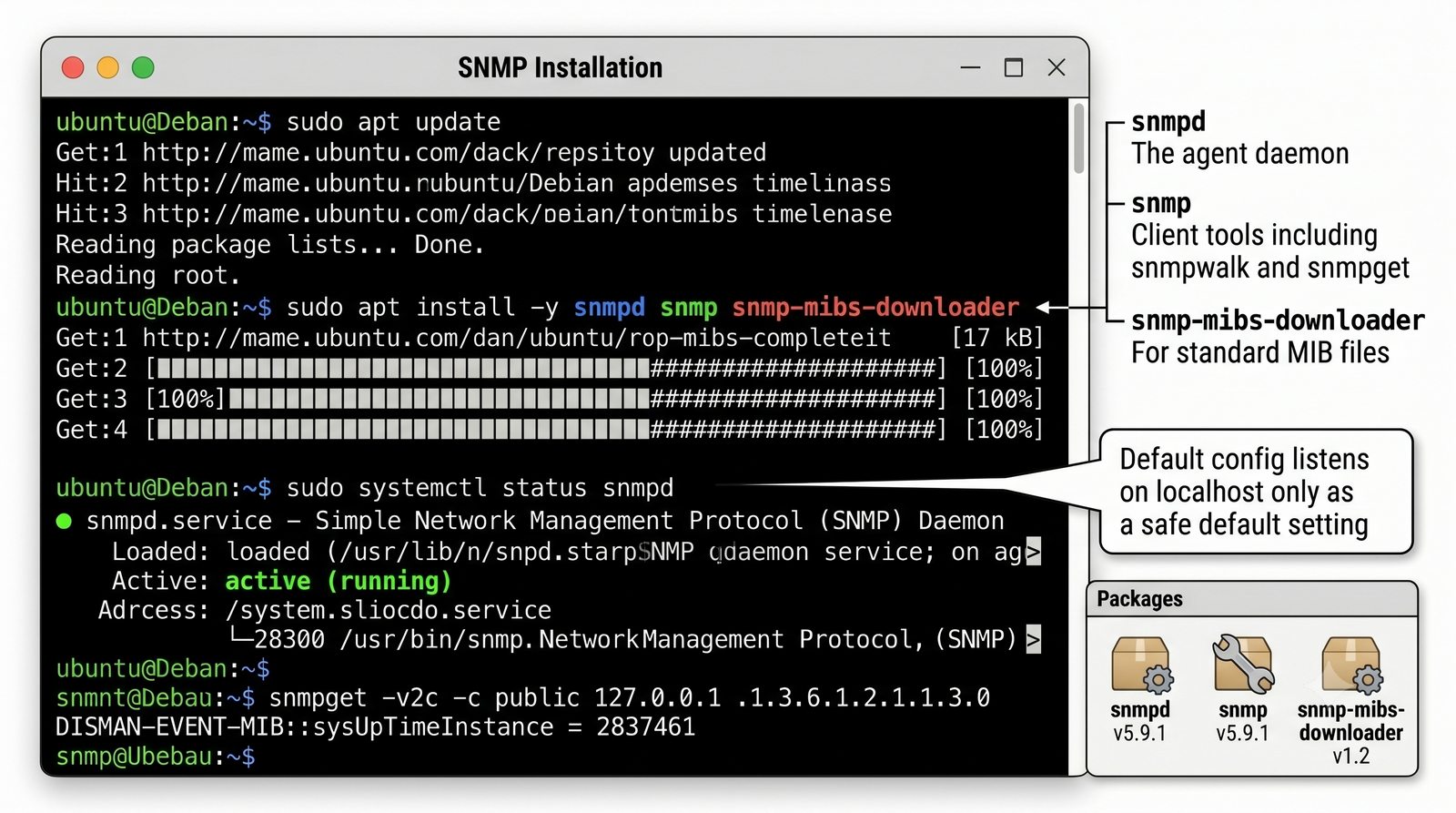
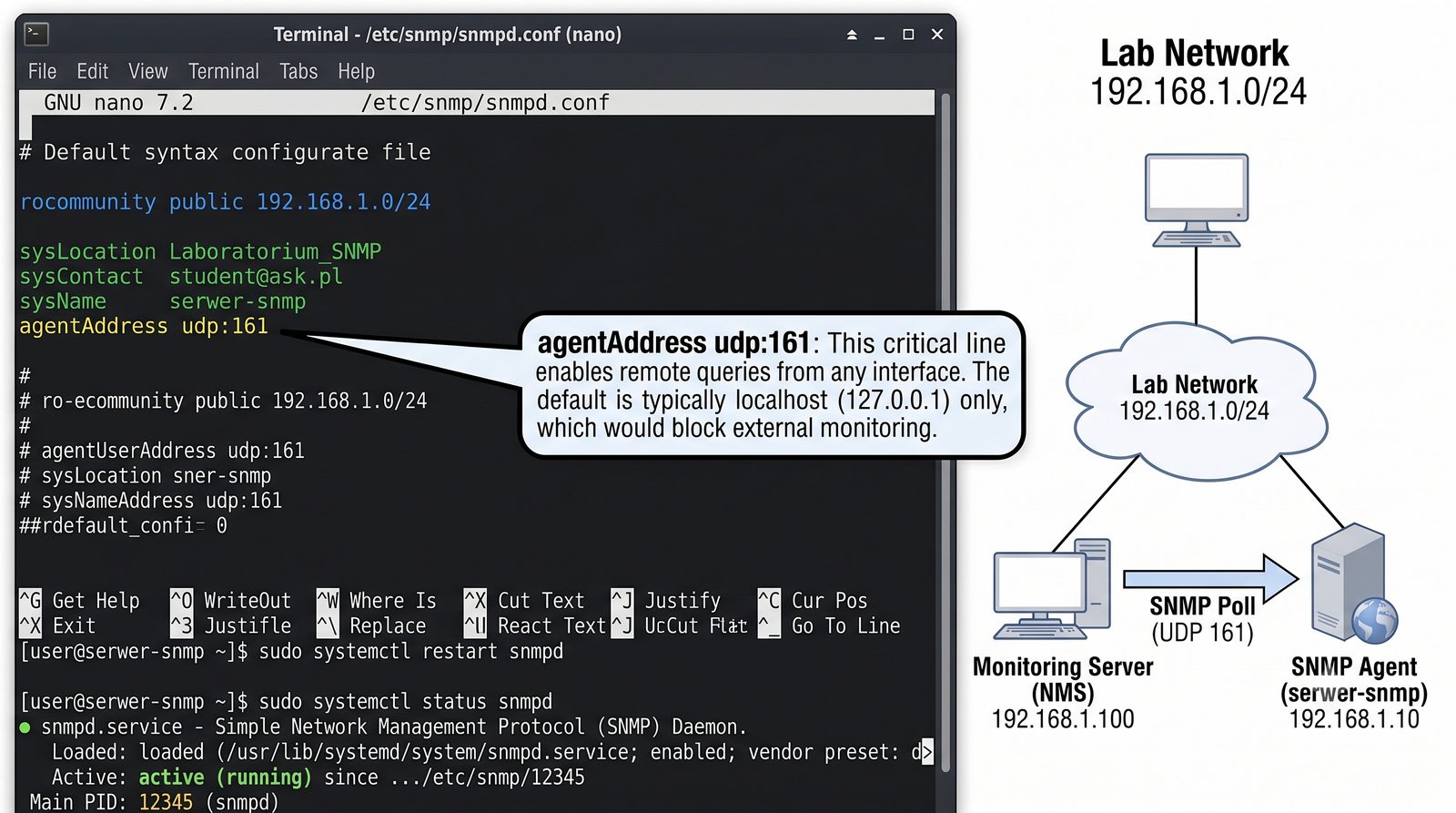
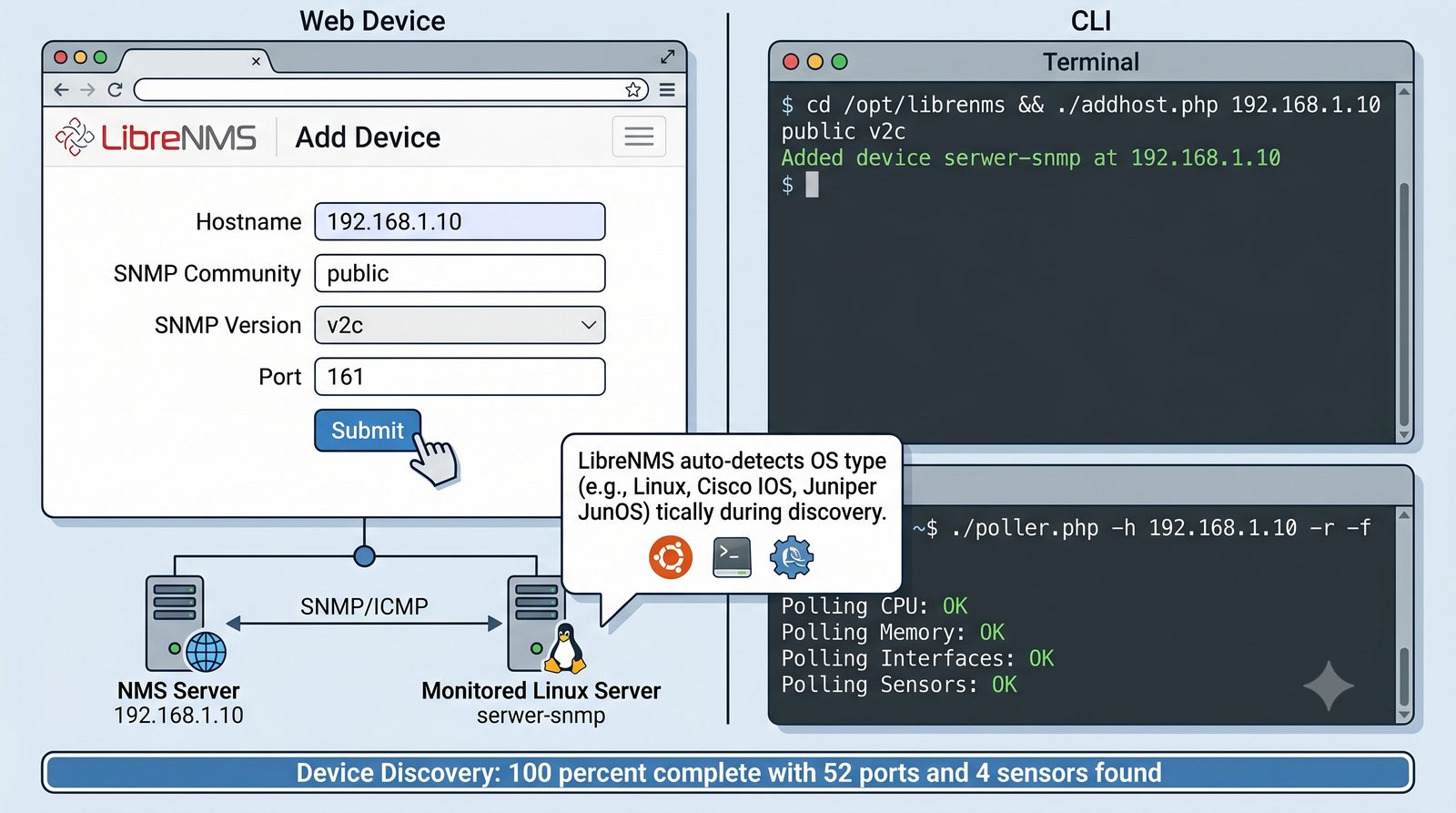
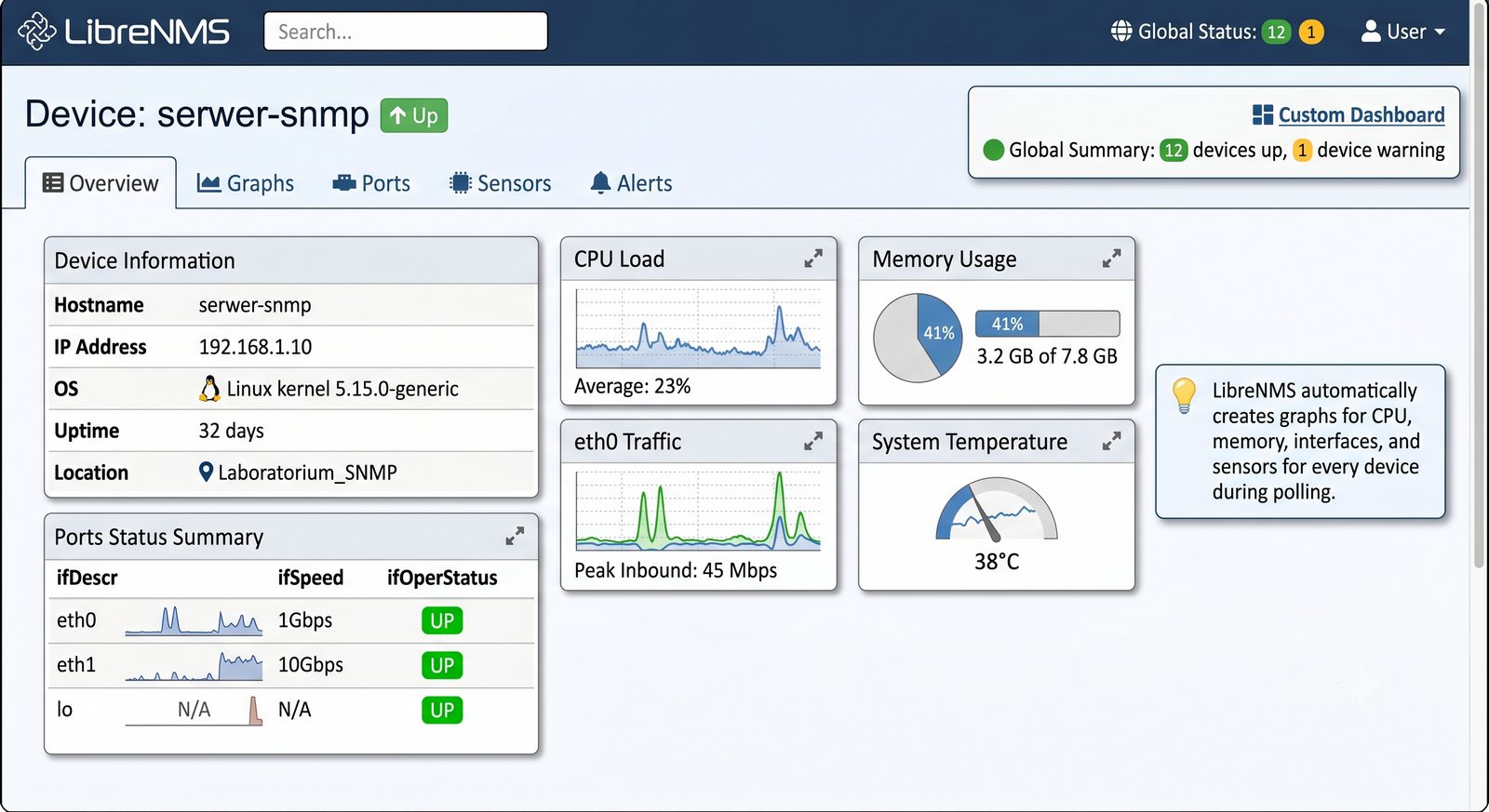
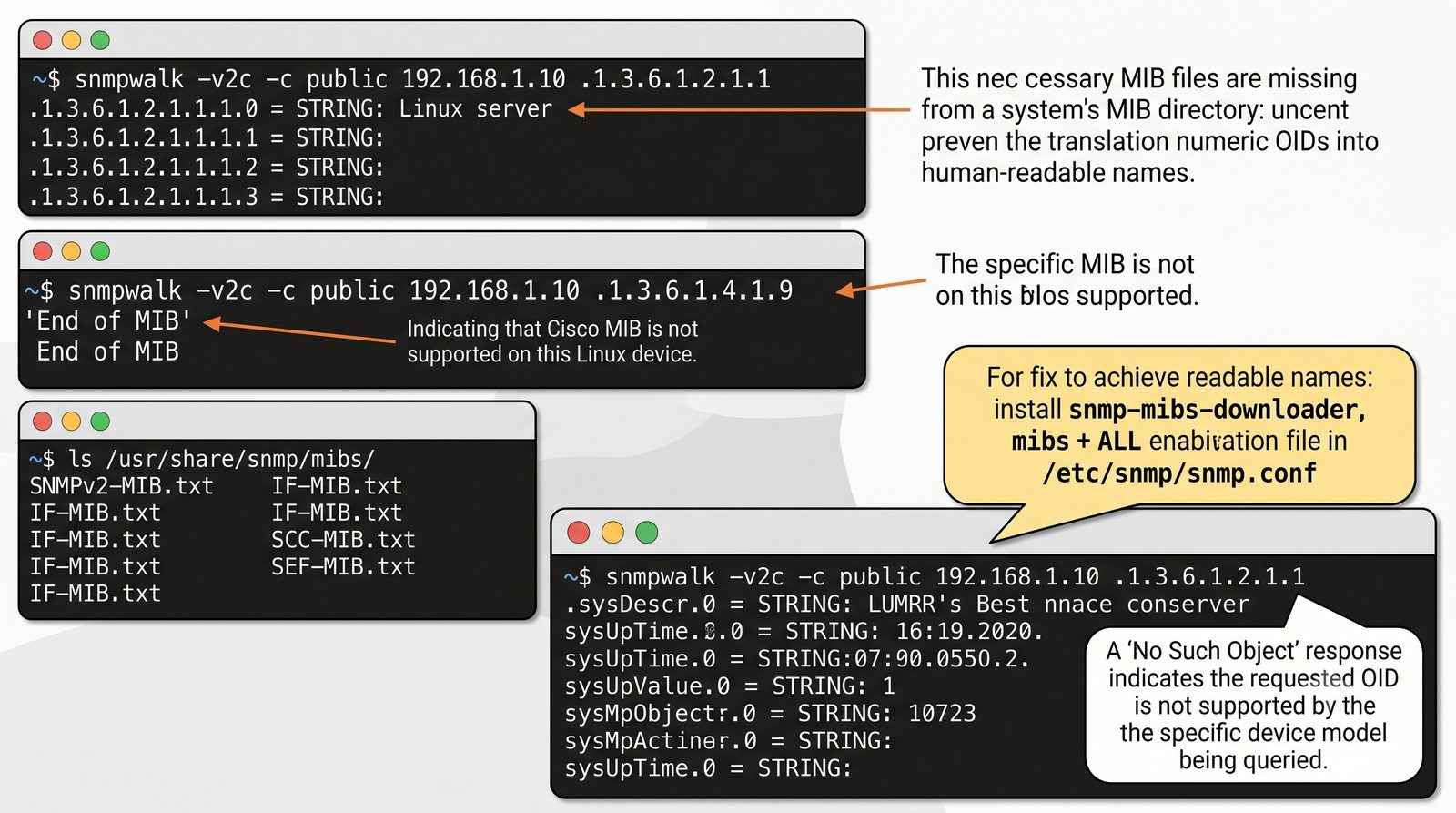
Po dodaniu urządzenia i pierwszym cyklu pollingu dane są dostępne w interfejsie webowym LibreNMS. Zakladka Overview wyświetla ogólne informacje o urządzeniu: adres IP, typ urządzenia (wykryty automatycznie), wersje systemu operacyjnego, czas pracy (uptime), lokalizację oraz kontakt.
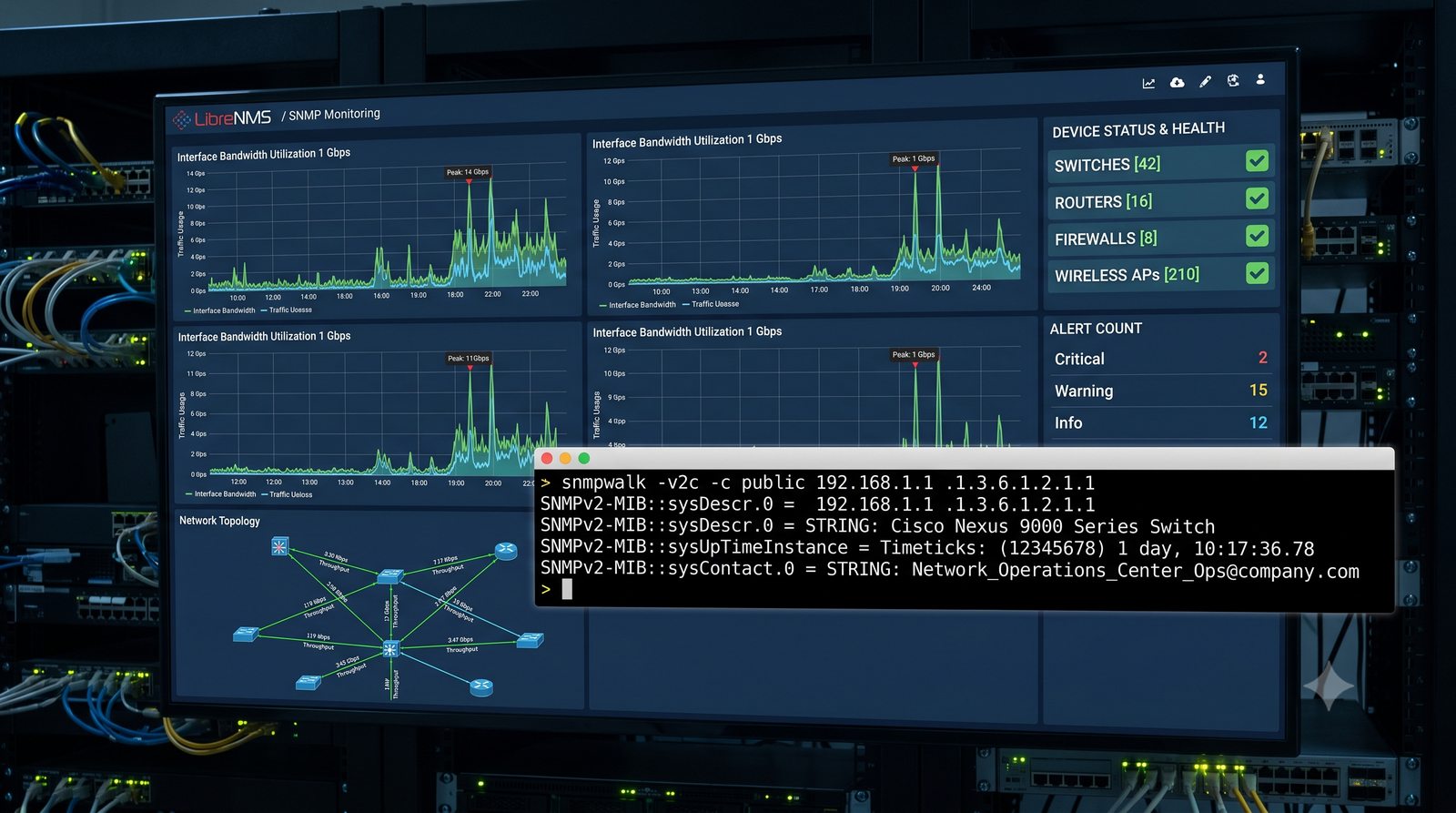
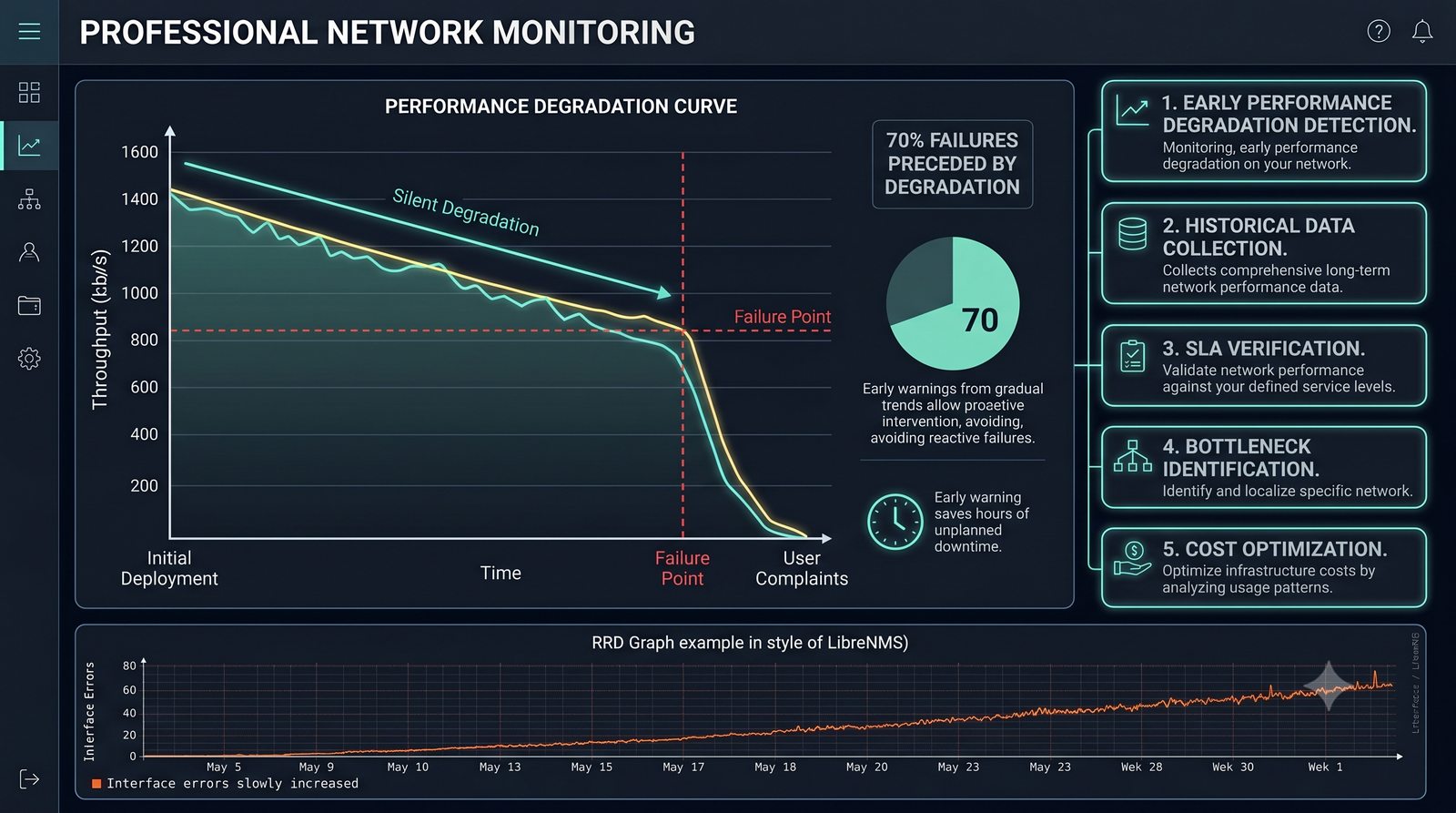
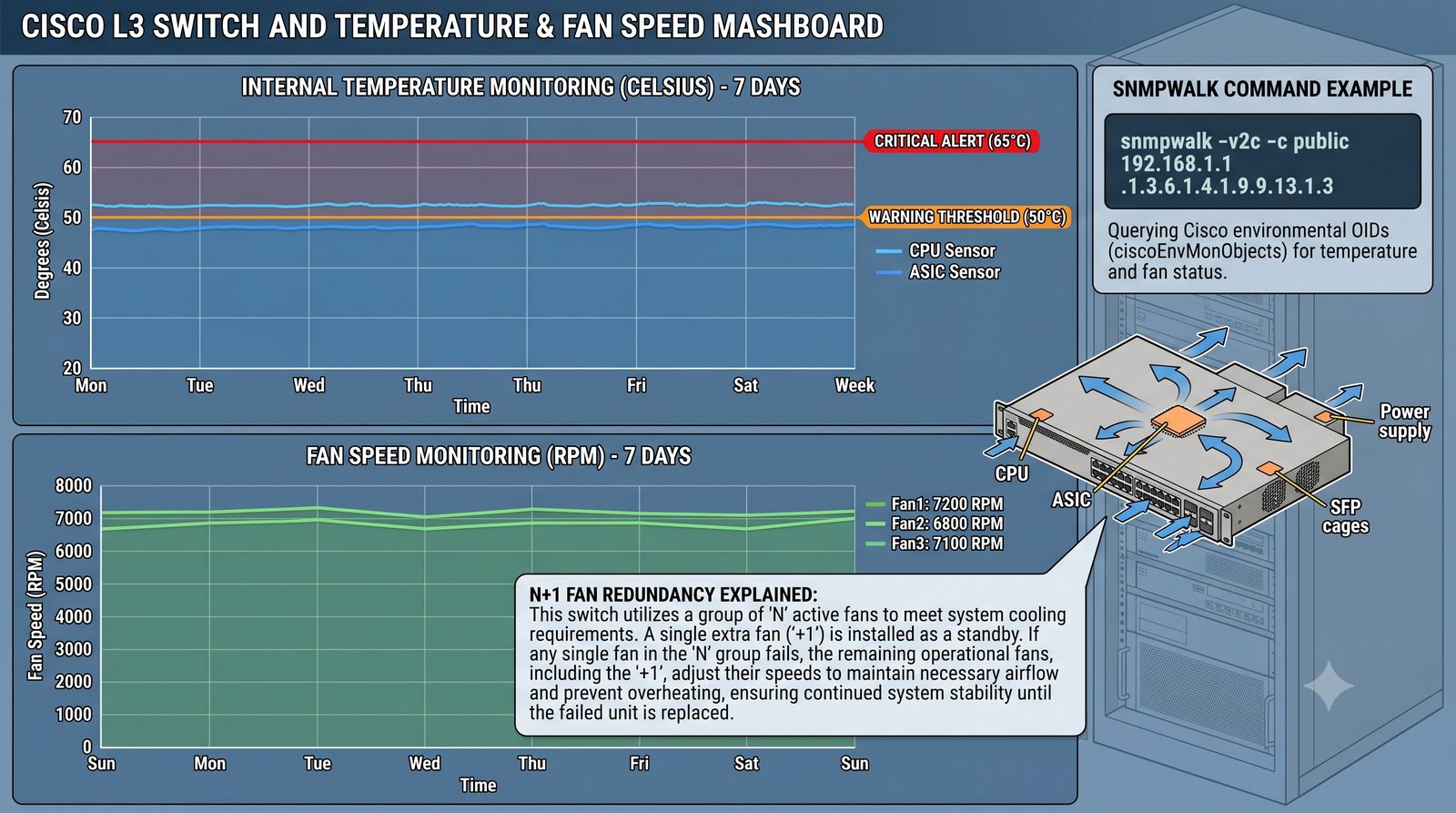
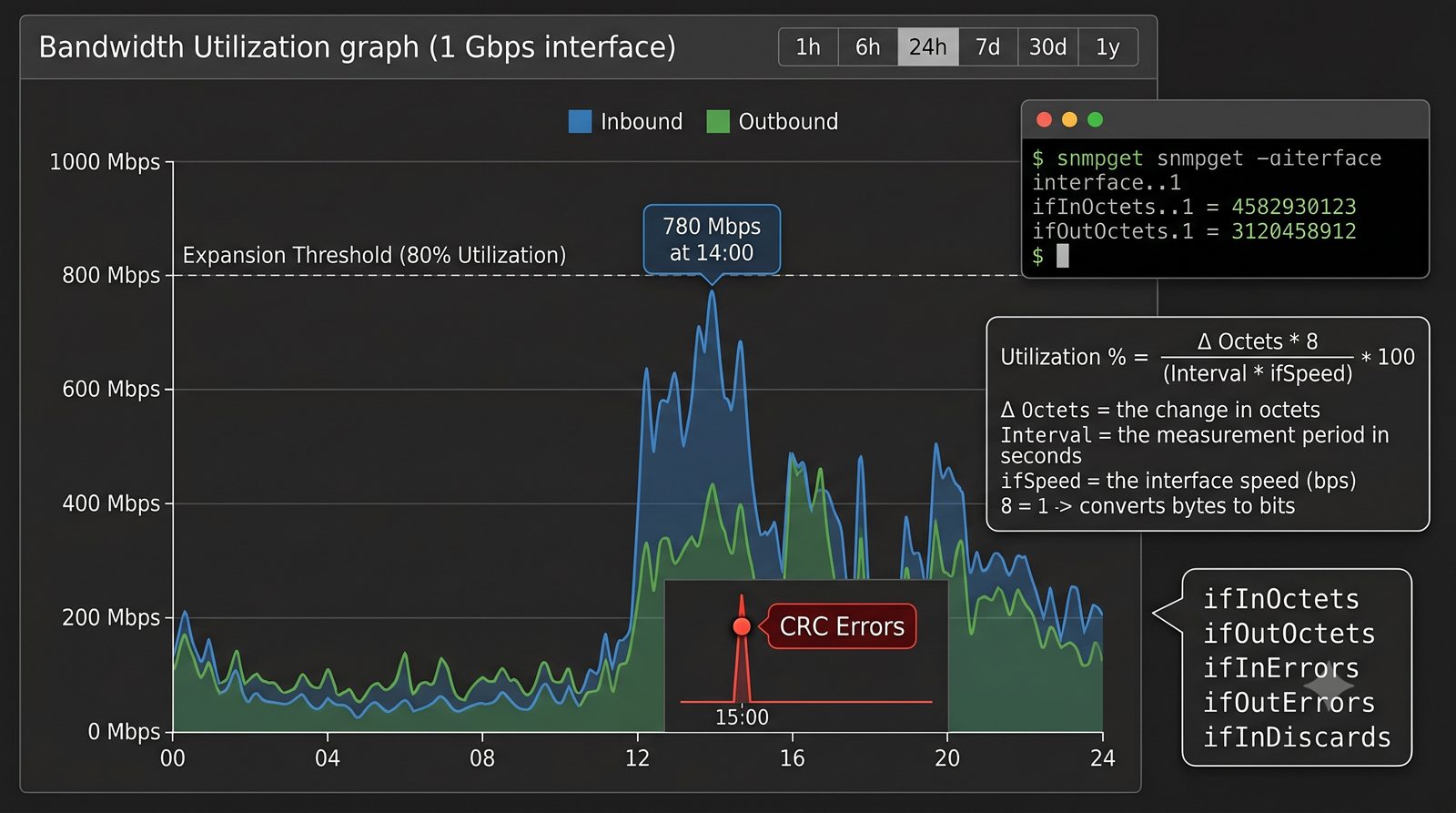
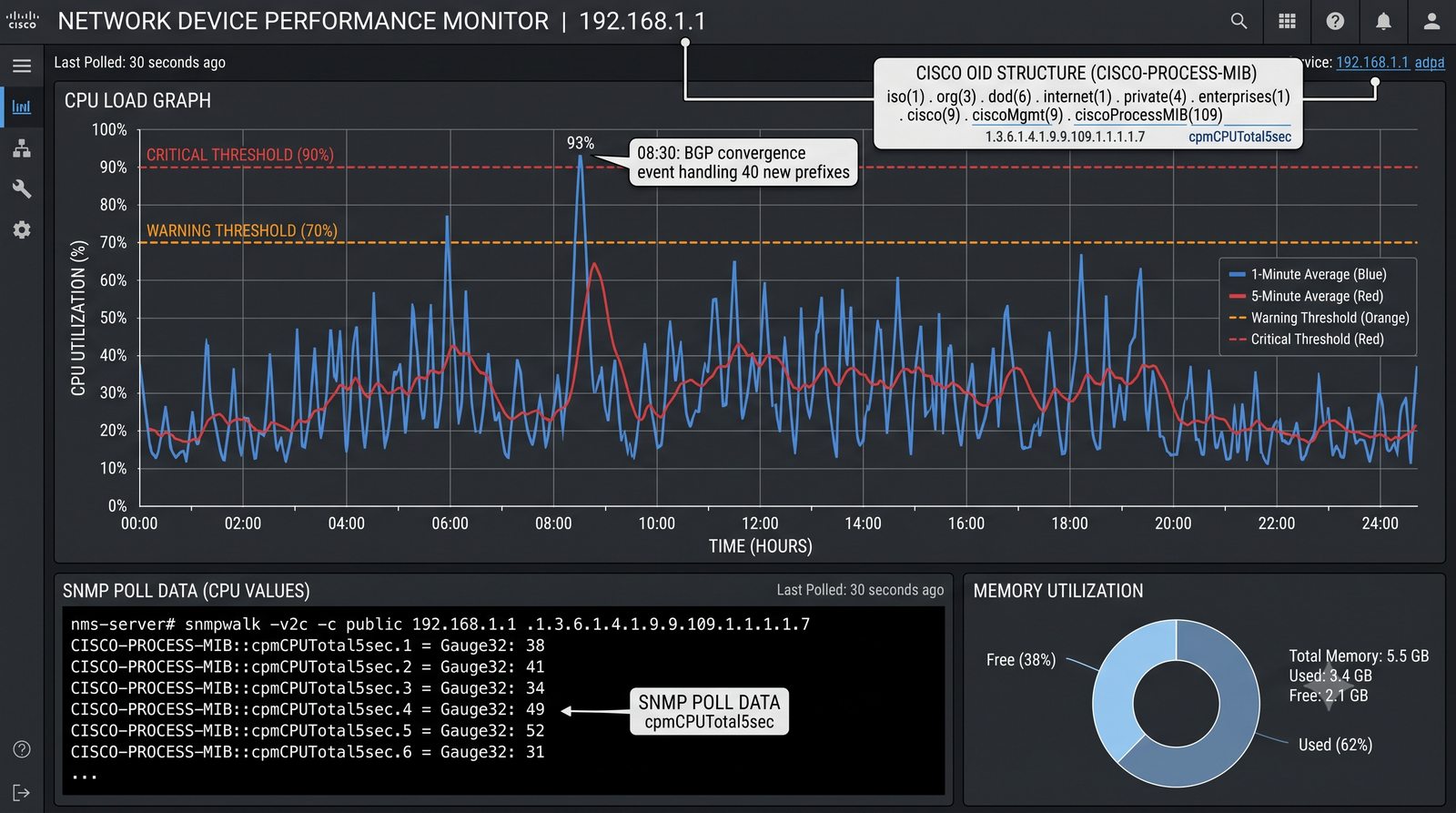
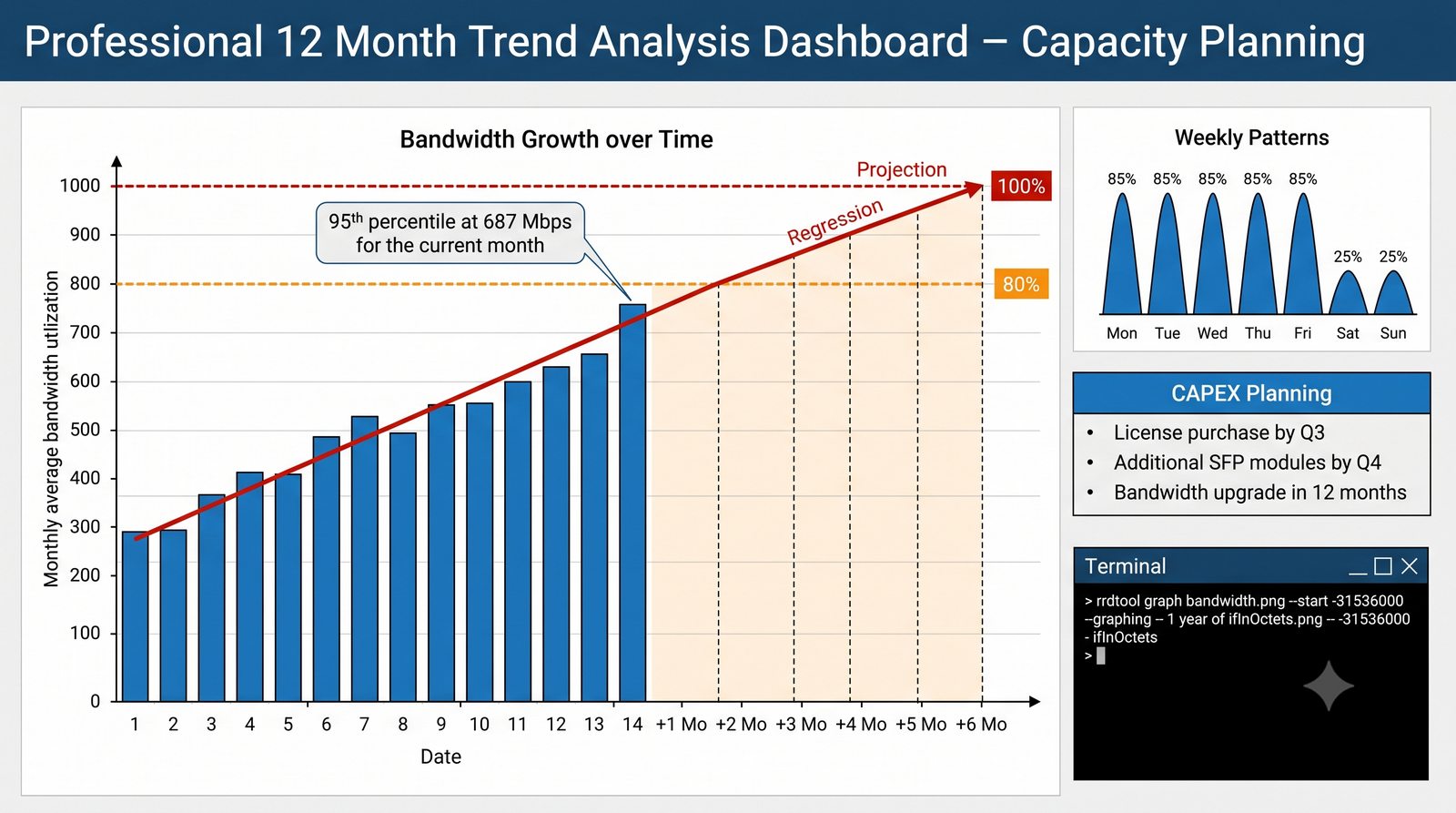
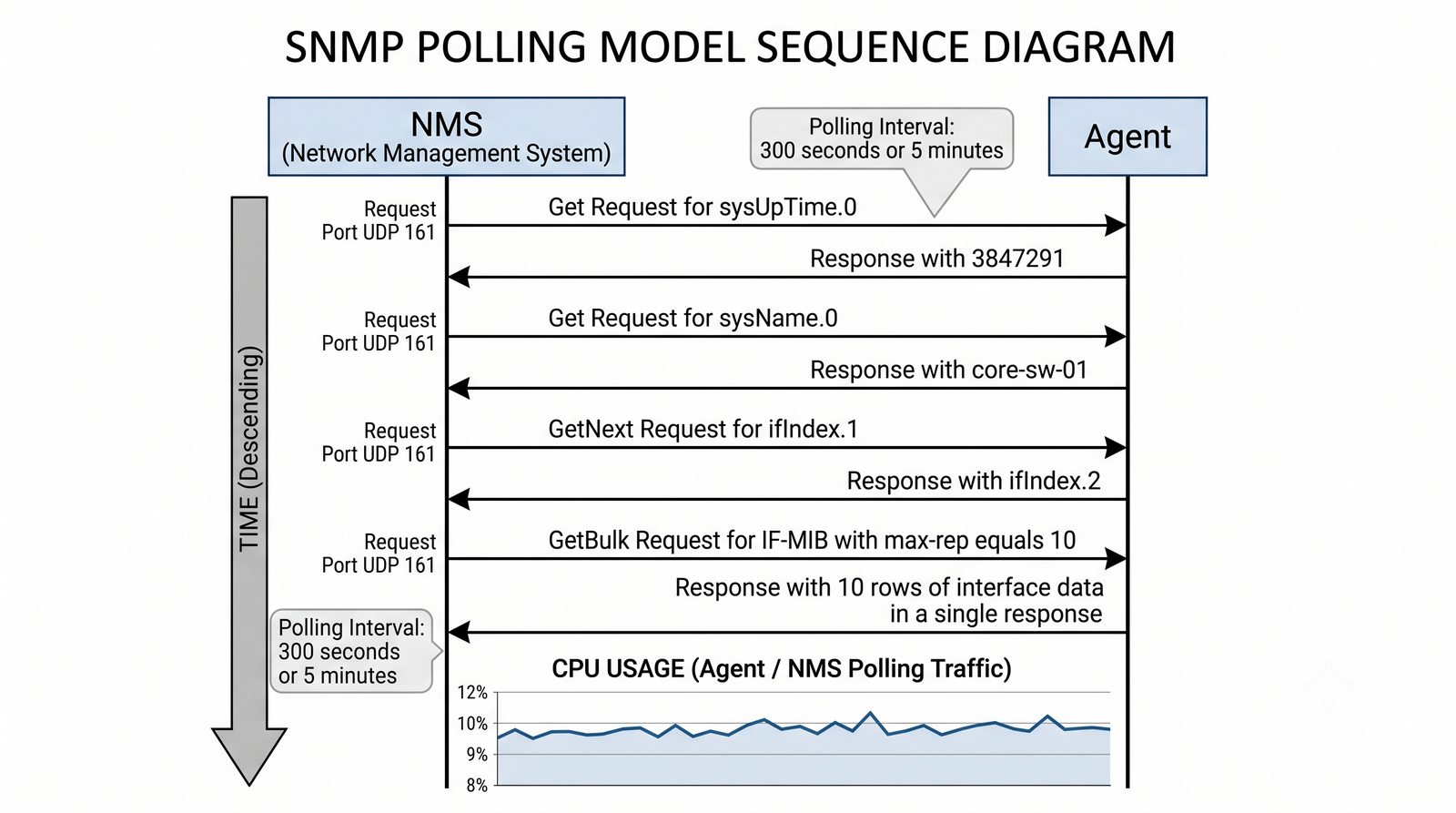
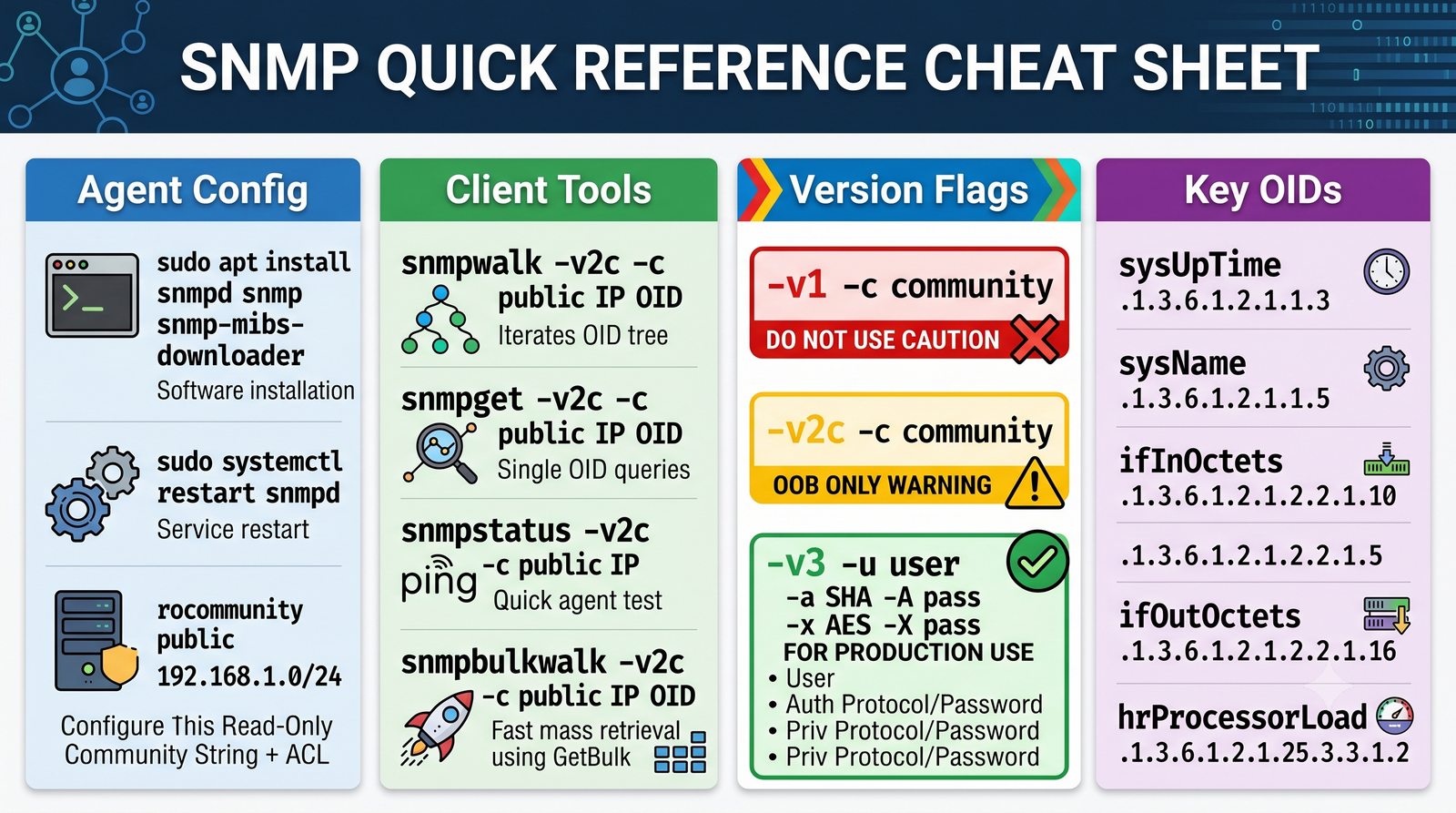
Zakladka Graphs to centrum analizy danych. LibreNMS automatycznie generuje wykresy dla: obciążenia CPU (w procentach), ruchu na interfejsach (bps), temperatury wewnętrznej (°C), zużycia pamięci, obciążenia łącza w percentylu 95. Wykresy można przeglądać w skali: 1 godzina, 6 godzin, 24 godziny, 7 dni, 30 dni, 1 rok.
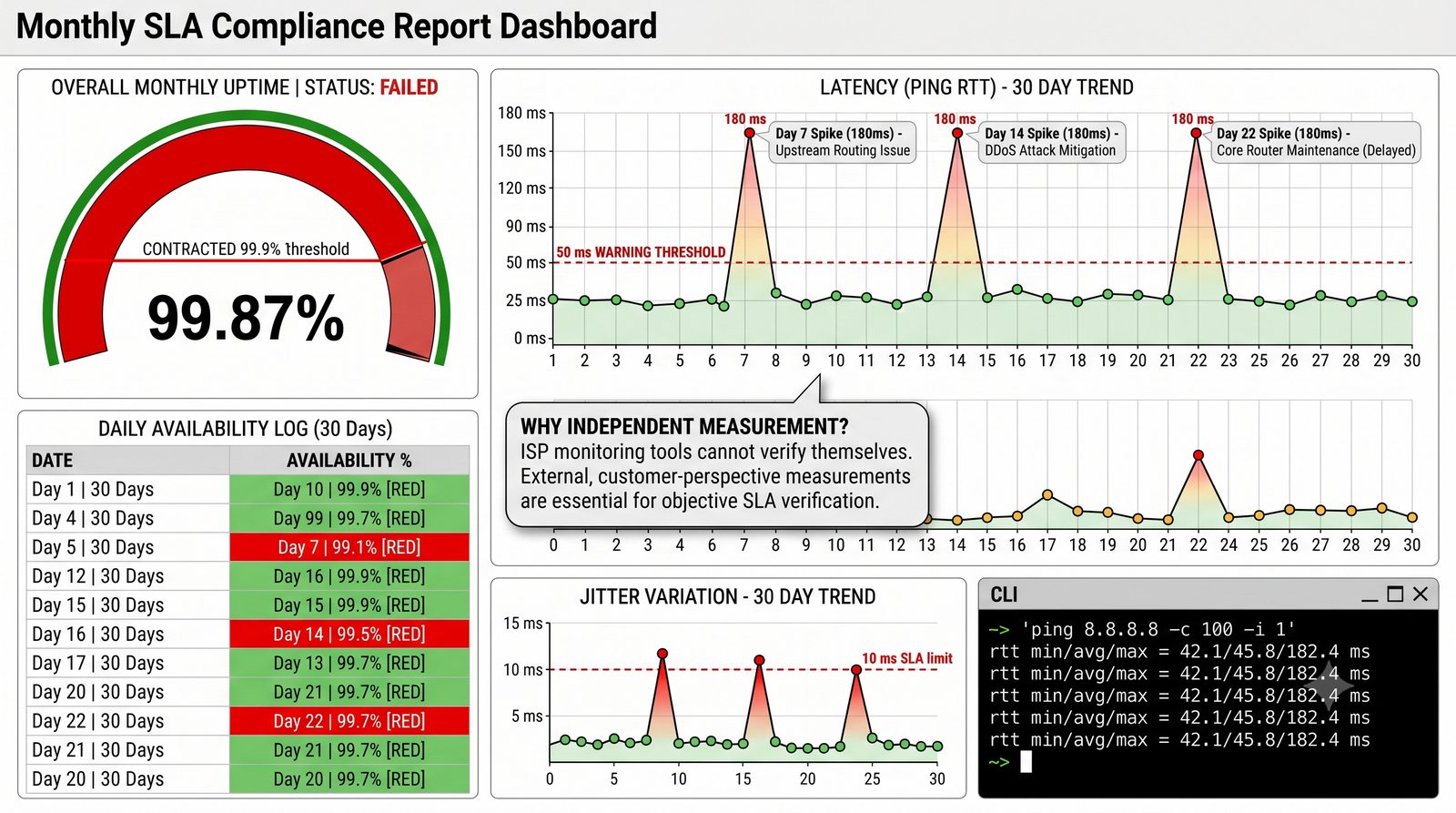
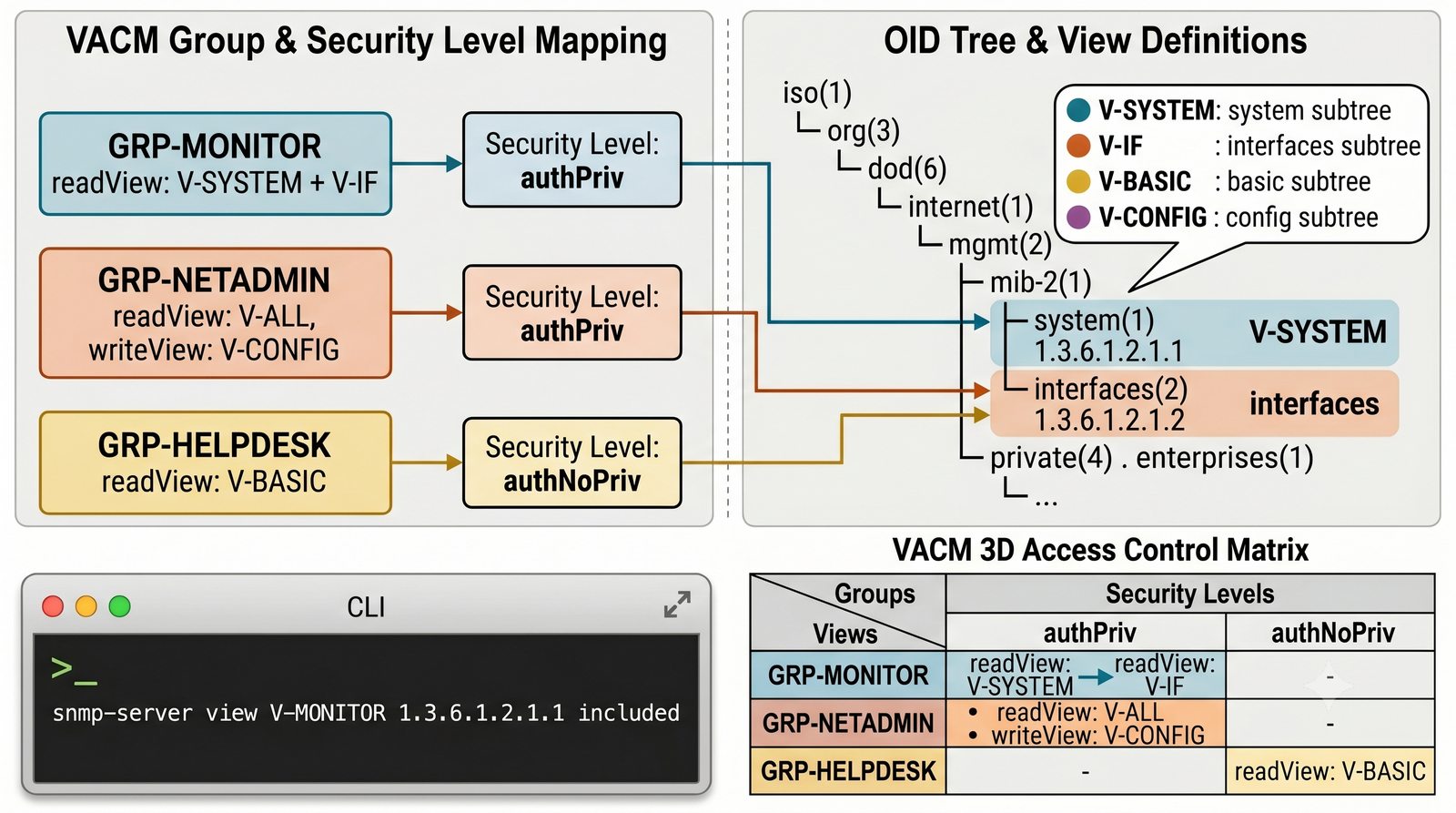
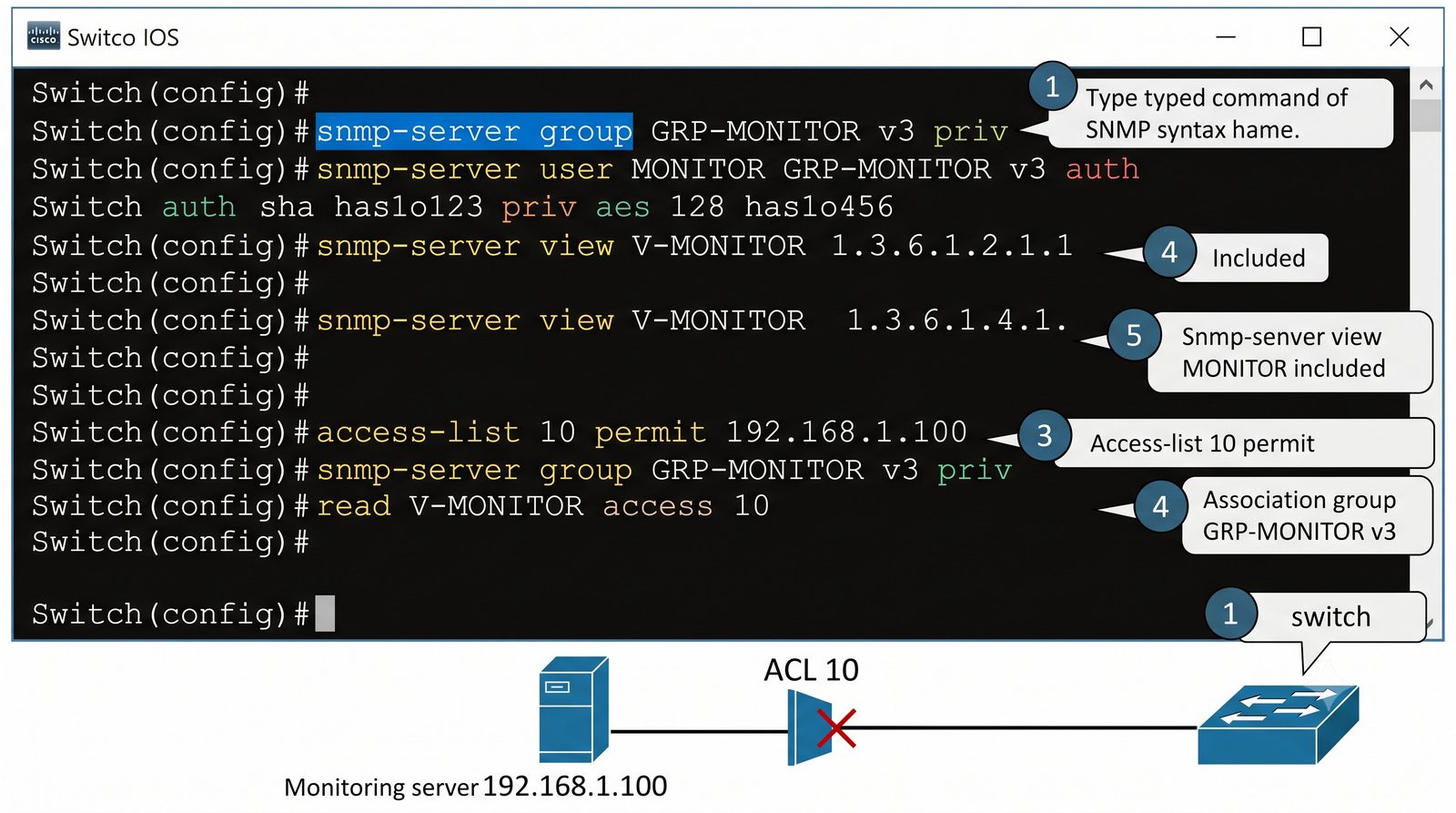
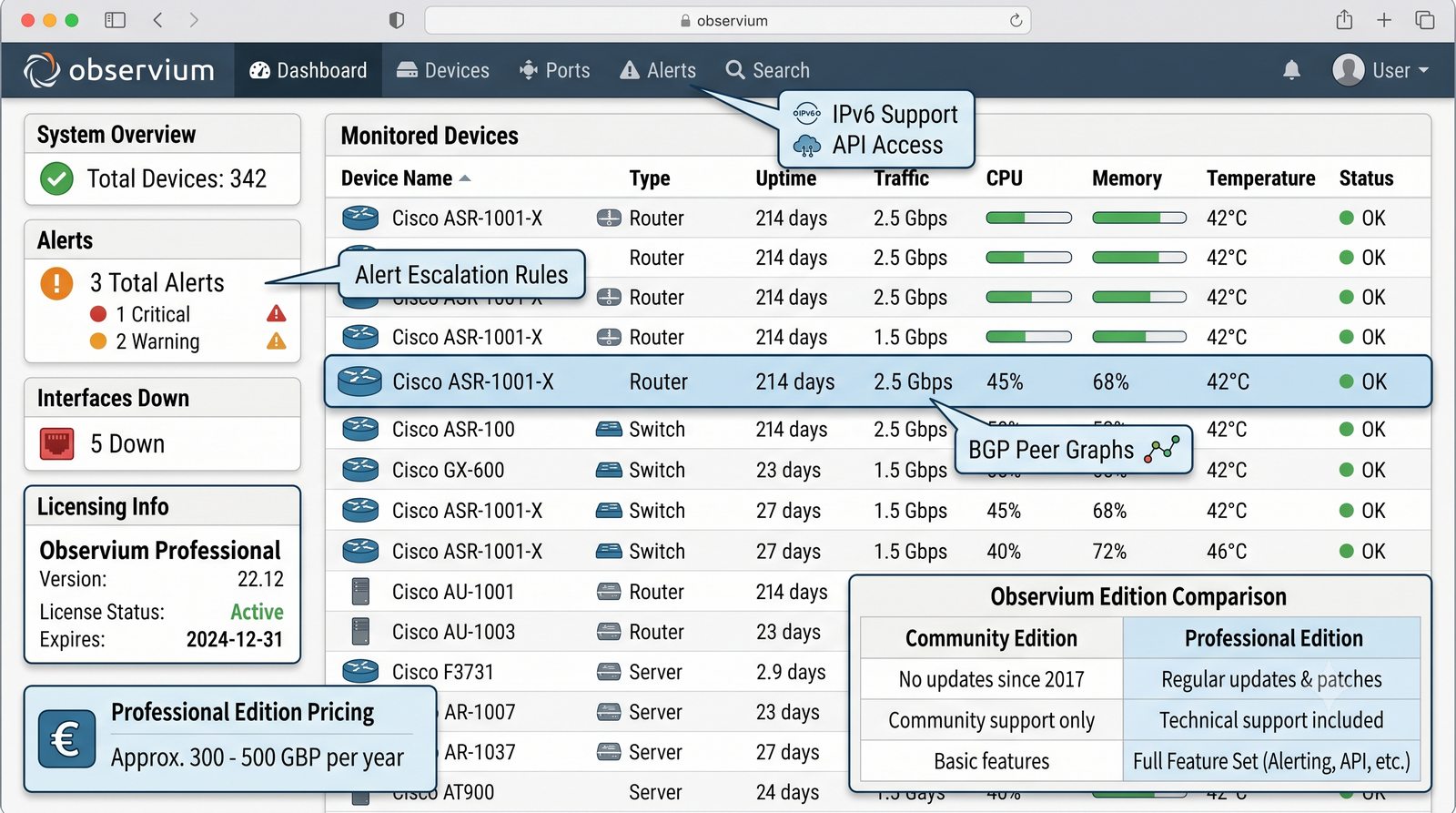
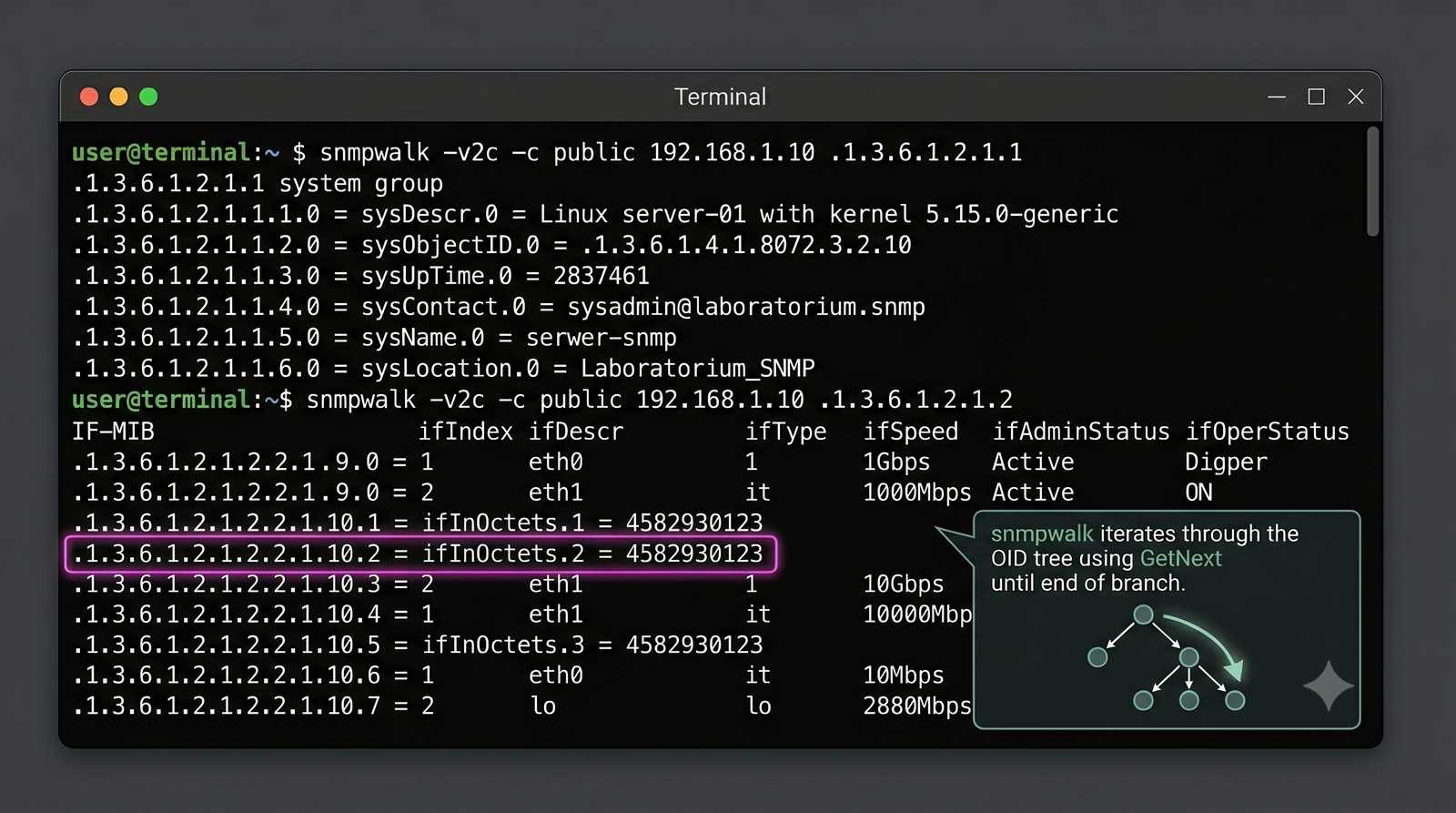
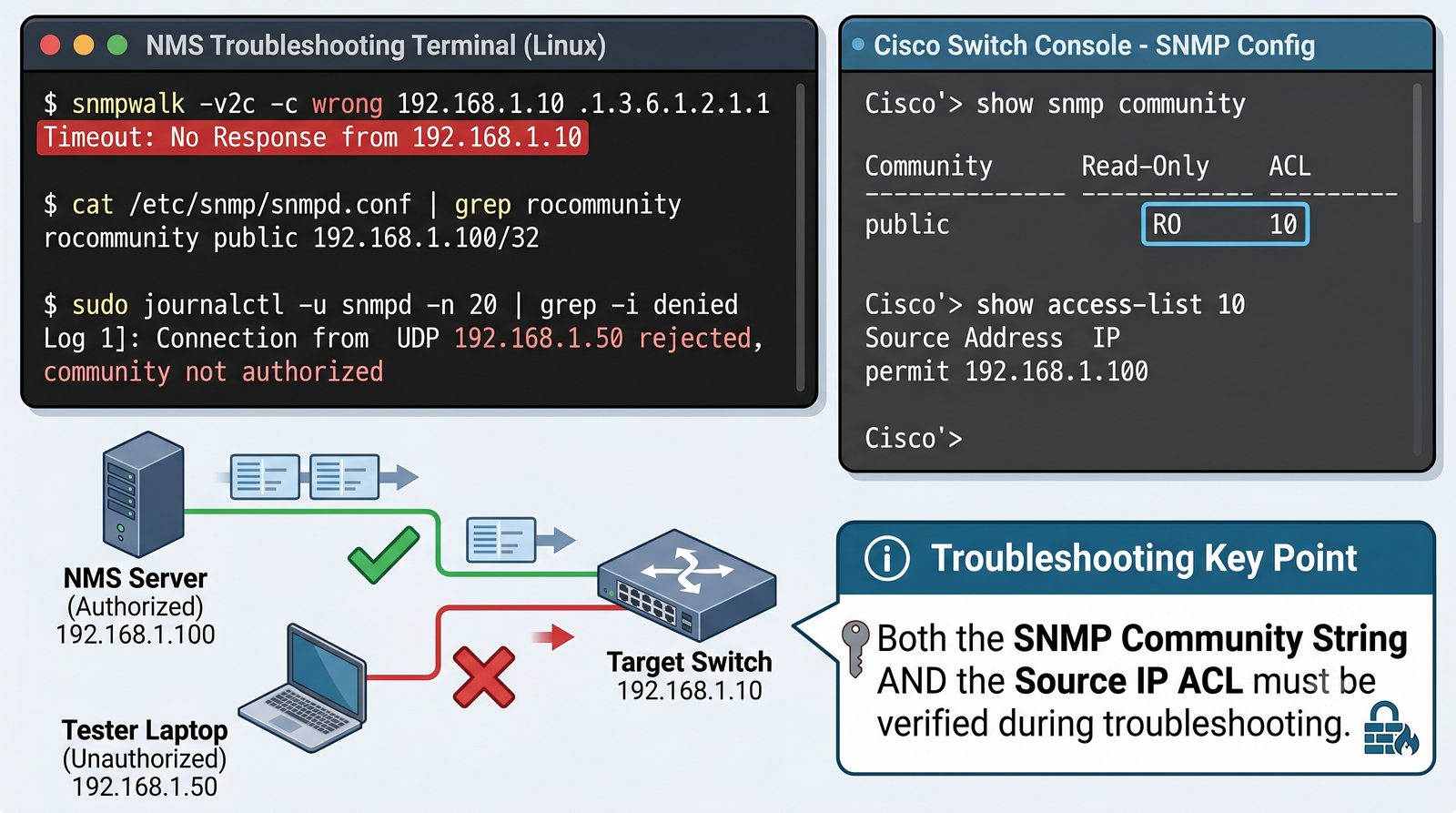
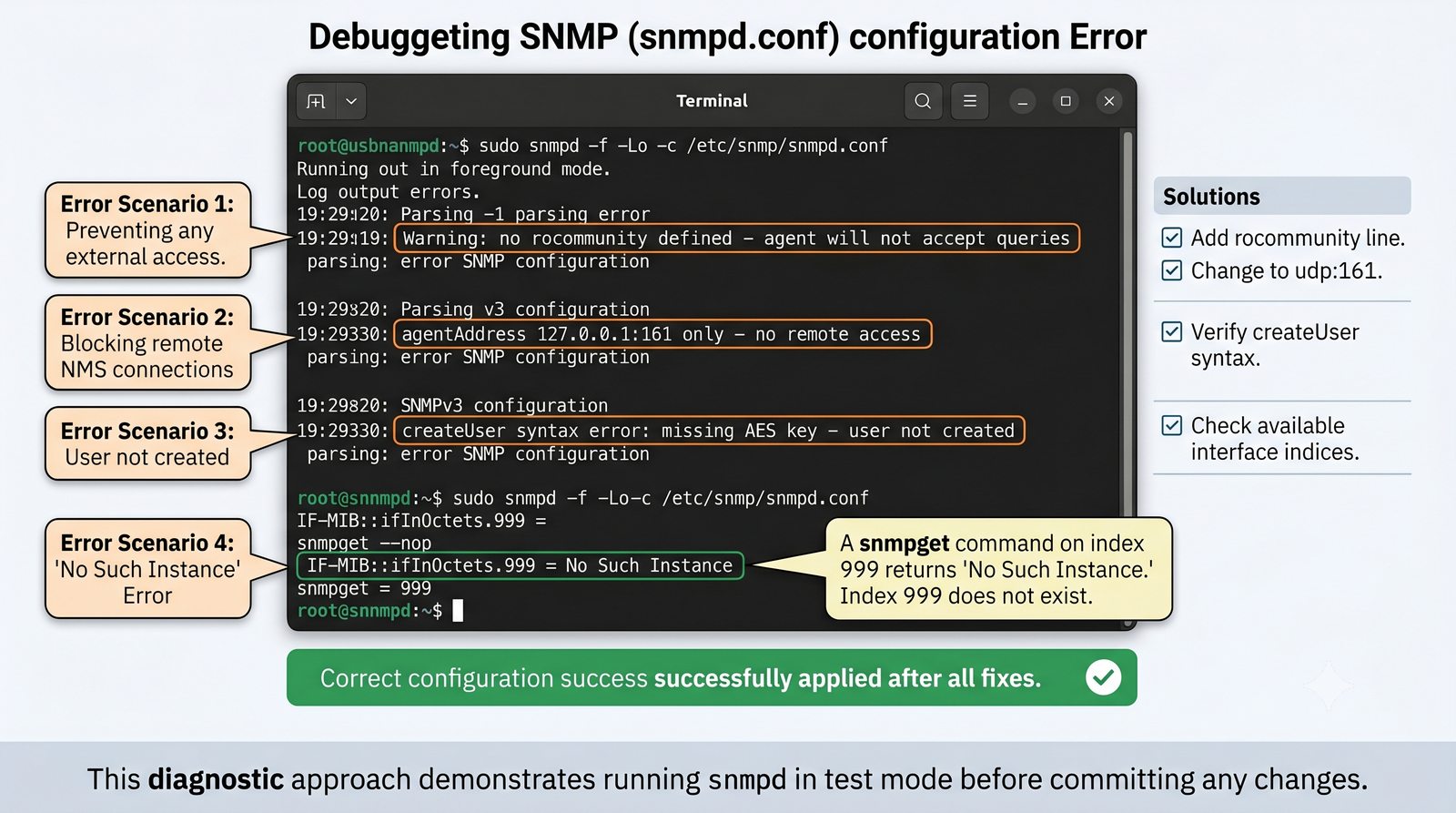
Zakladka Ports wyświetla liste wszystkich interfejsów urządzenia z informacja o statusie administracyjnym (up/down) i operacyjnym (up/down), obciążeniu w bps oraz liczbie błędów. Interfejsy z błądami są podświetlane na czerwono, co ułatwia szybka identyfikację problemów.
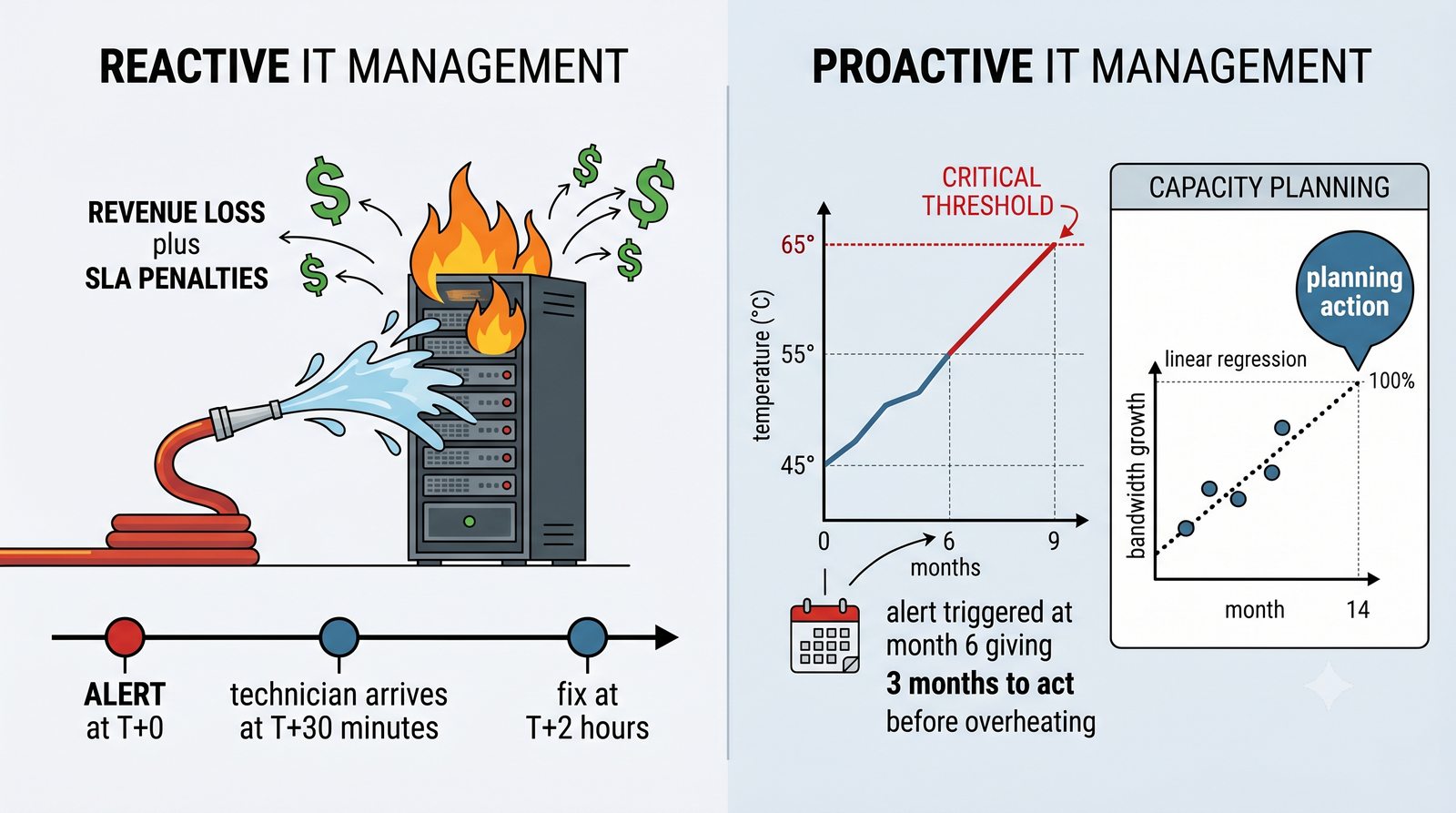
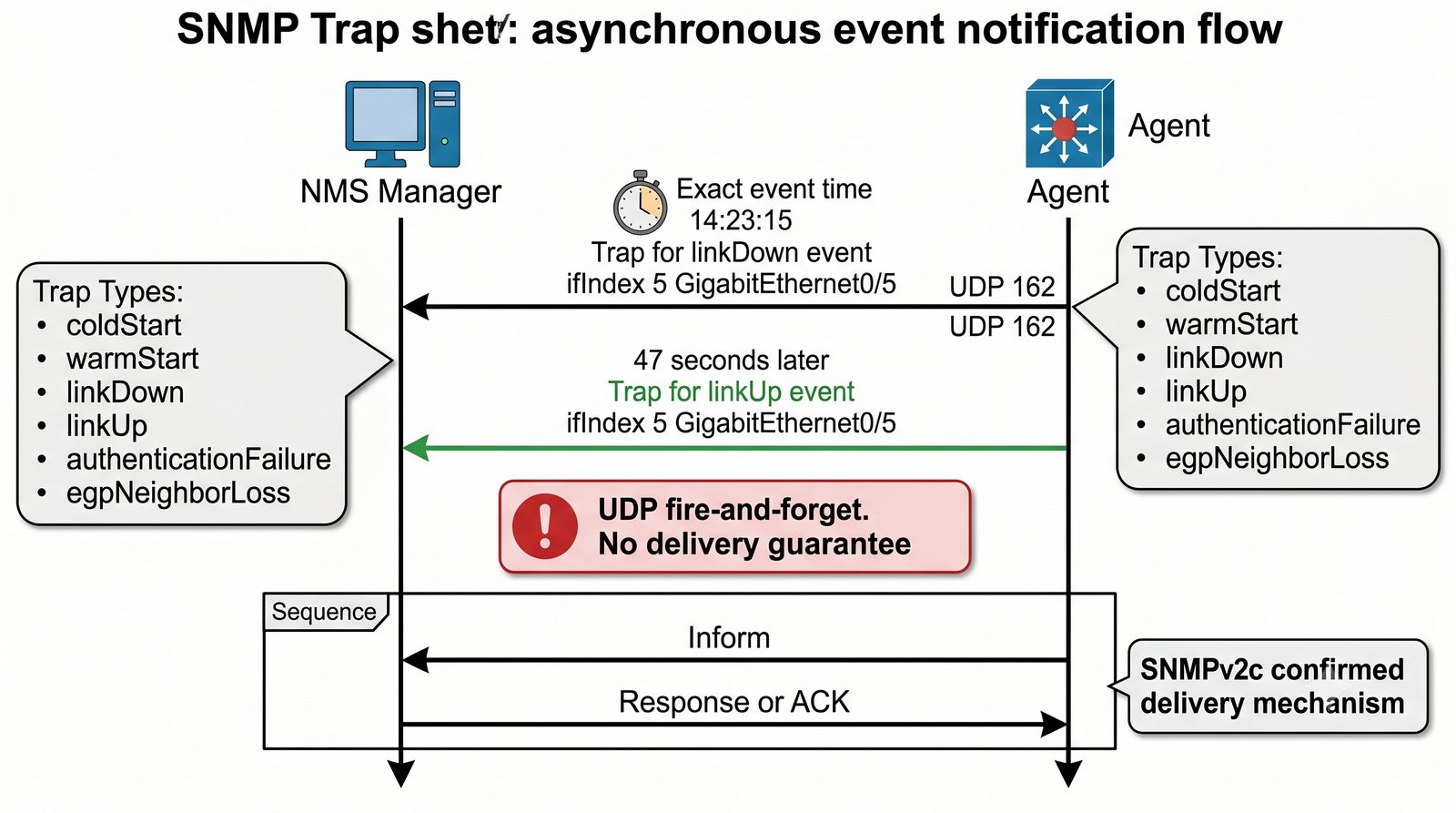
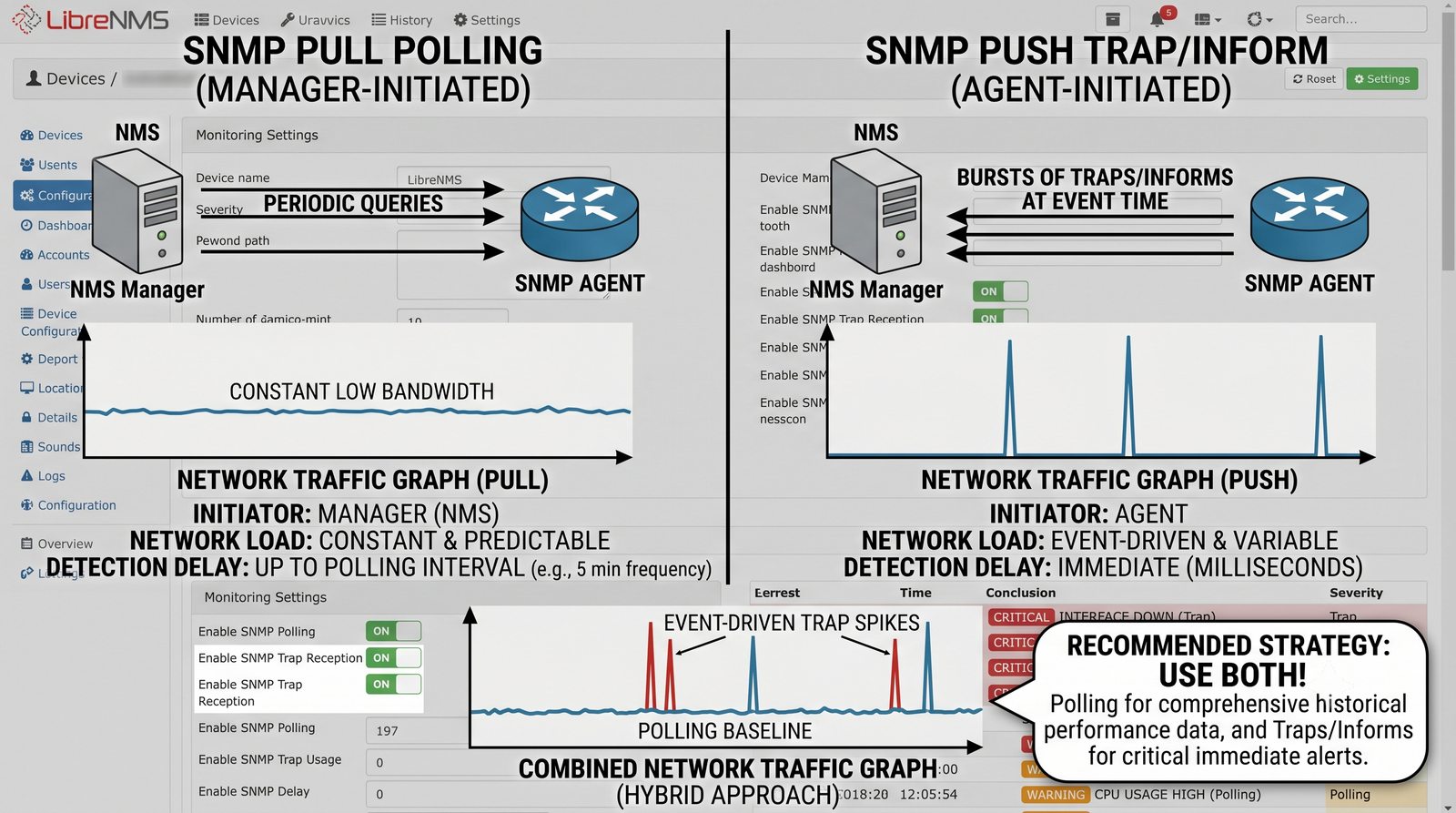
Dashboard to konfigurowalny panel, na który można dodać dowolne wykresy z różnych urządzeń. Typowy dashboard inżyniera sieciowego zawiera: ogólny status wszystkich urządzeń (global summary), wykres obciążenia łącza internetowego, temperaturę w serwerowni, liste ostatnich alertów oraz mape sieci.