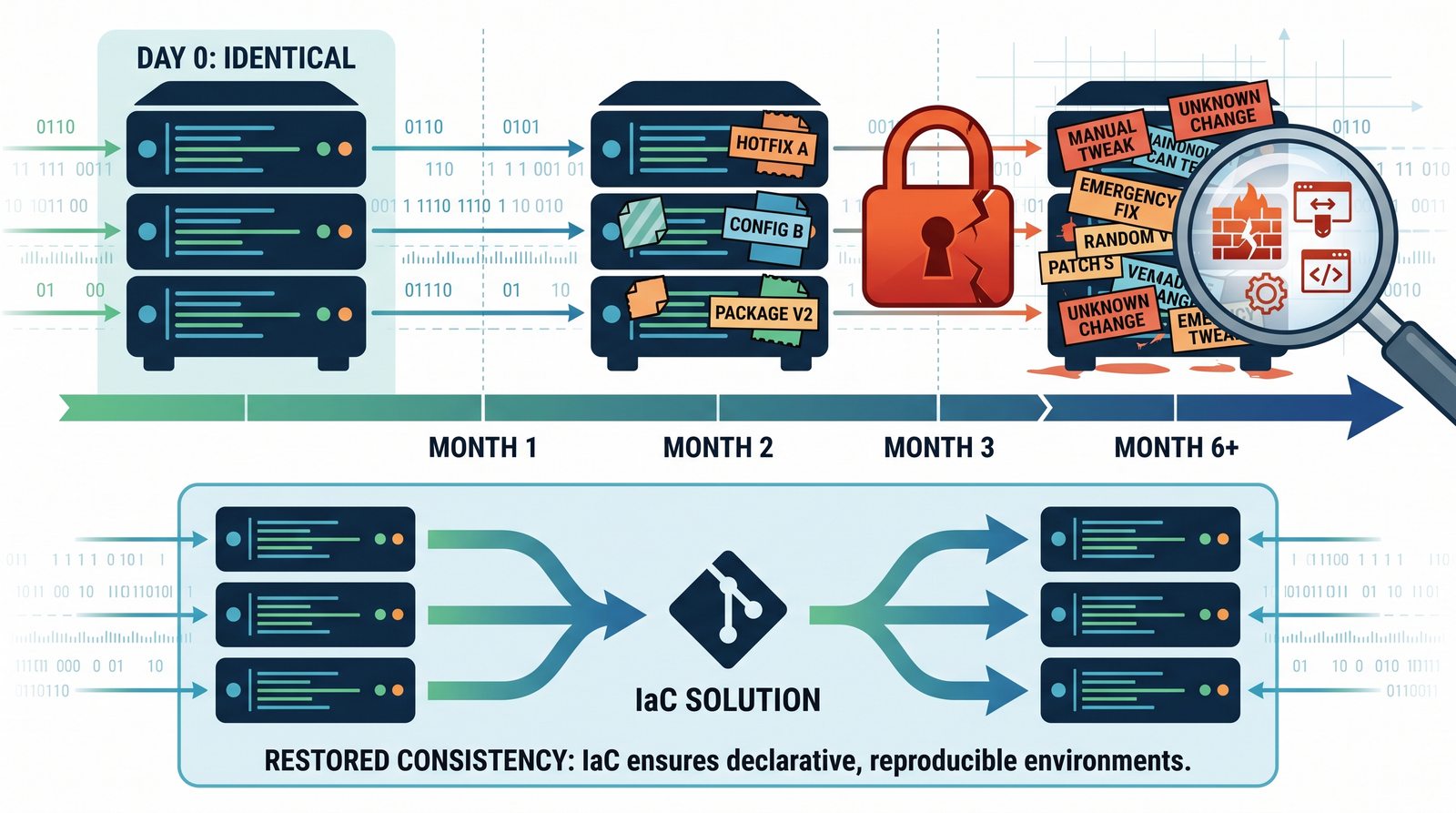
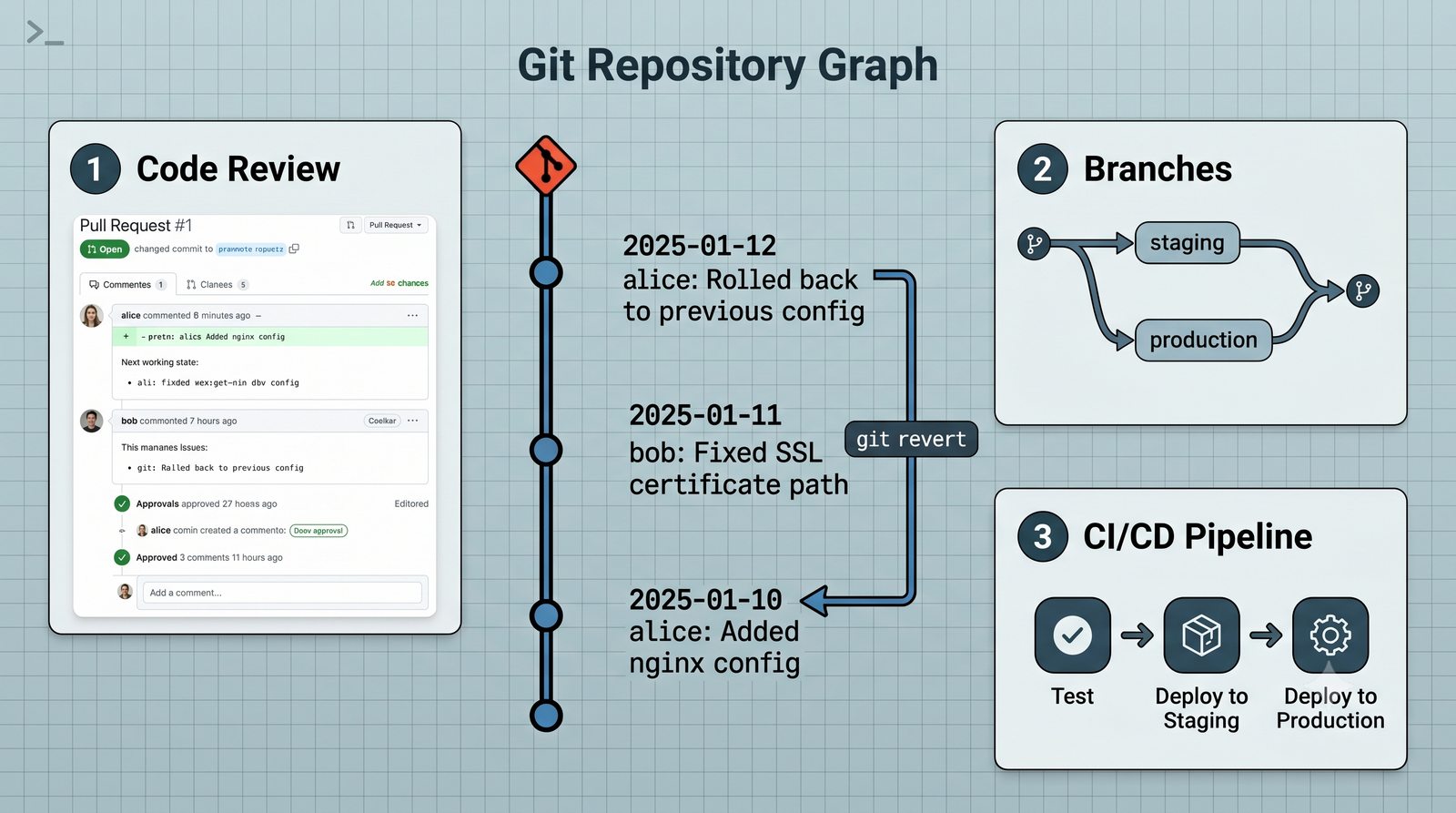
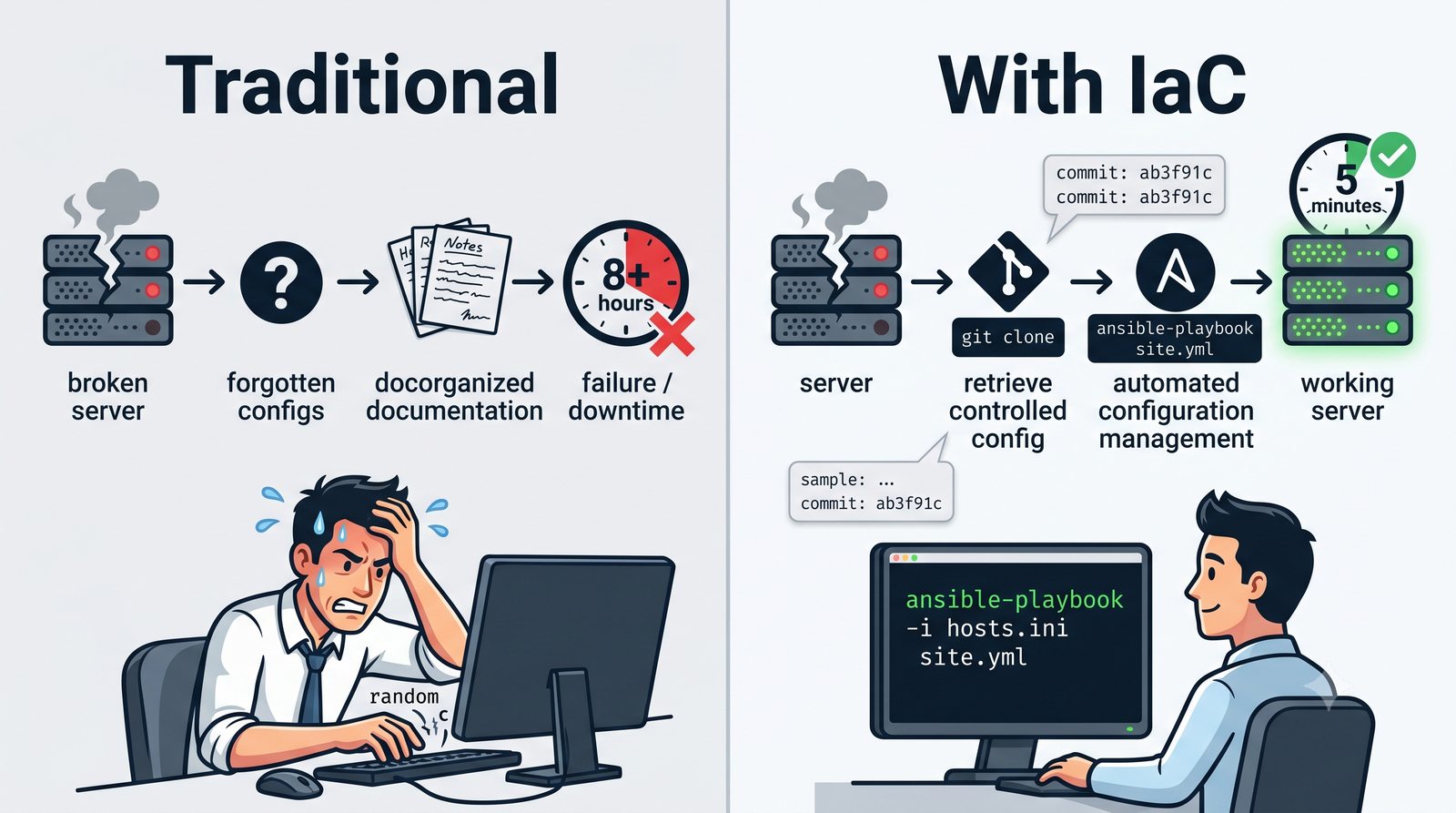
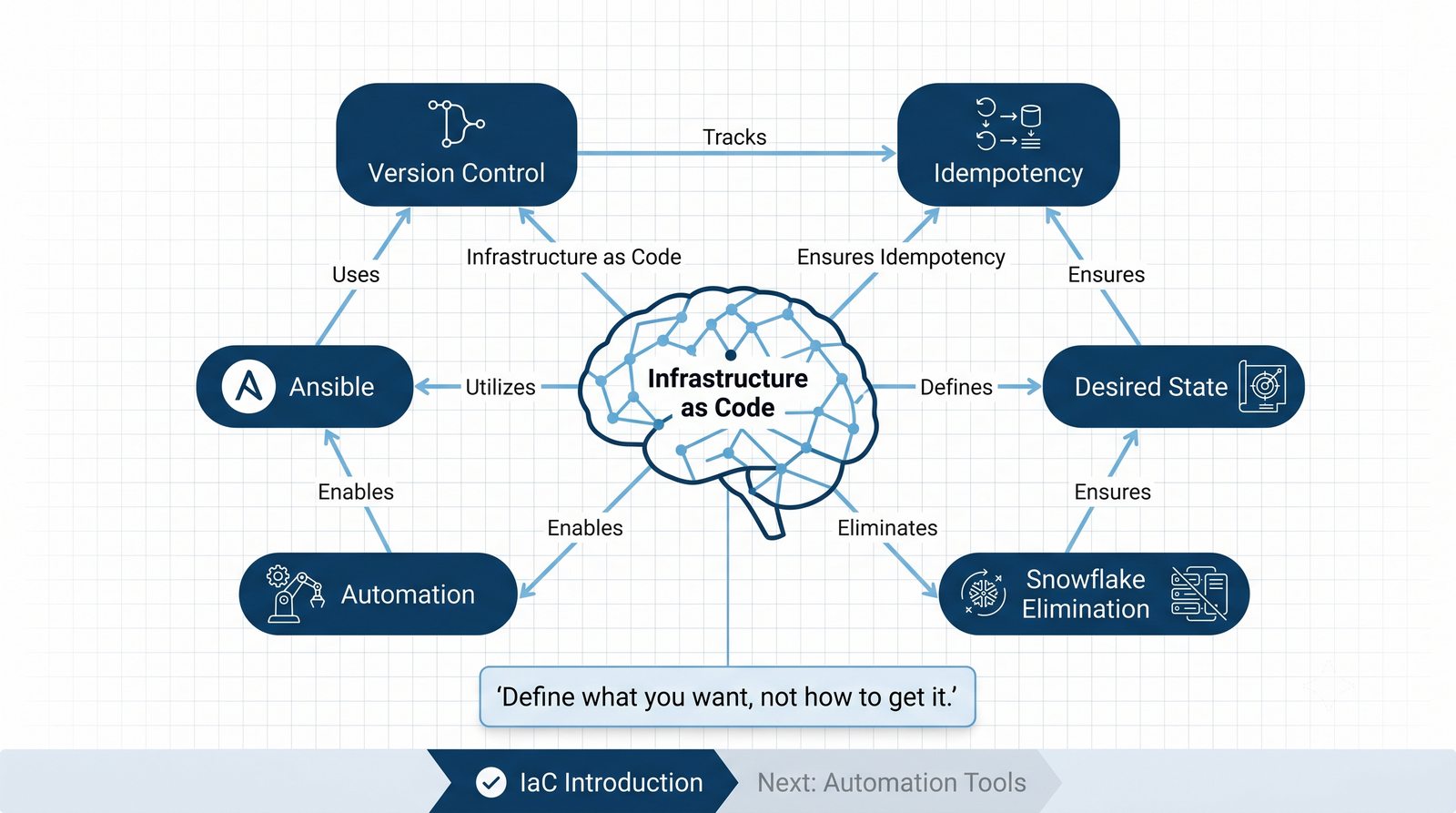
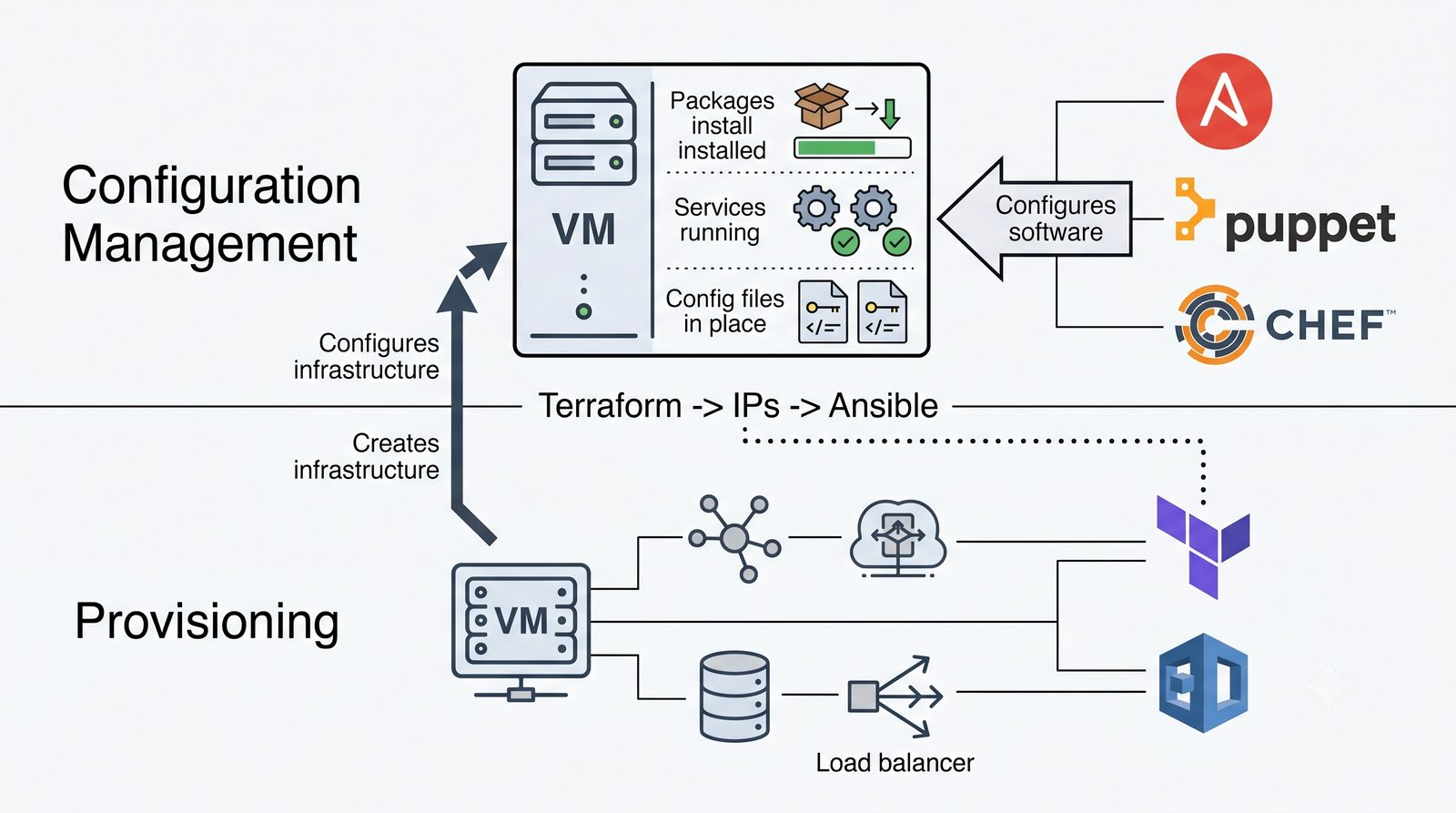
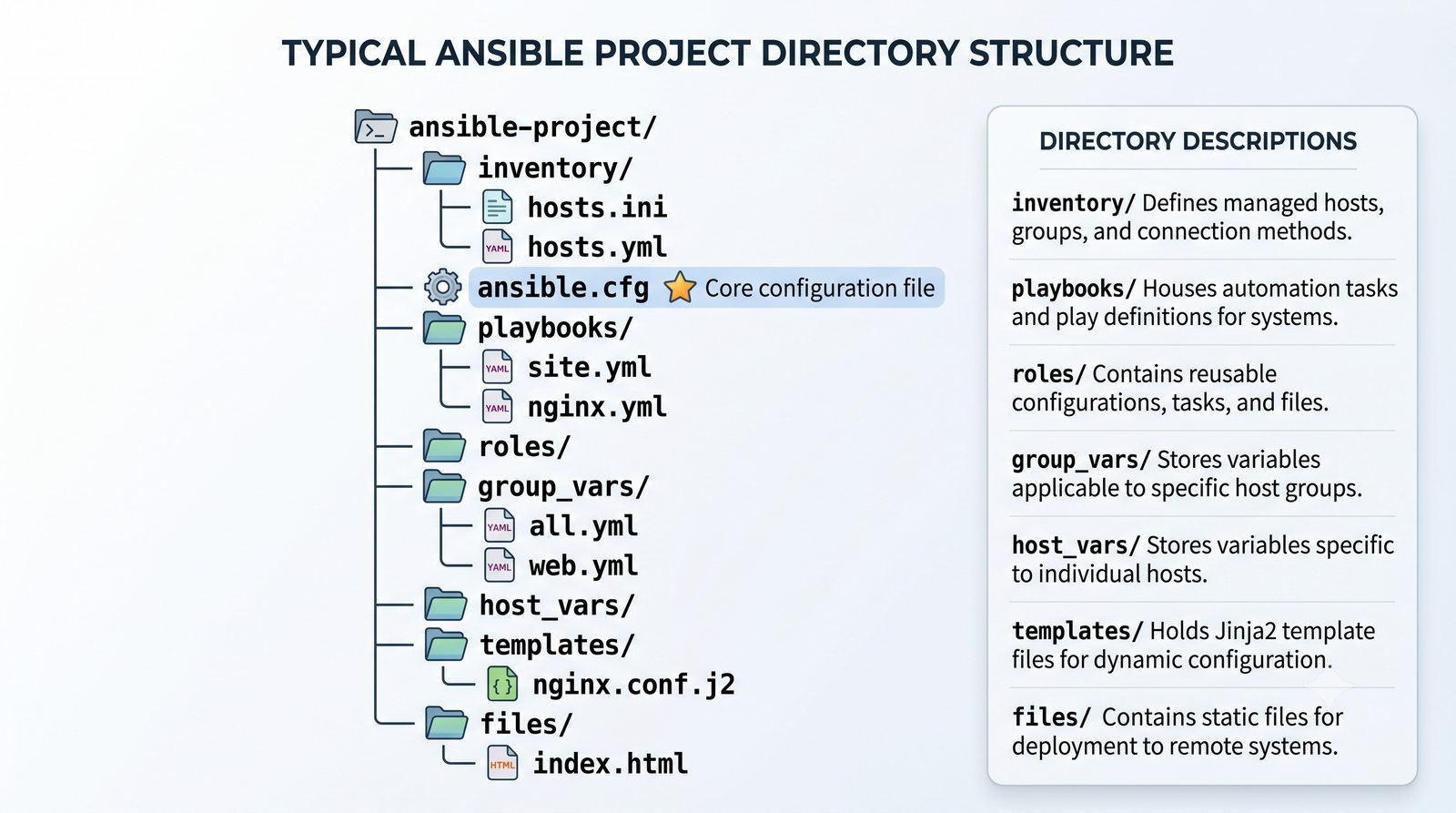
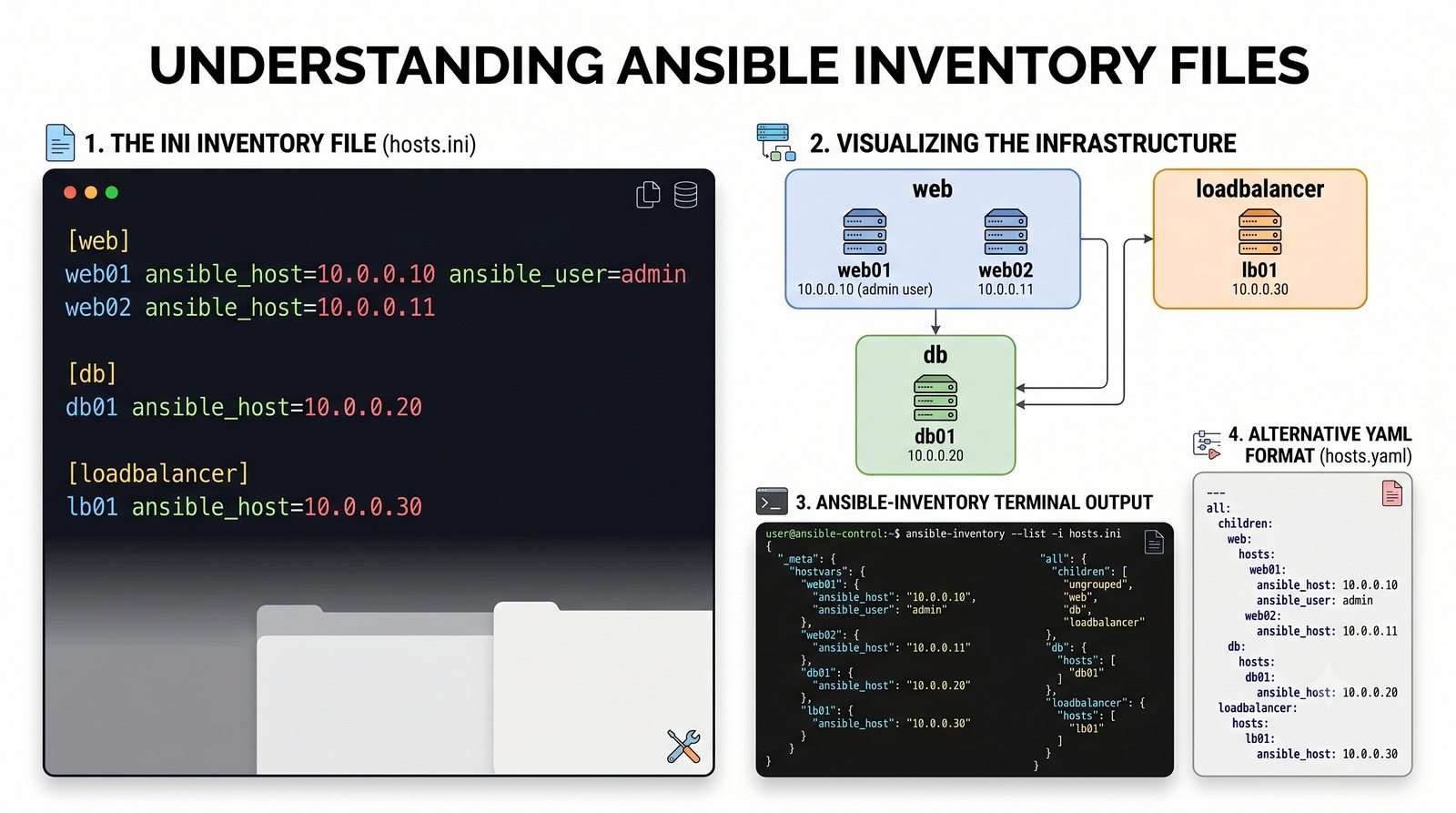
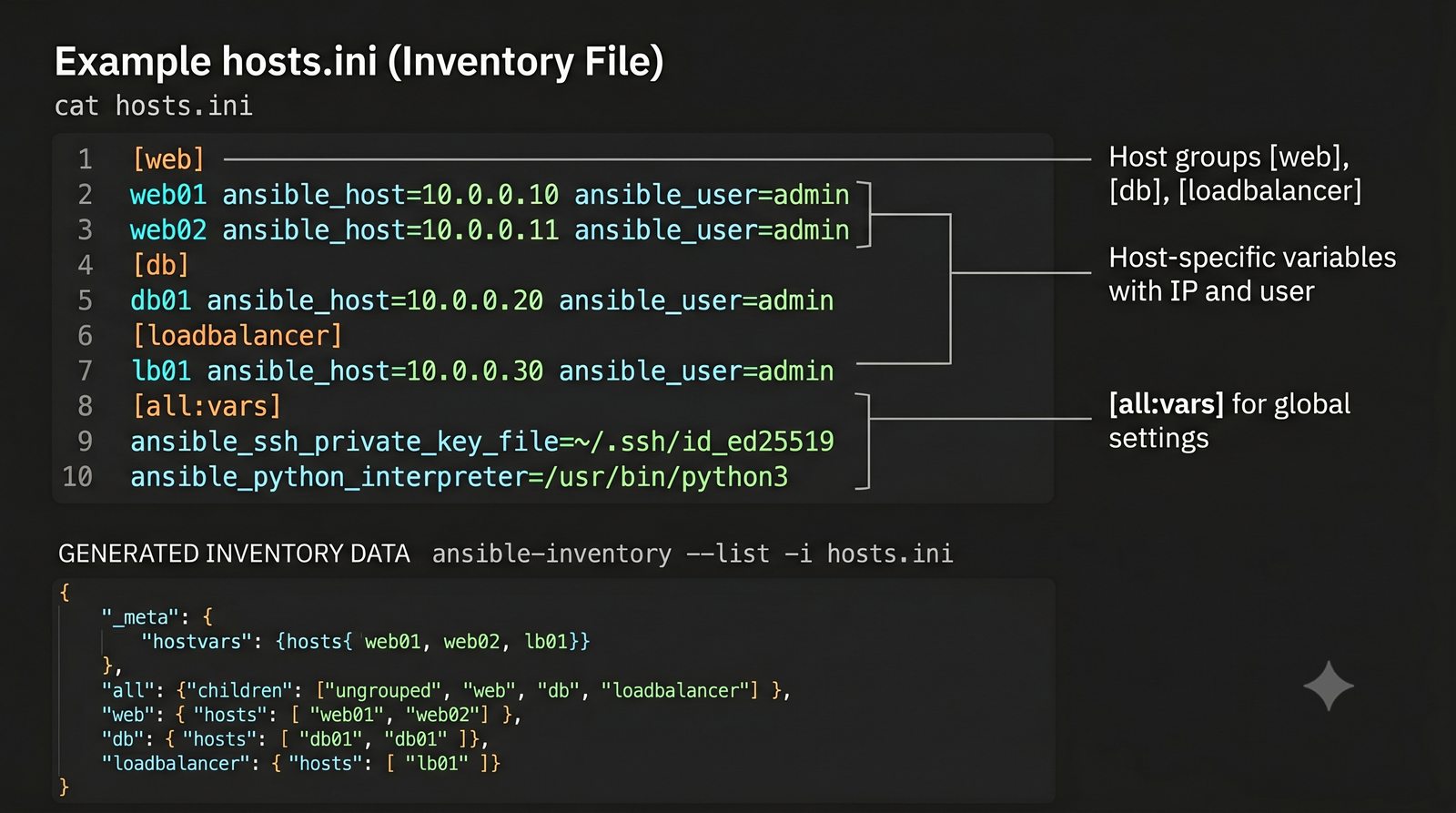
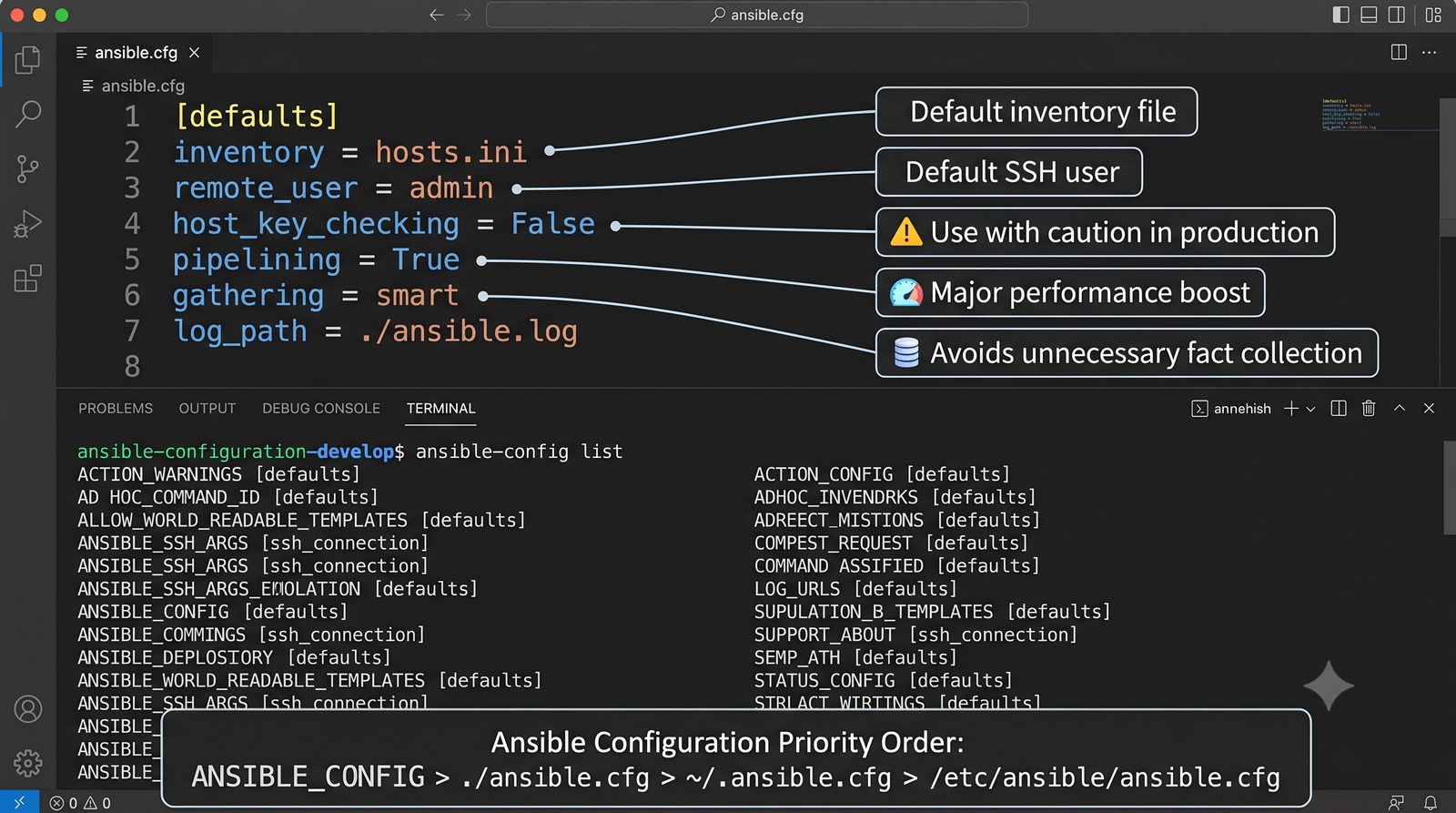
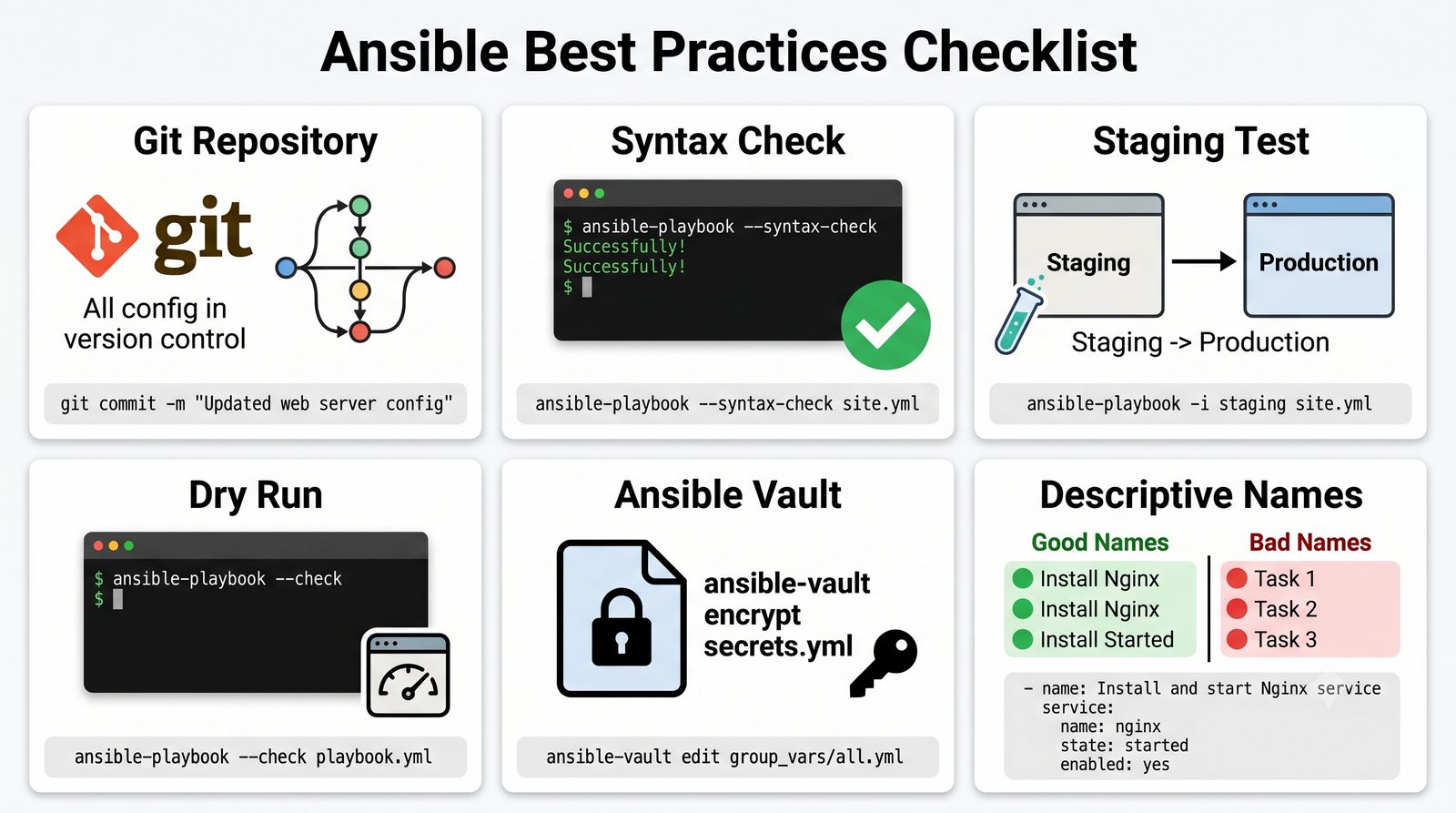
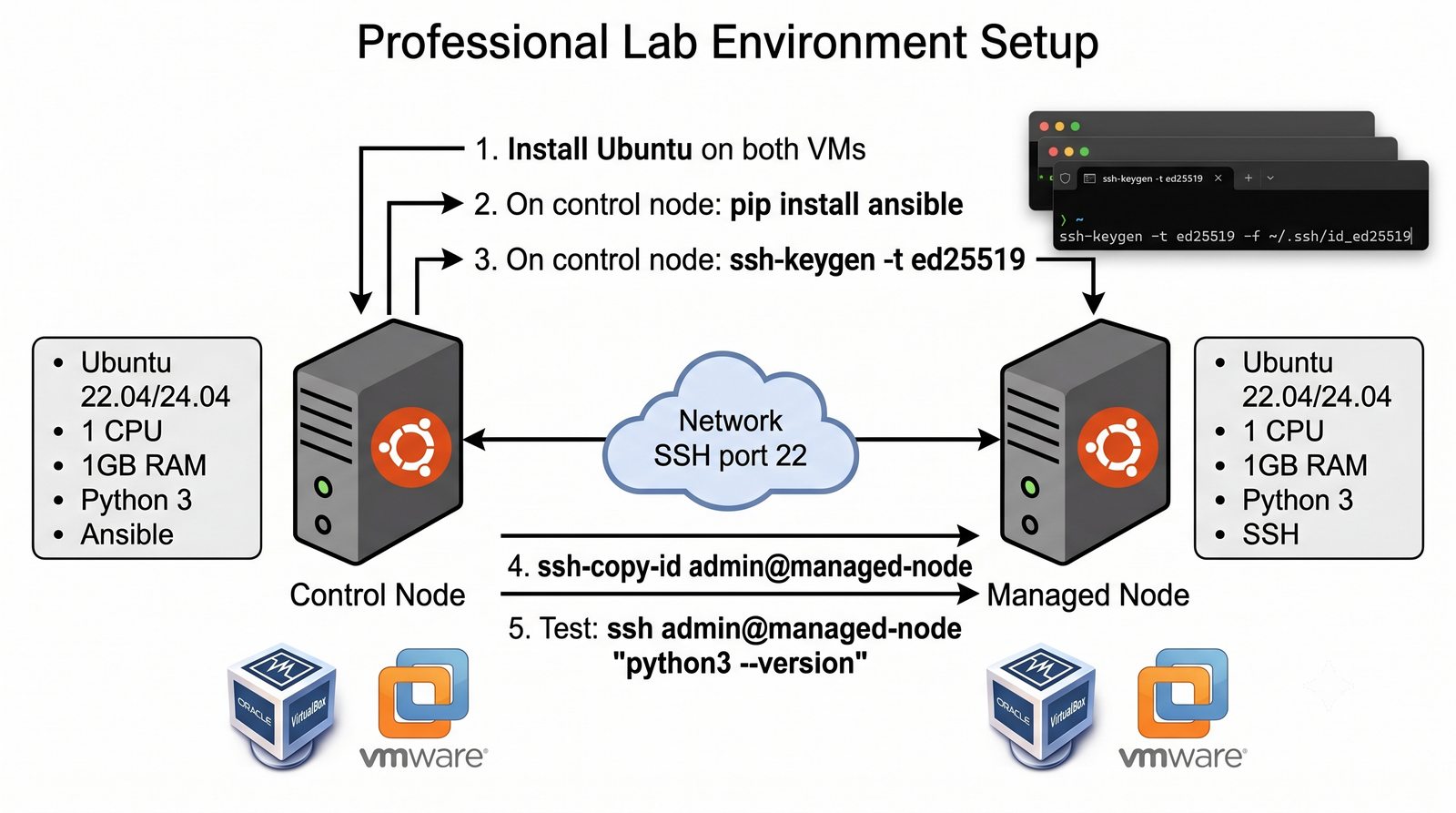
Infrastructure as Code (IaC) to paradygmat zarządzania infrastrukturą IT, w którym konfiguracja serwerów, sieci i usług jest definiowana w plikach deklaratywnych lub proceduralnych, przechowywanych w systemie kontroli wersji.
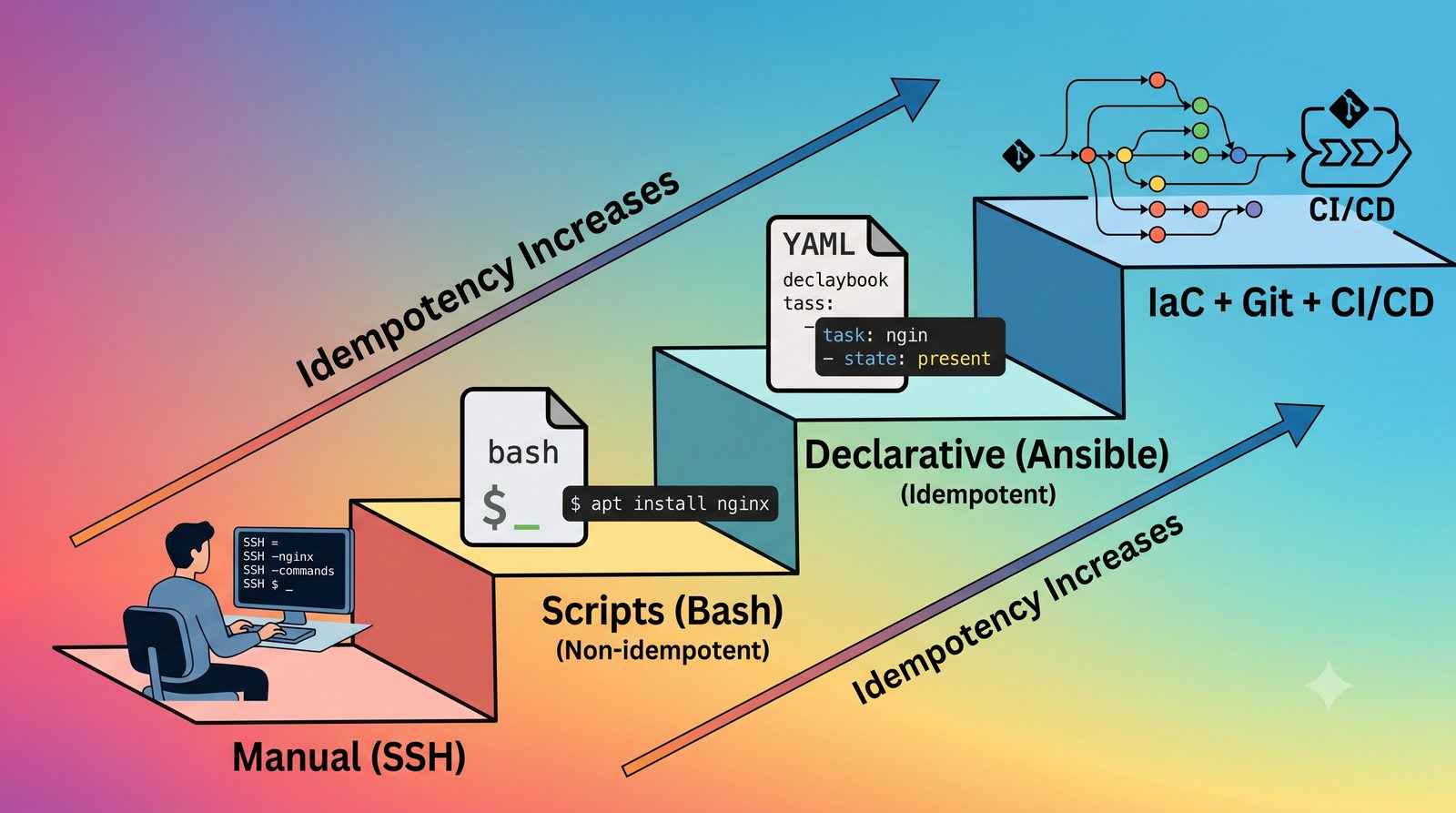
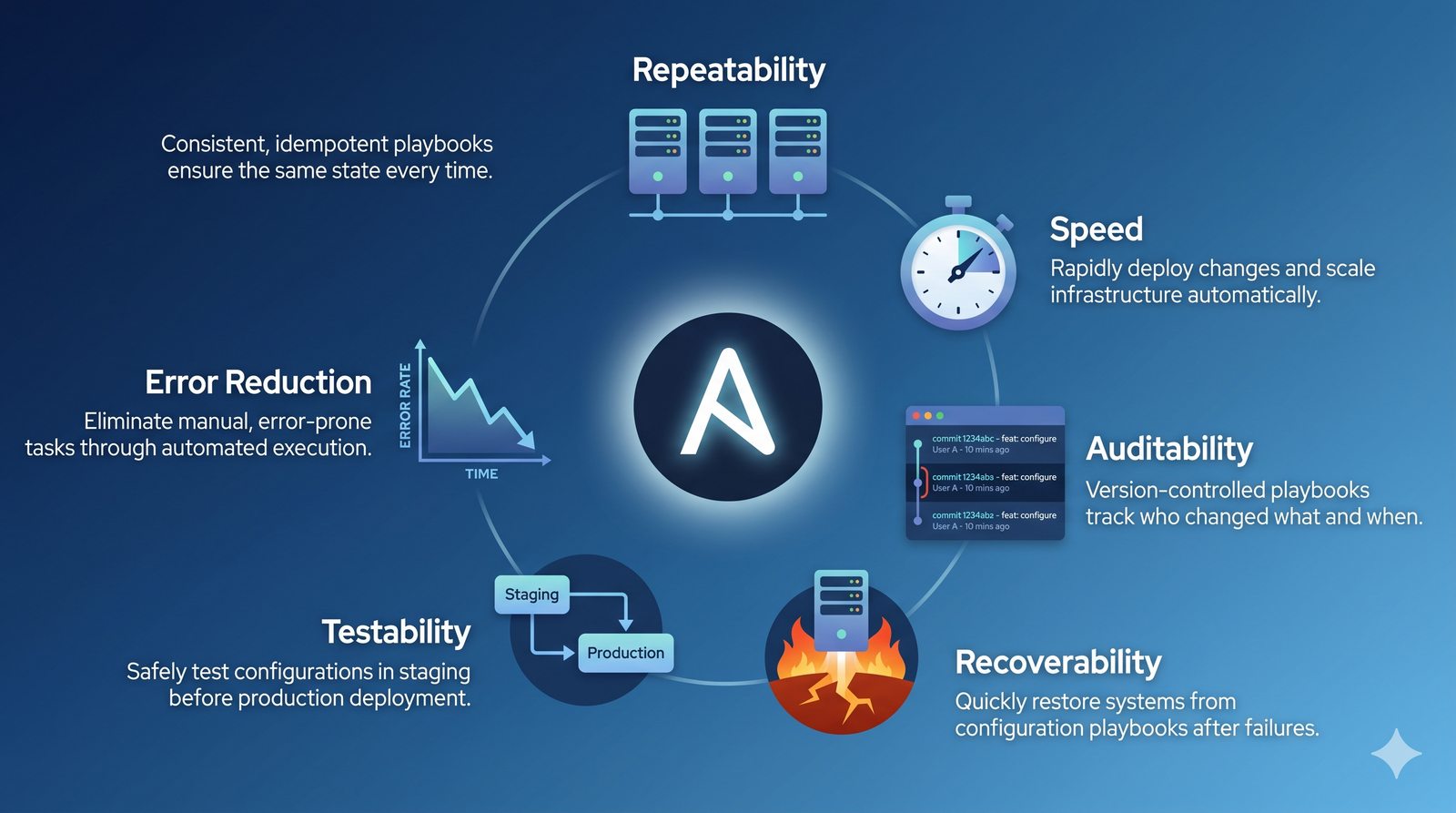
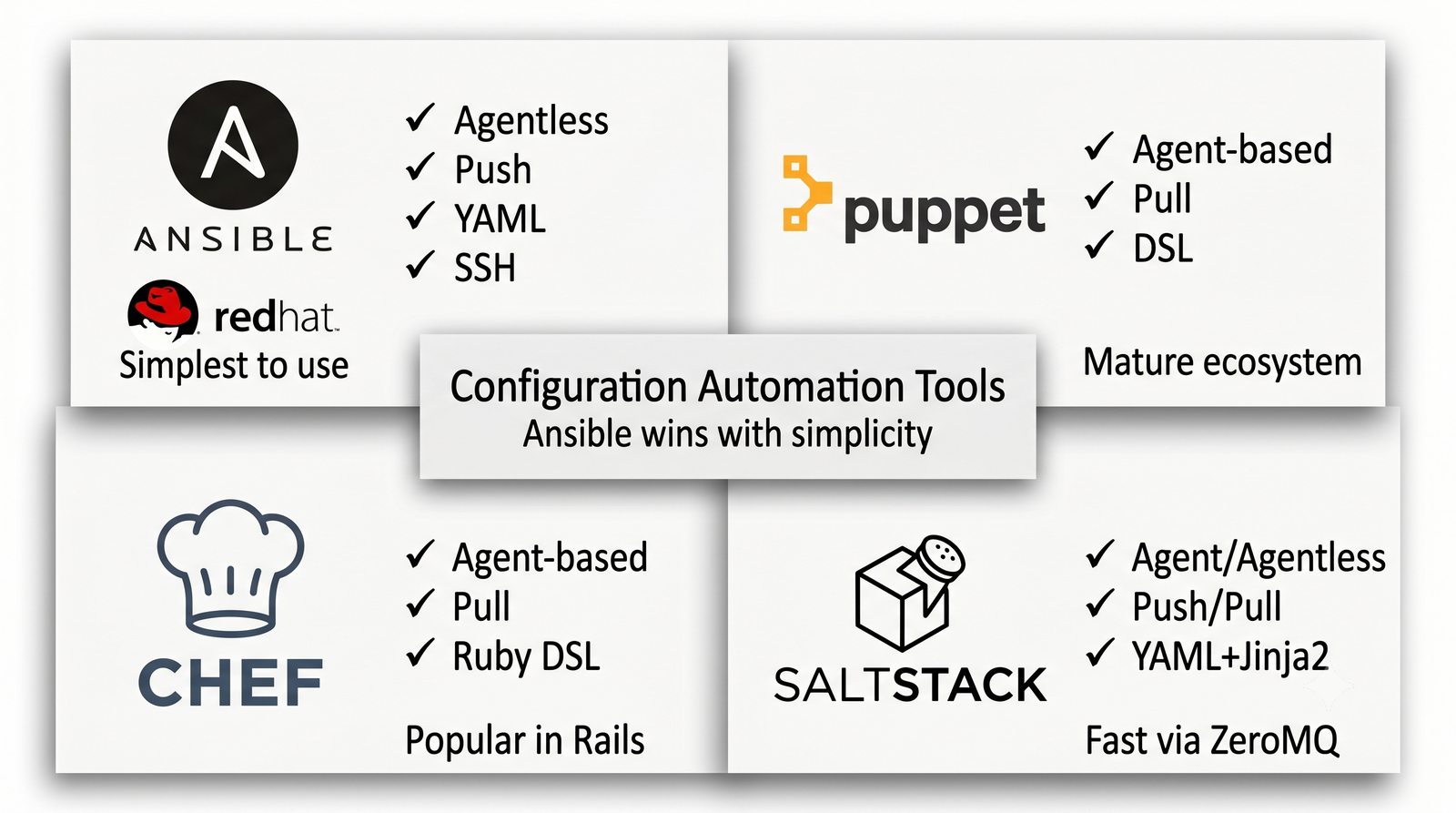
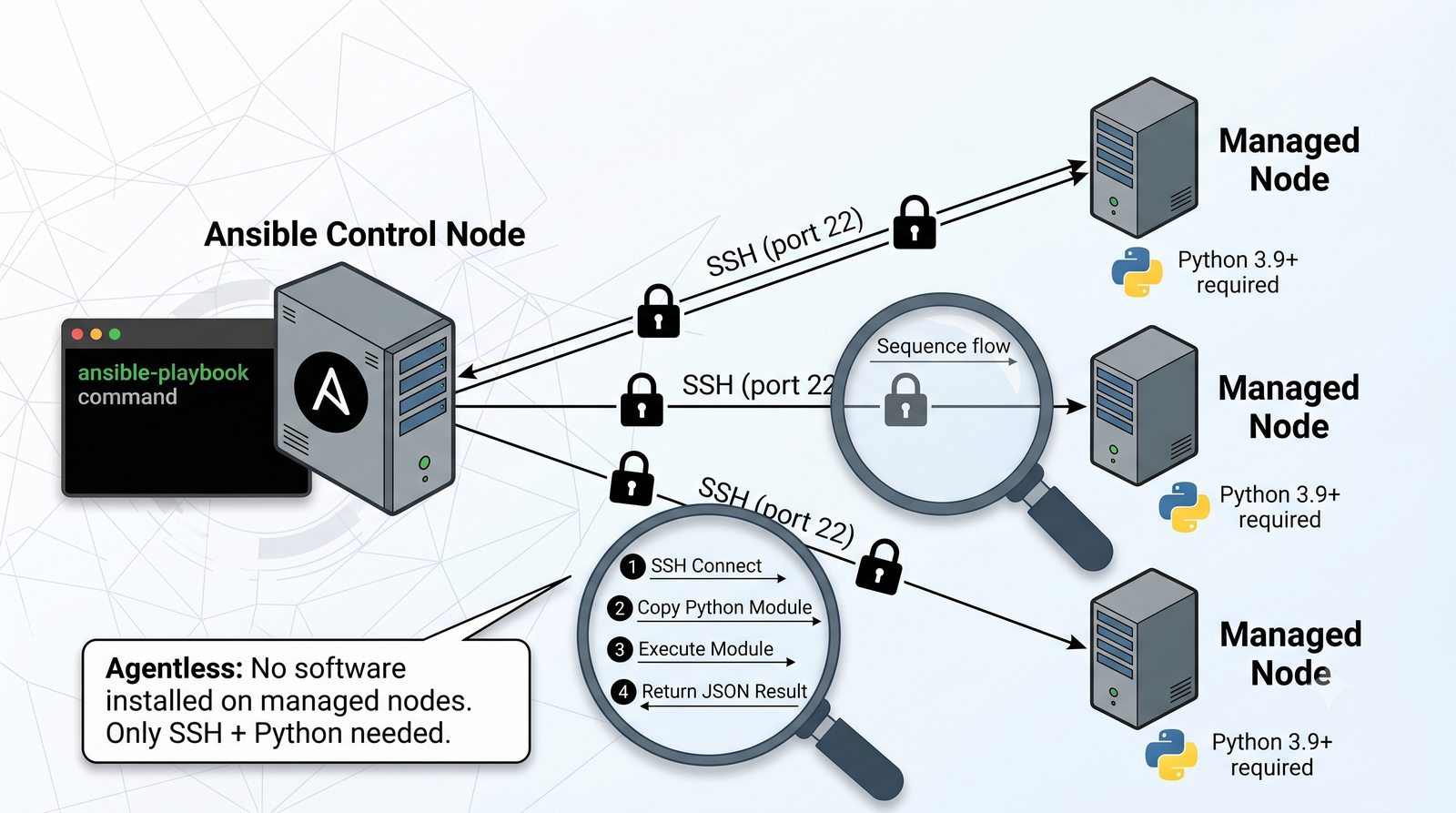
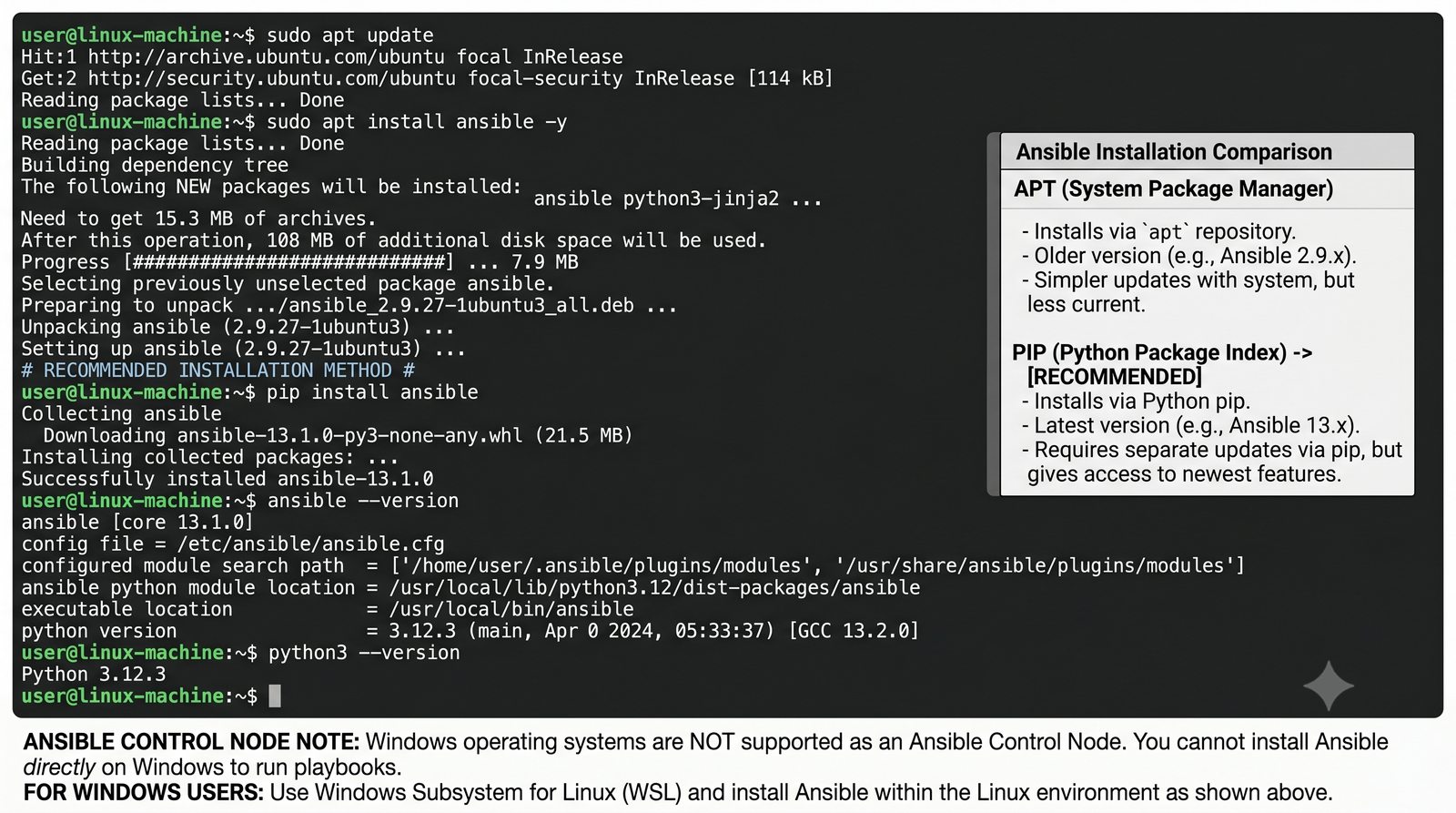
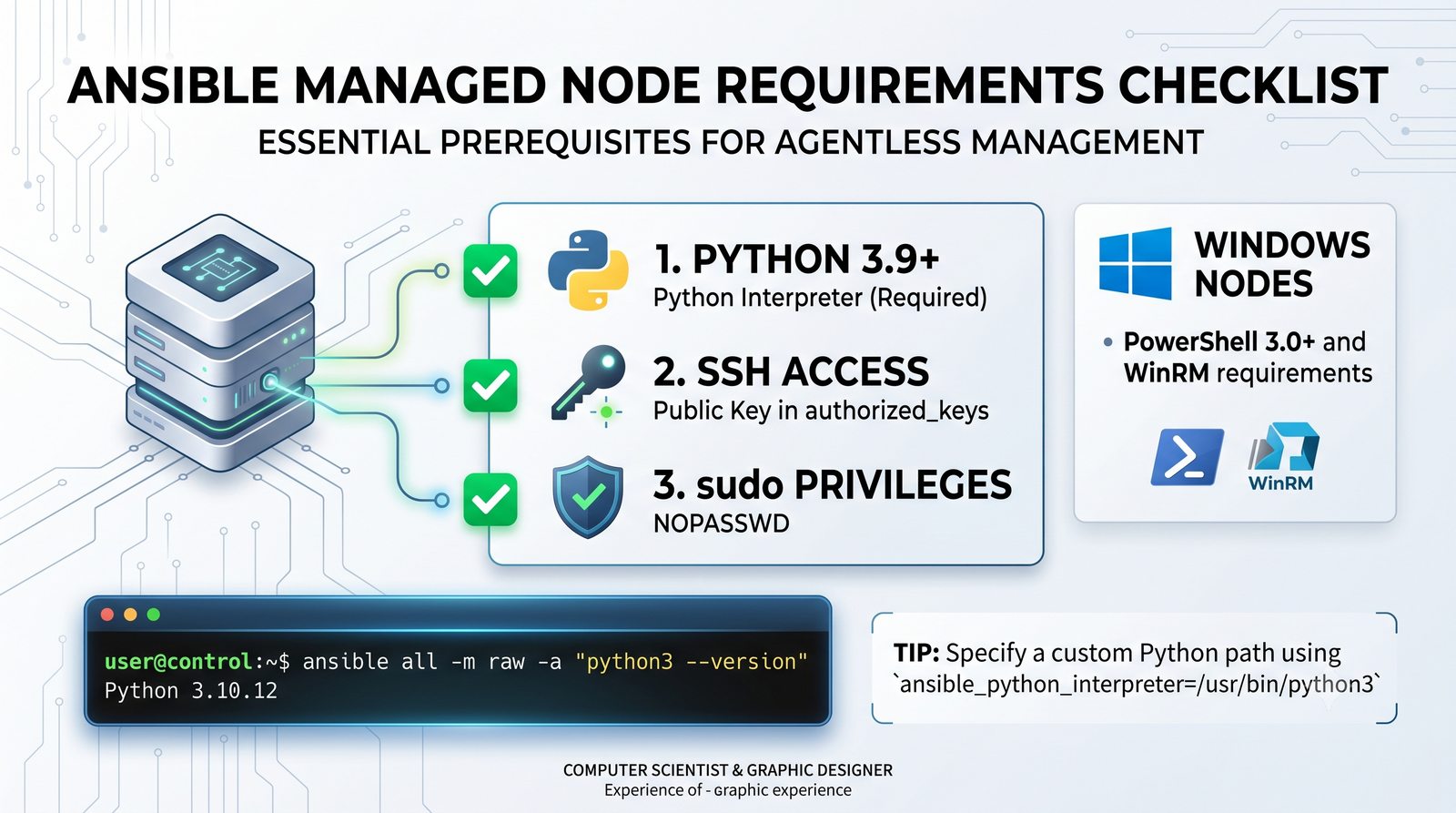
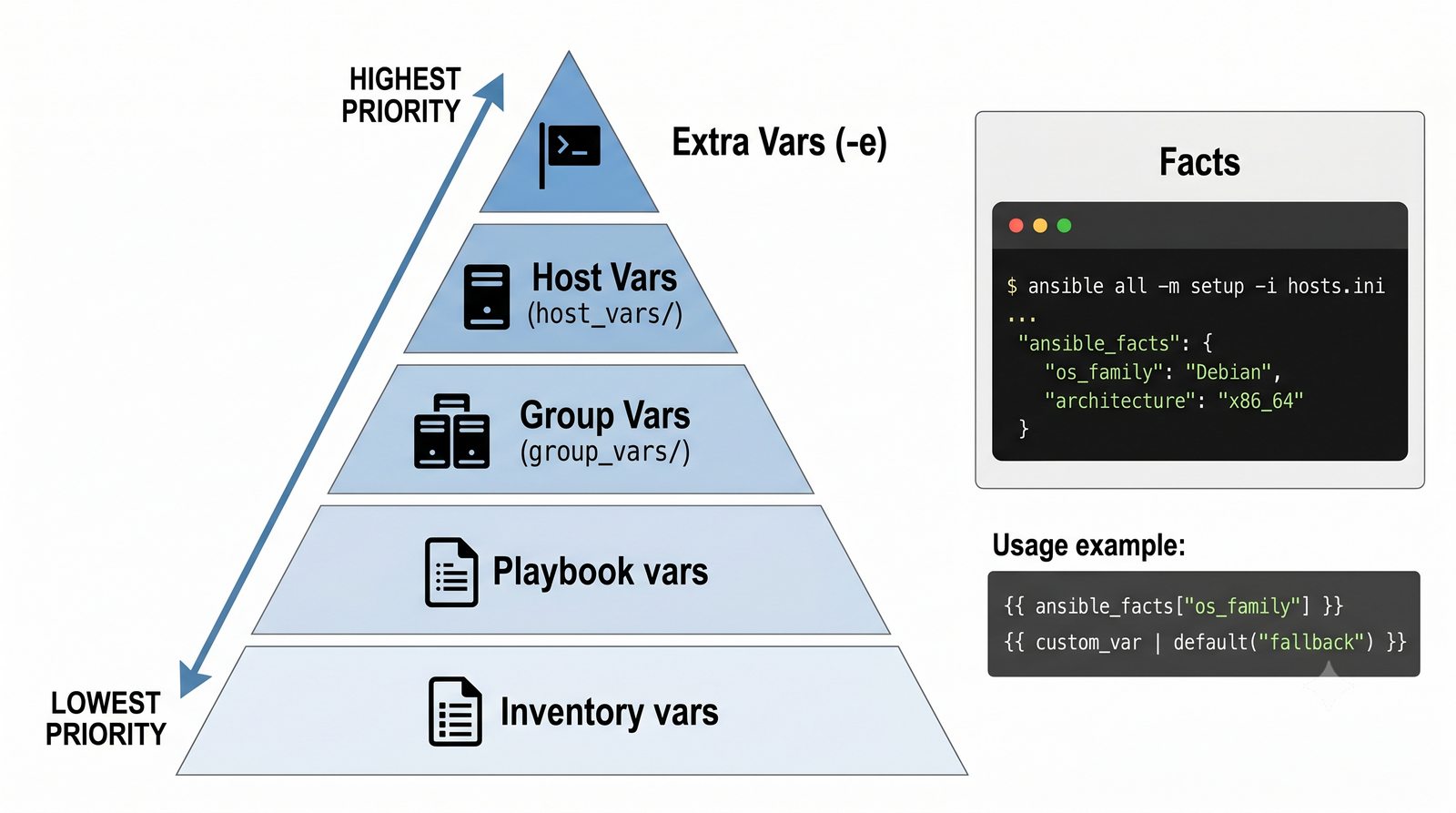
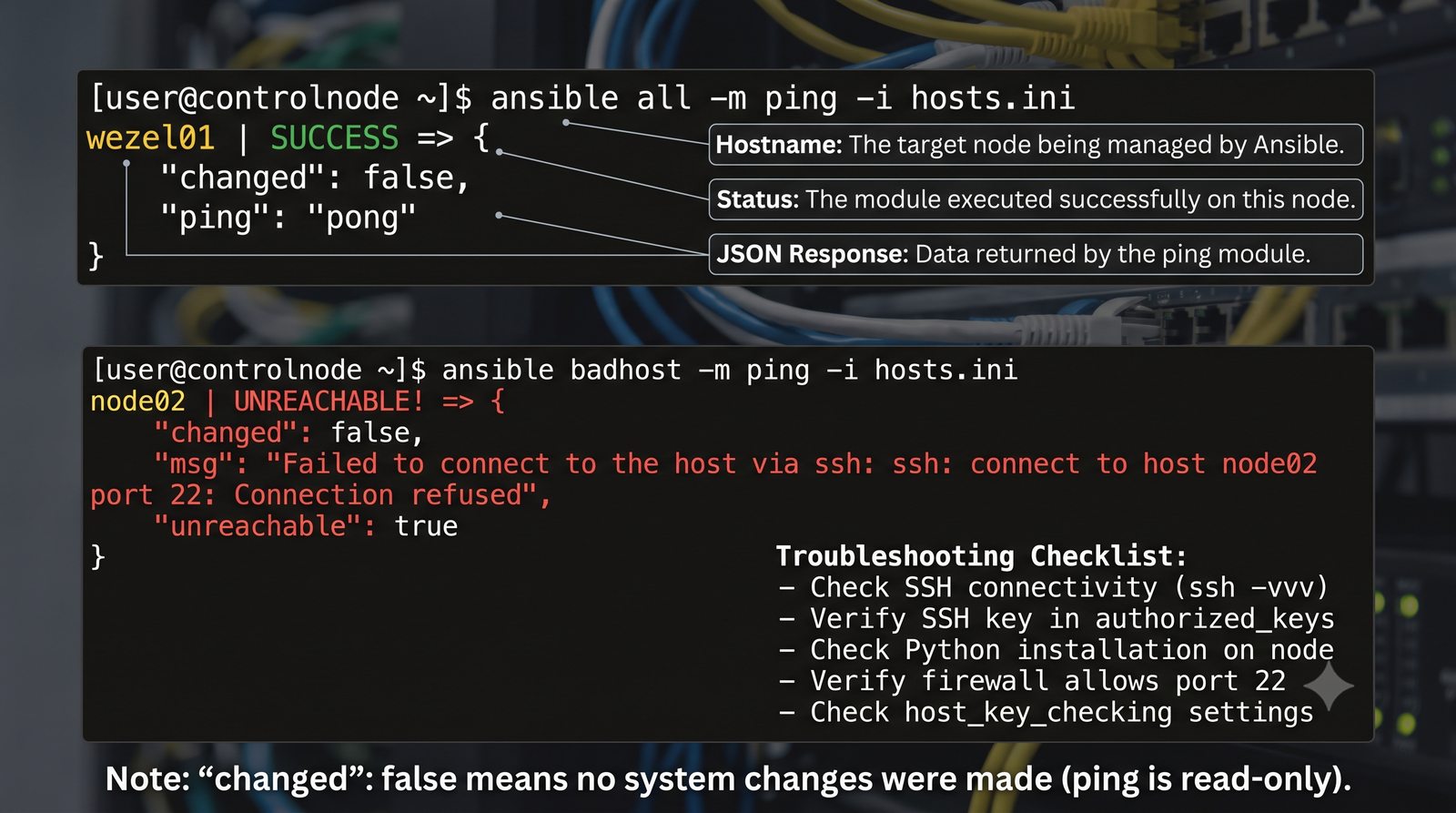
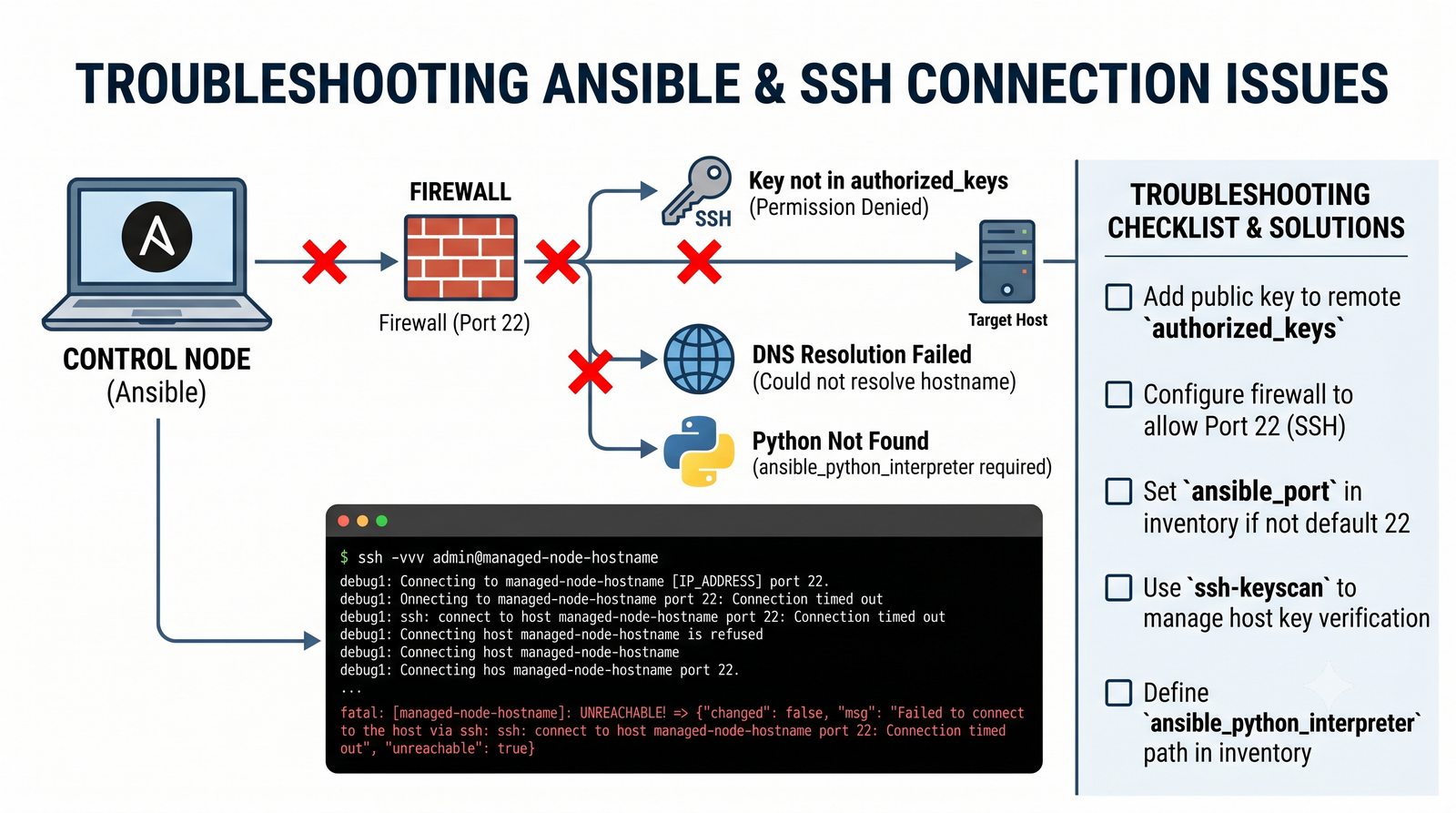
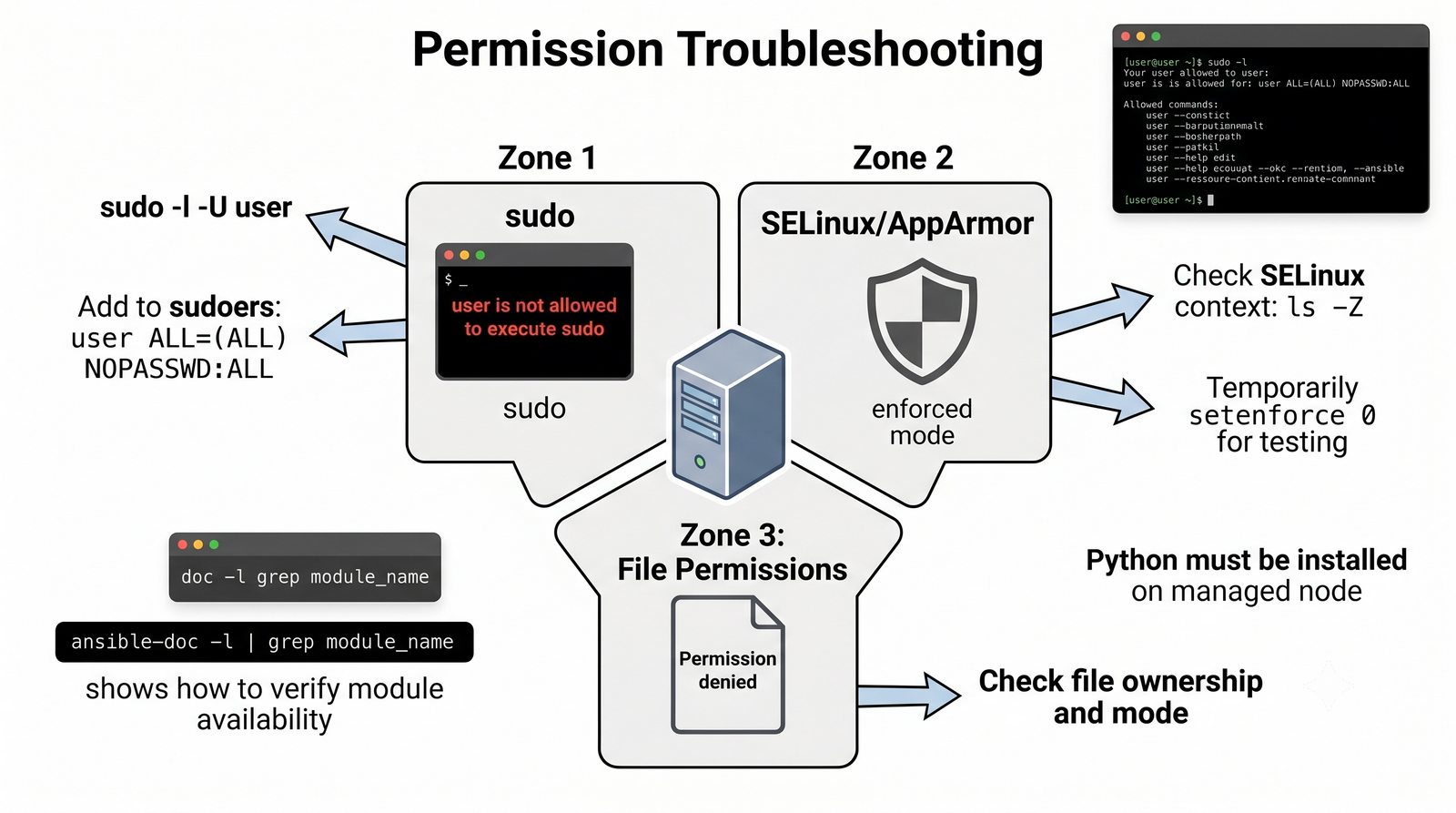
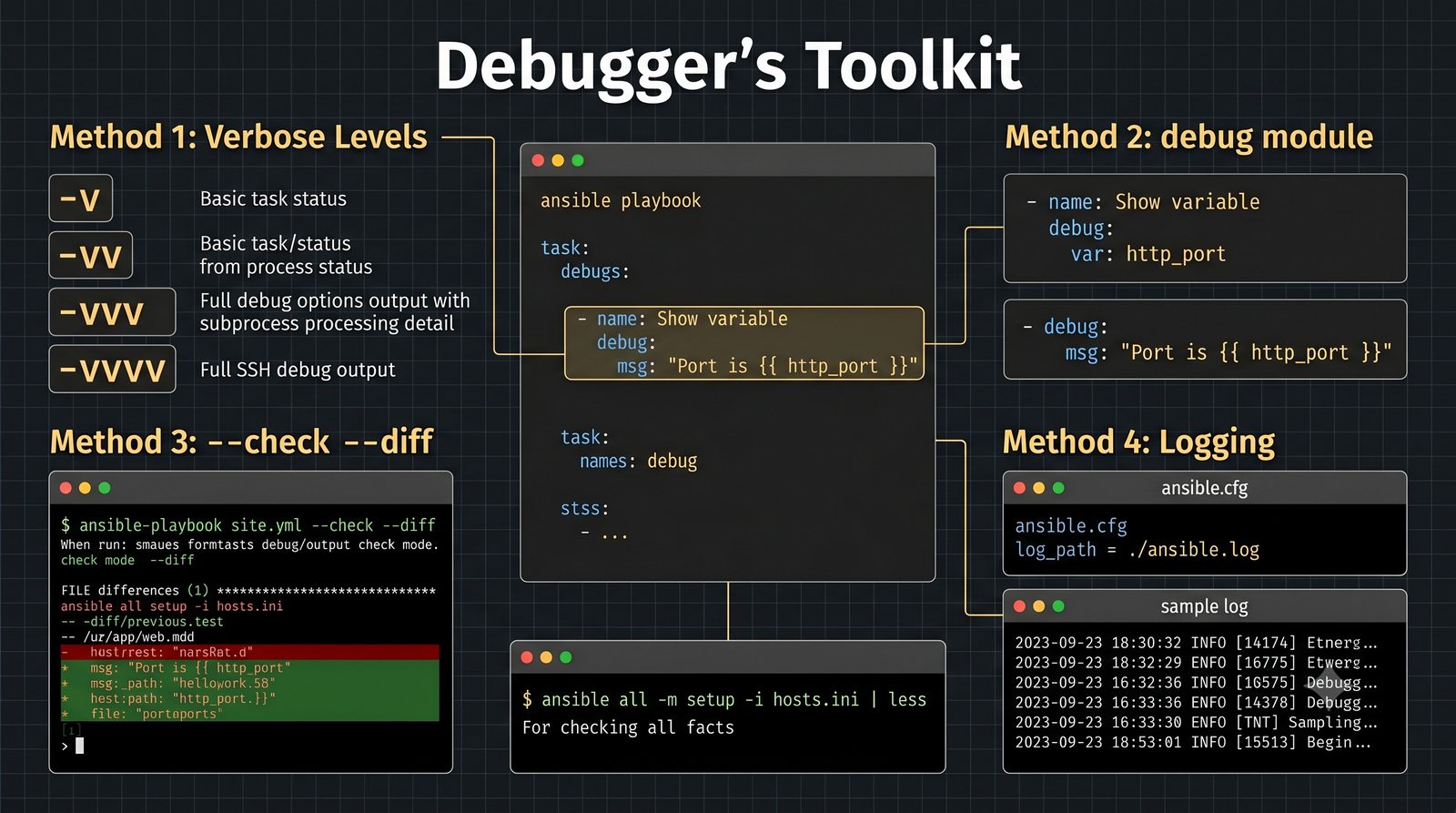
Ansible jest jednym z najpopularniejszych narzędzi do automatyzacji konfiguracji, zarządzanym przez Red Hat. Jego główną zaletą jest bezagentowa architektura - do zarządzania węzłami wystarczy dostęp SSH i interpreter Pythona na zdalnej maszynie.
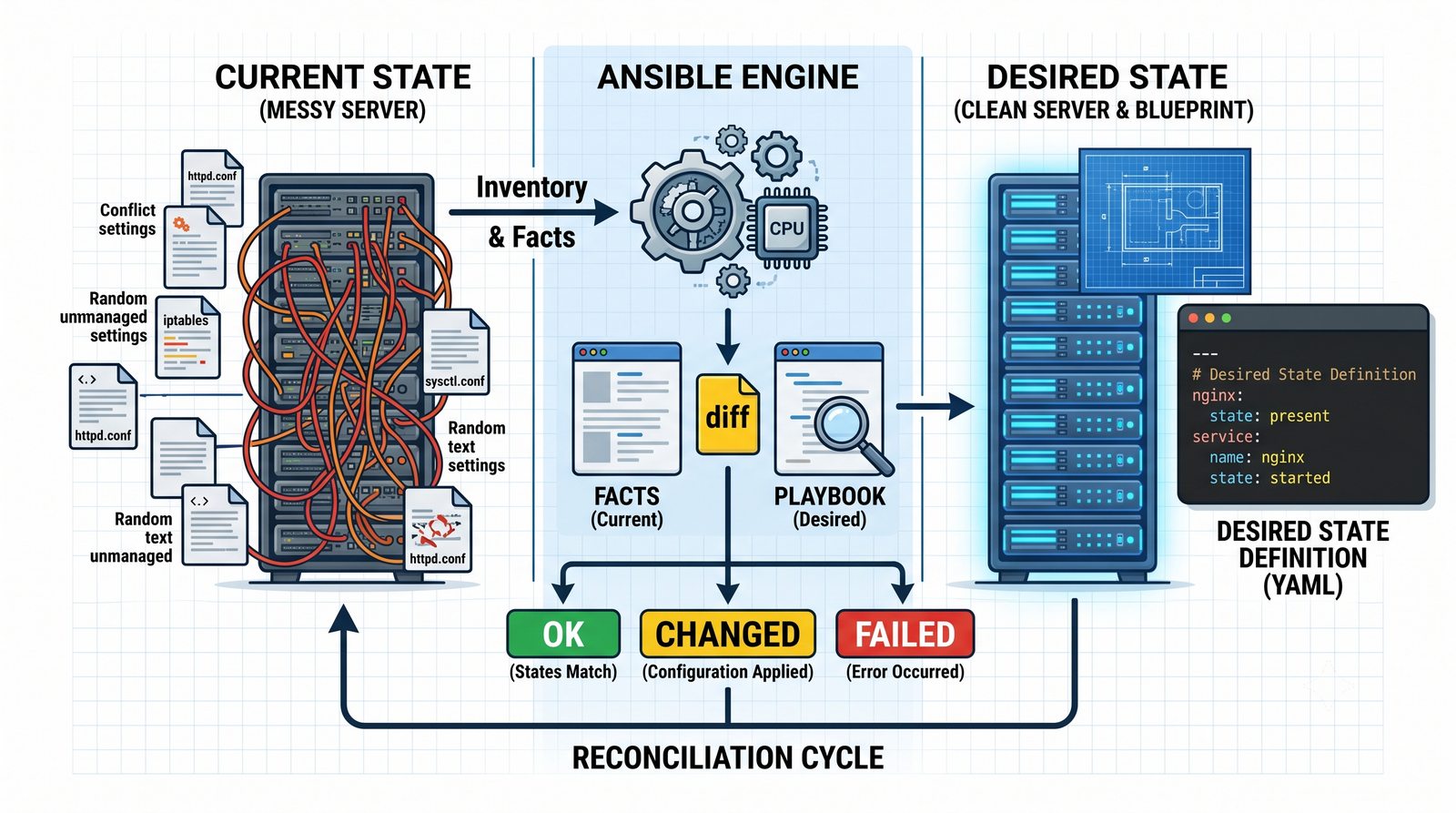
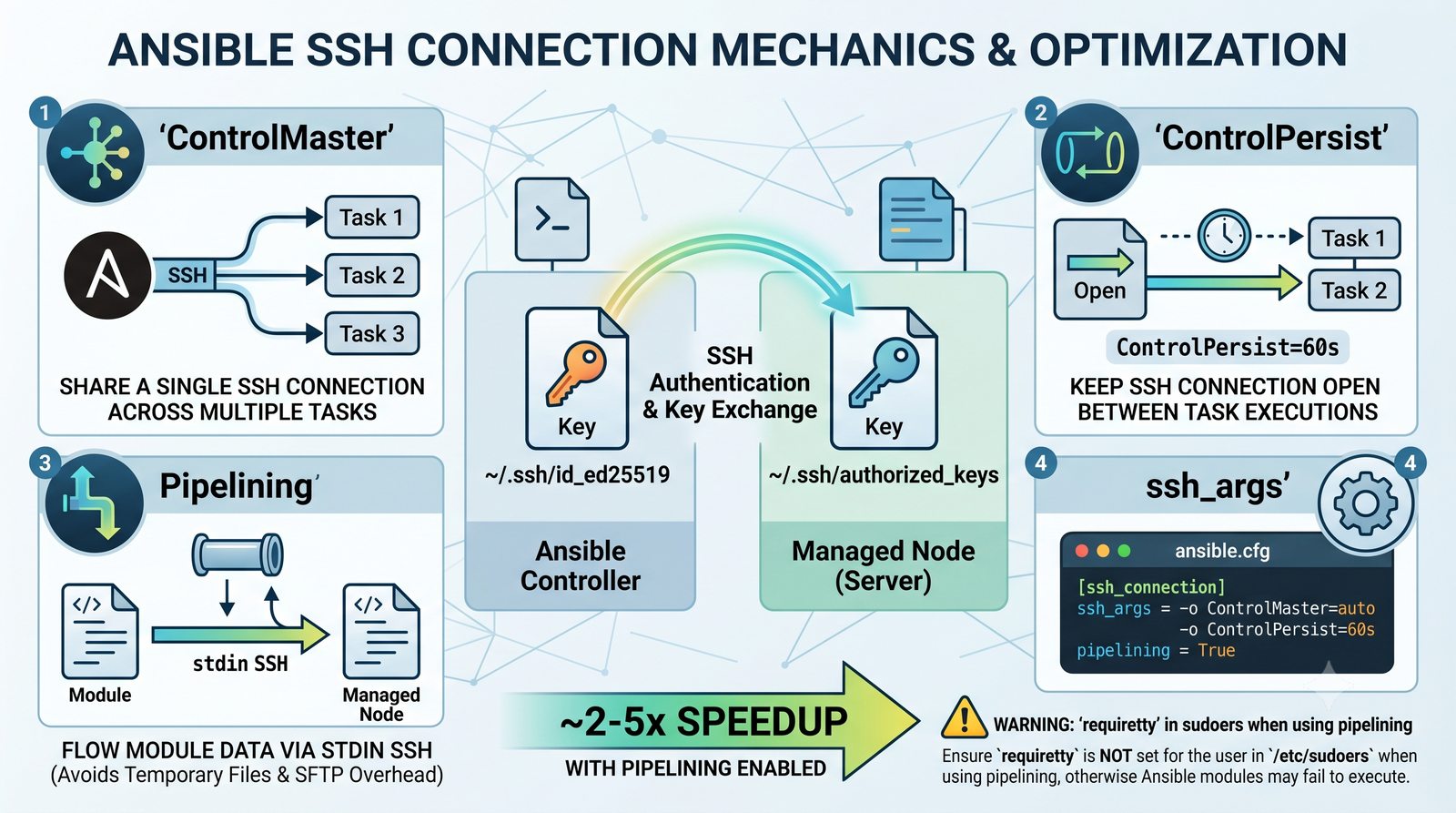
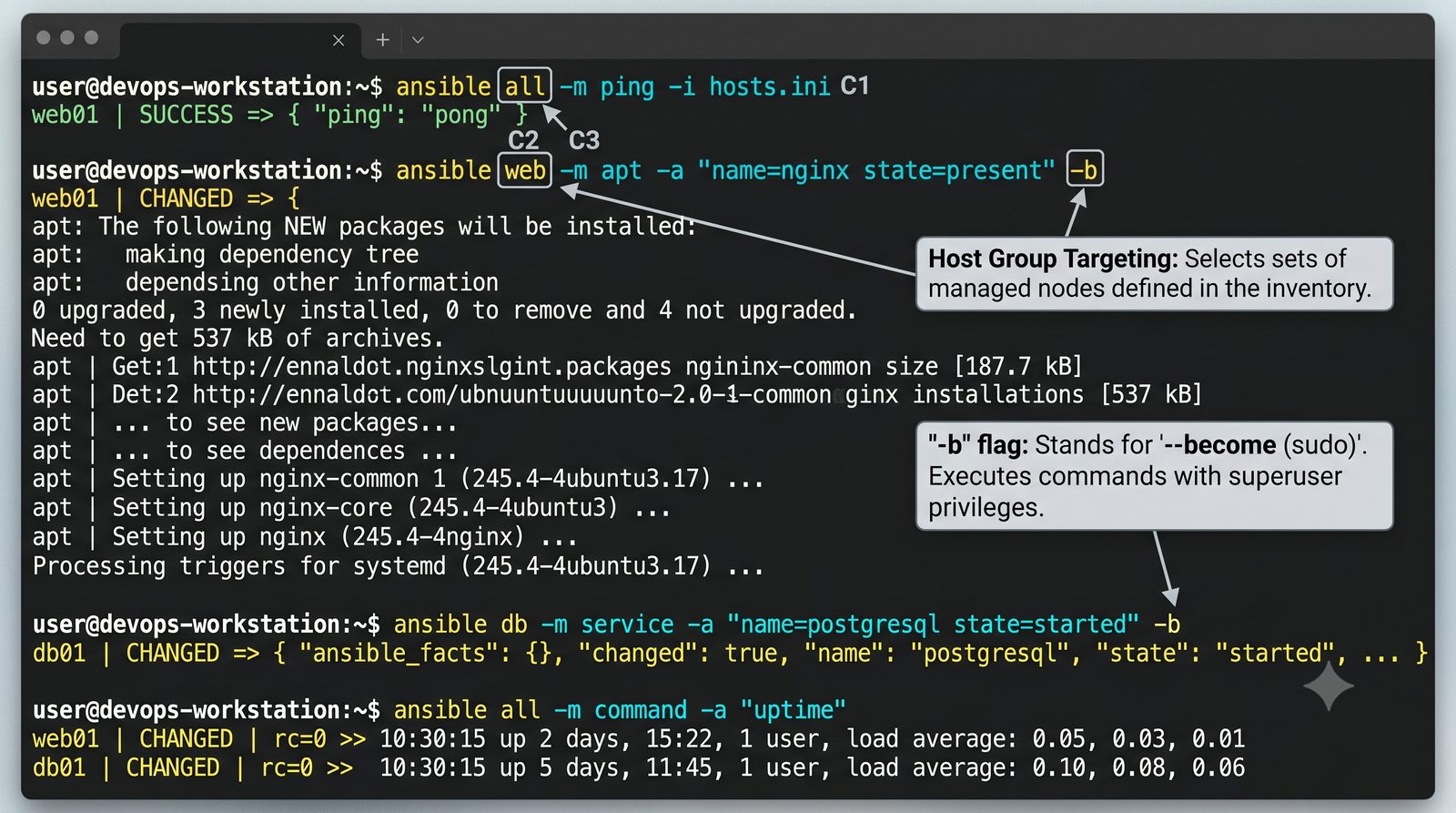
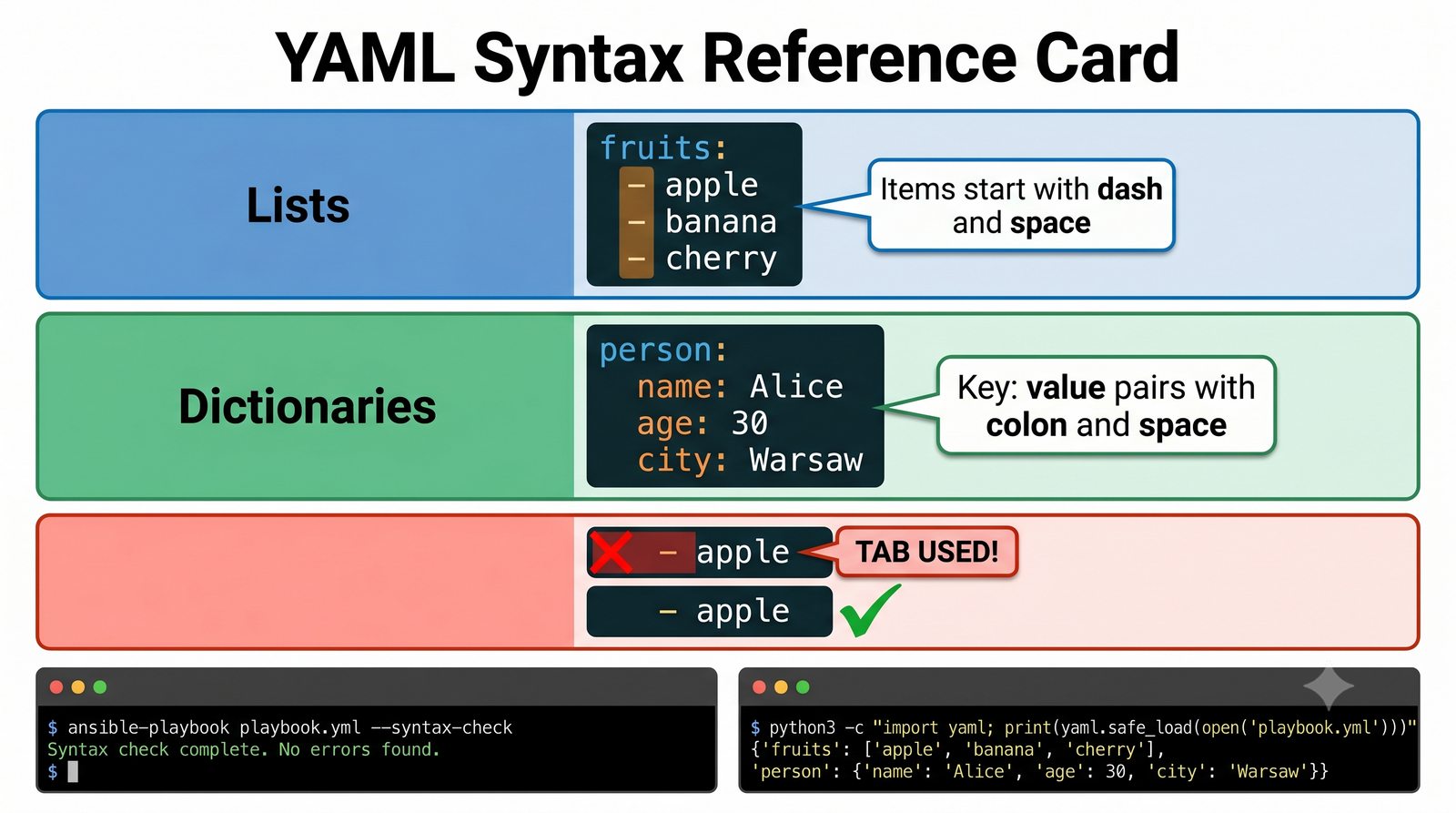
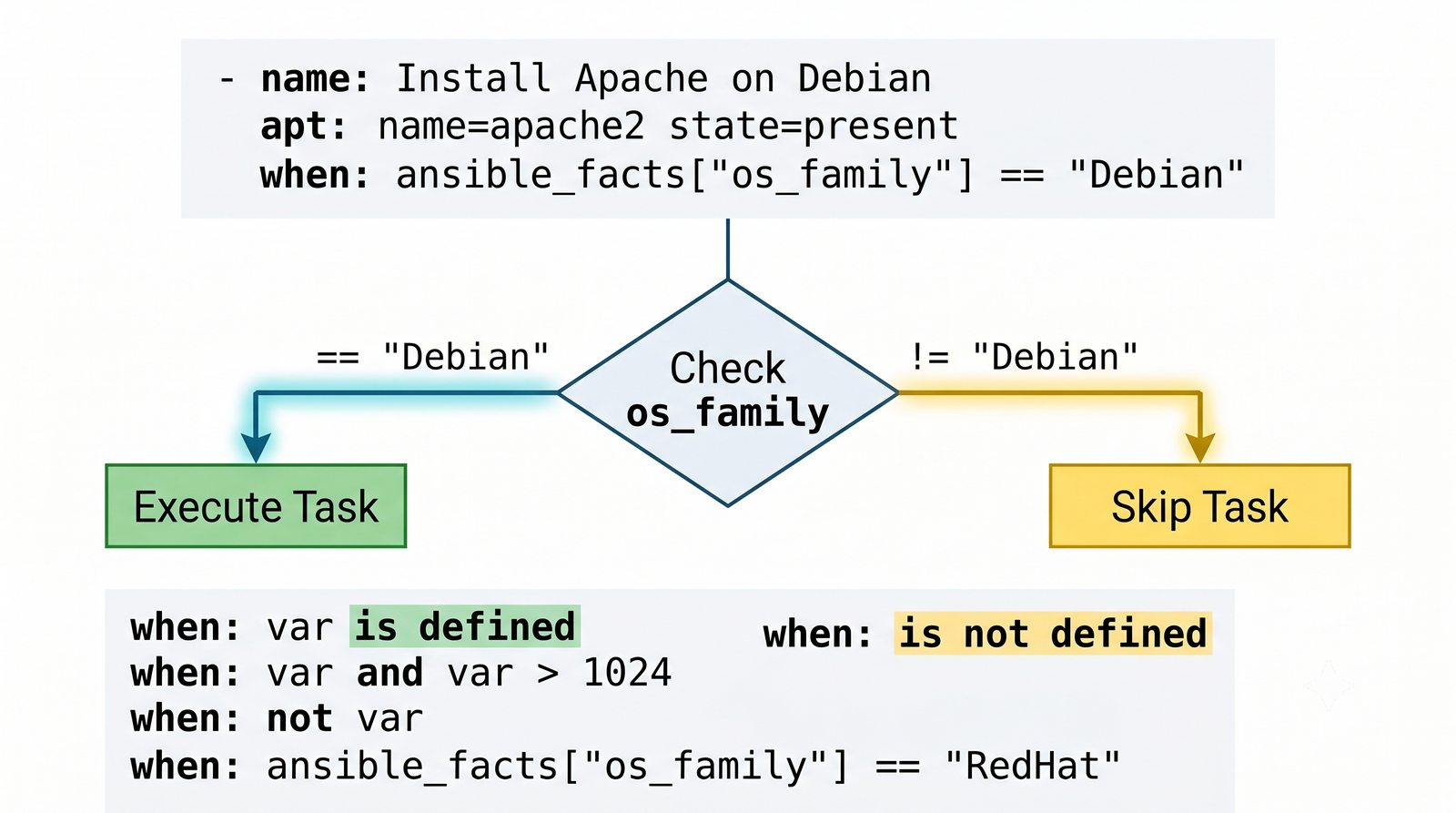
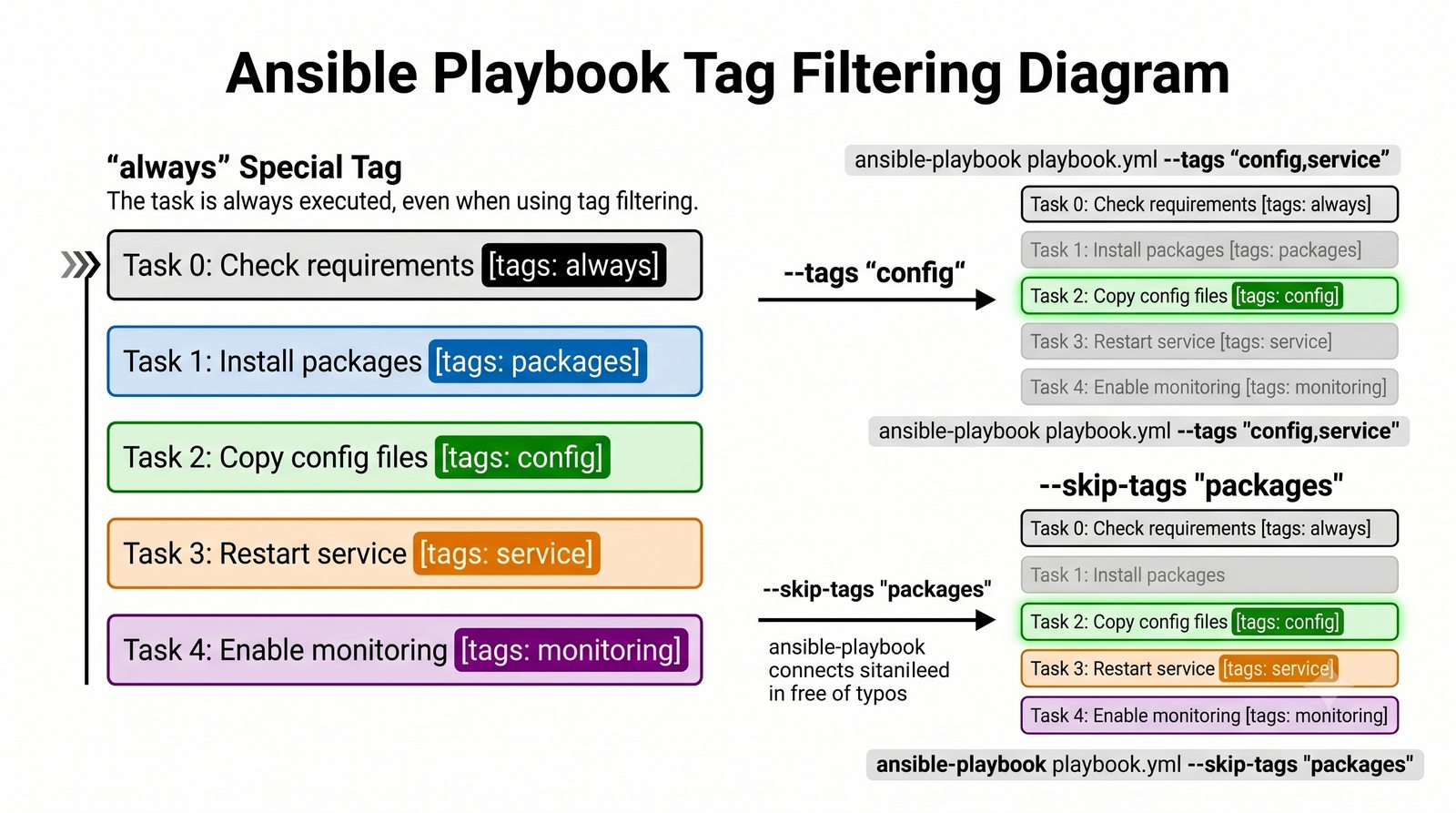
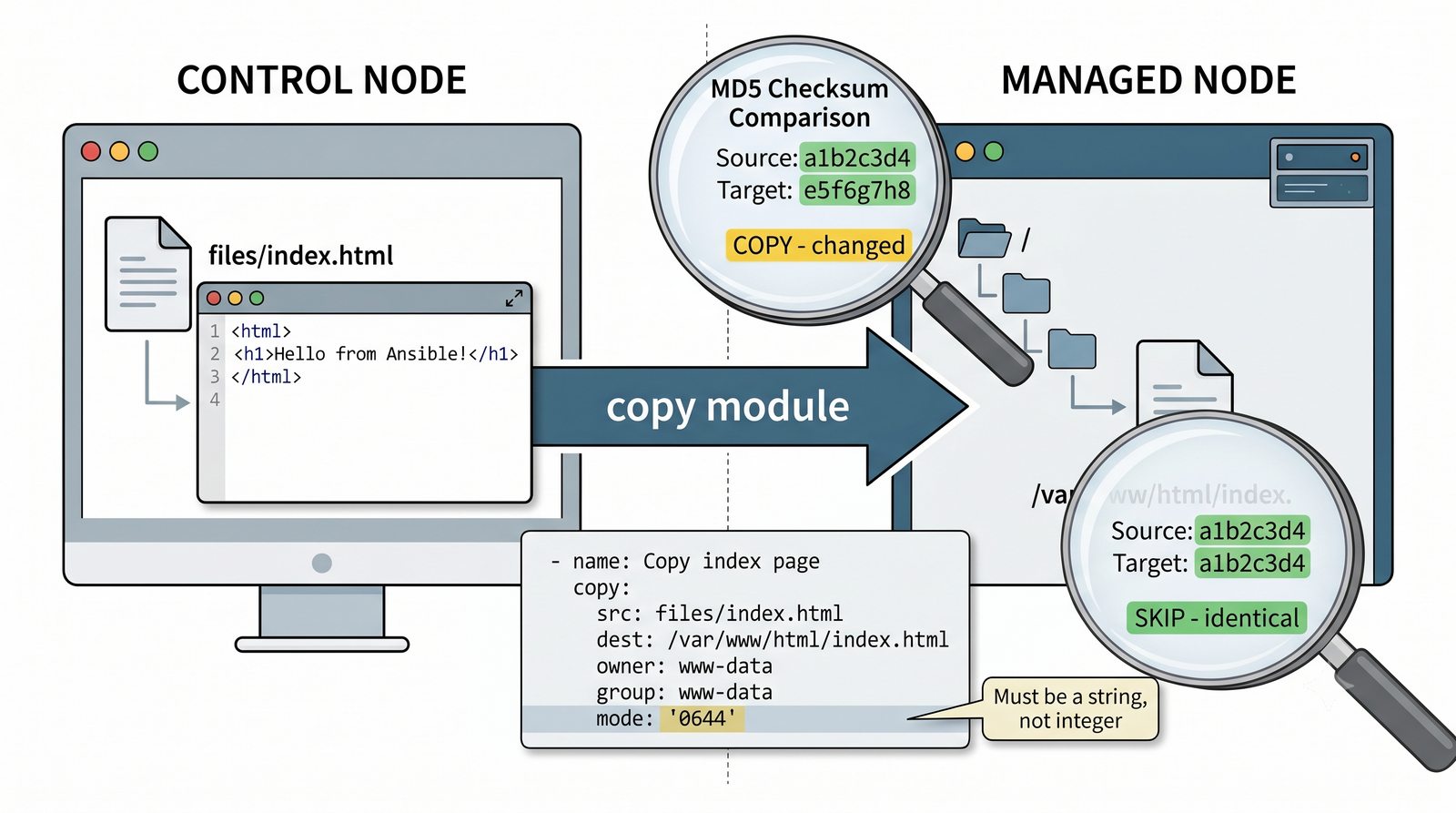
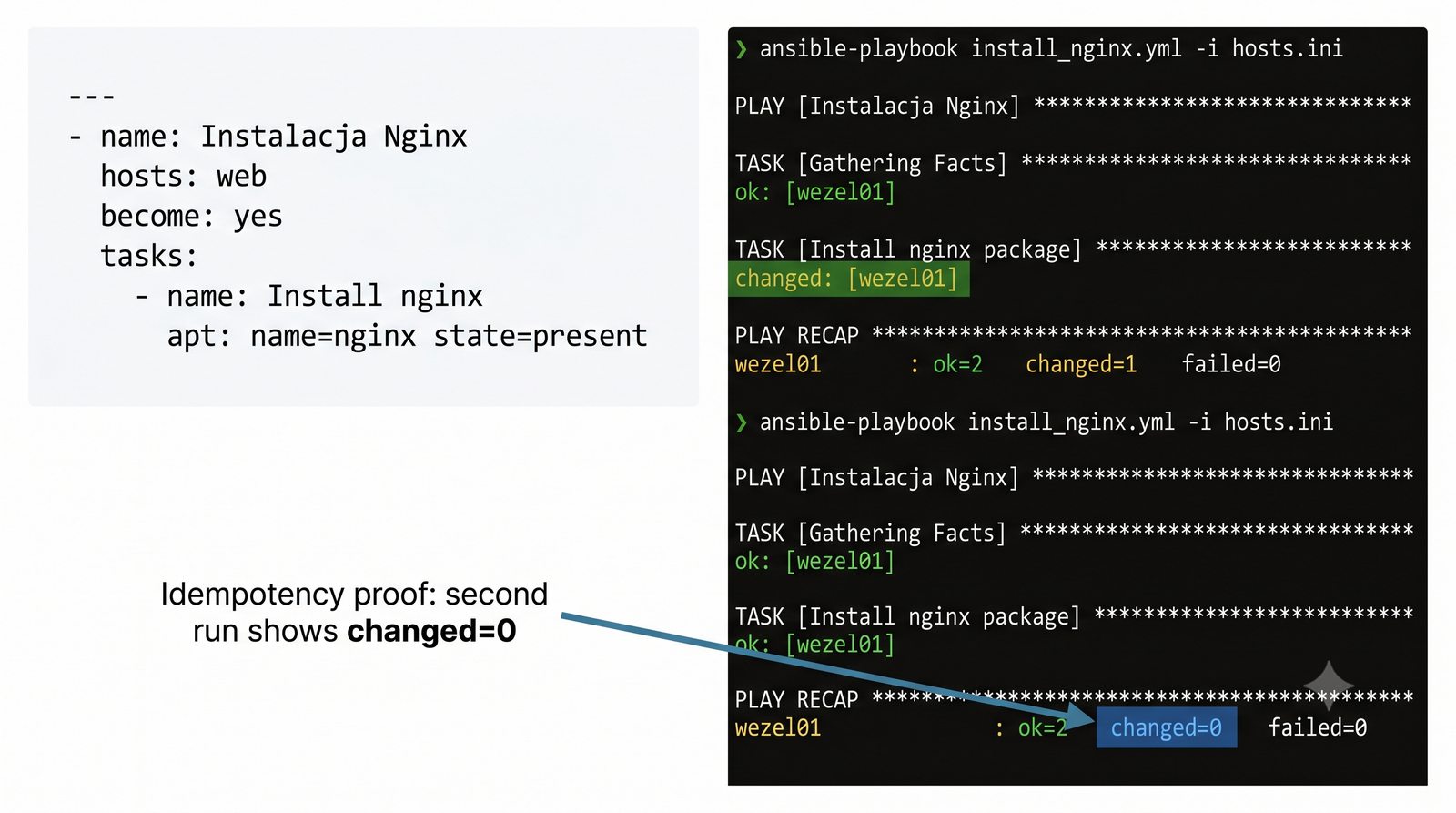
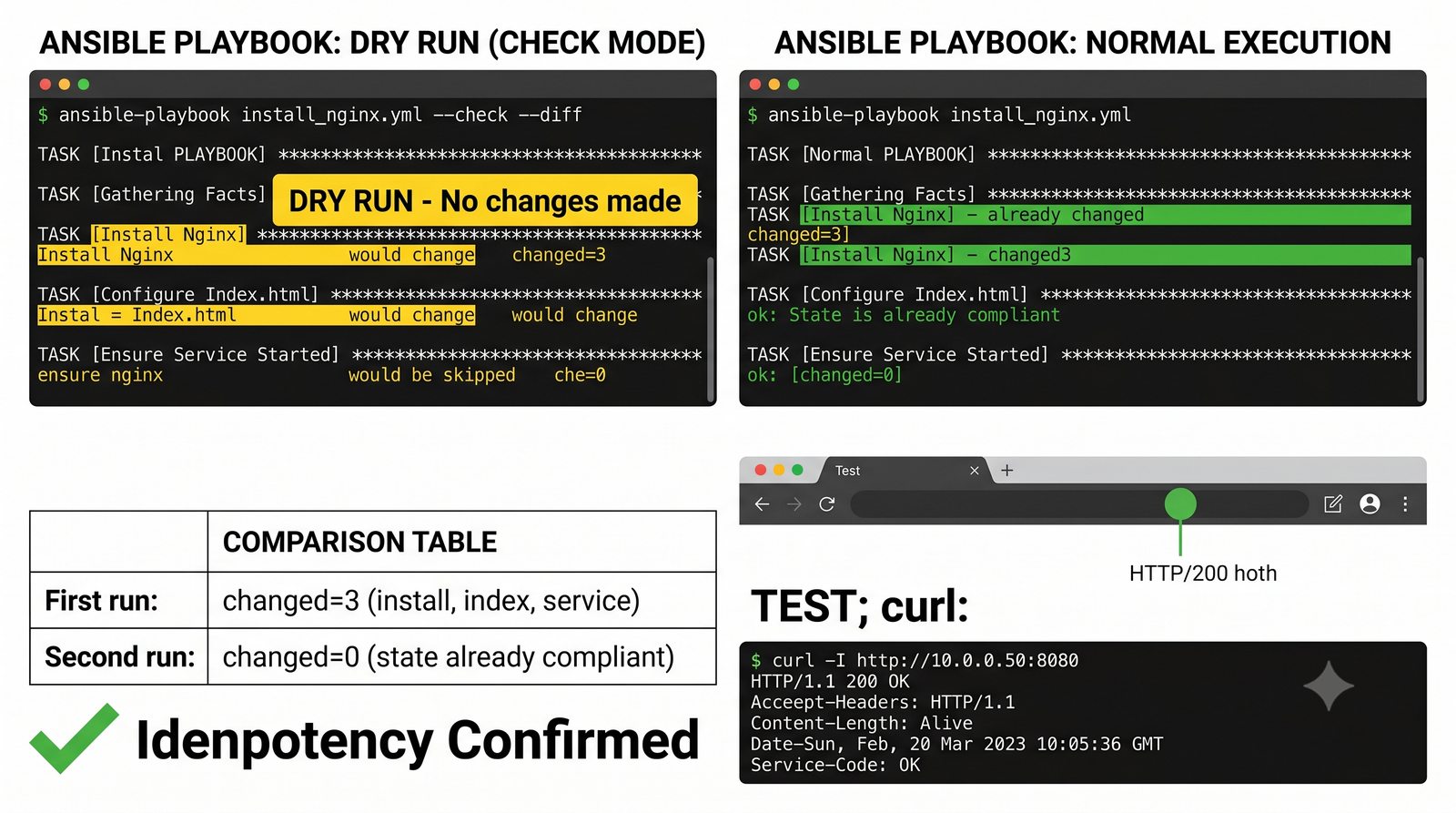
W przeciwieństwie do skryptów bash, Ansible zapewnia idempotentność: wielokrotne uruchomienie playbooka daje ten sam efekt, a przy stanie zgodnym nie wprowadza żadnych zmian.
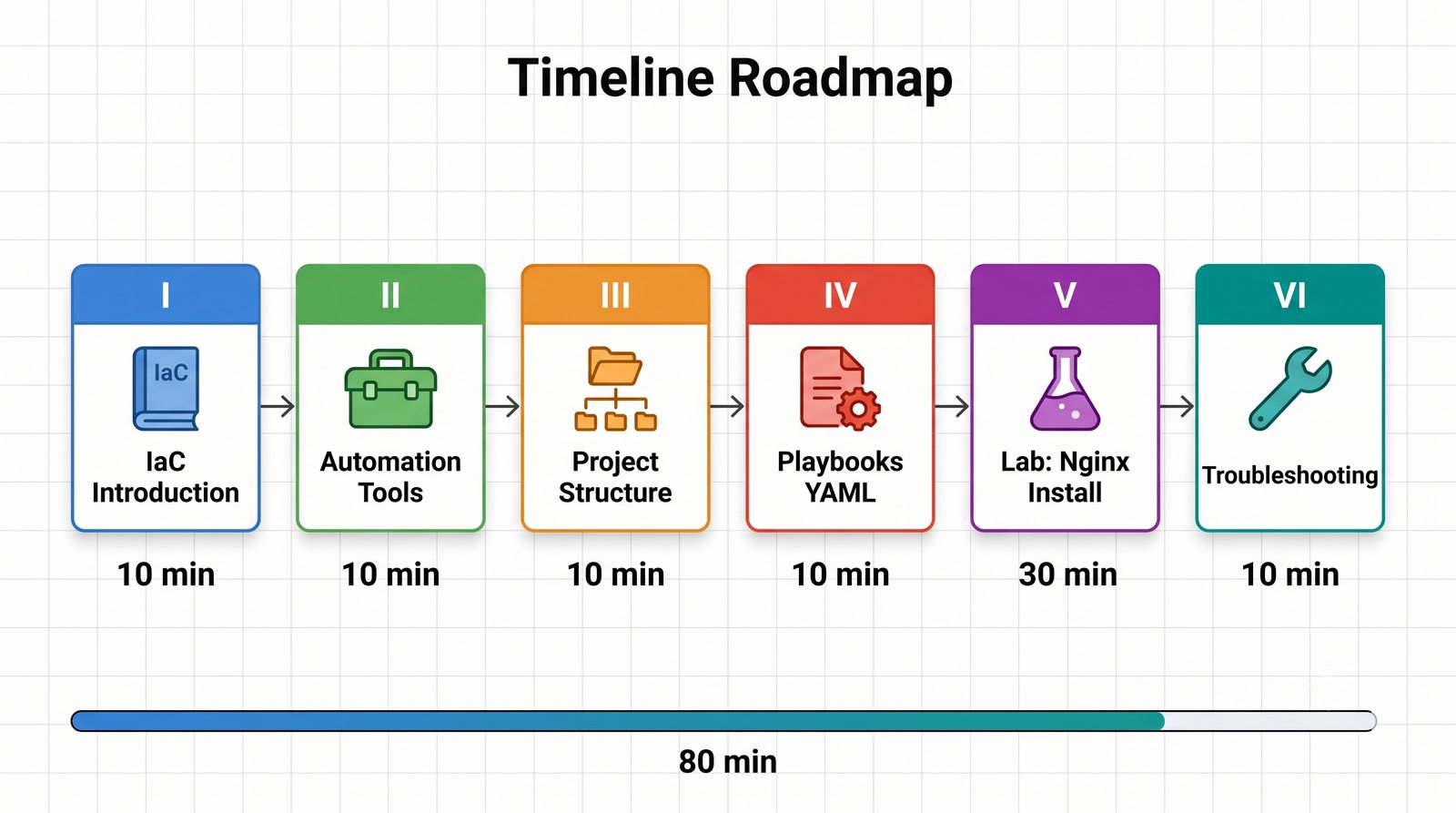
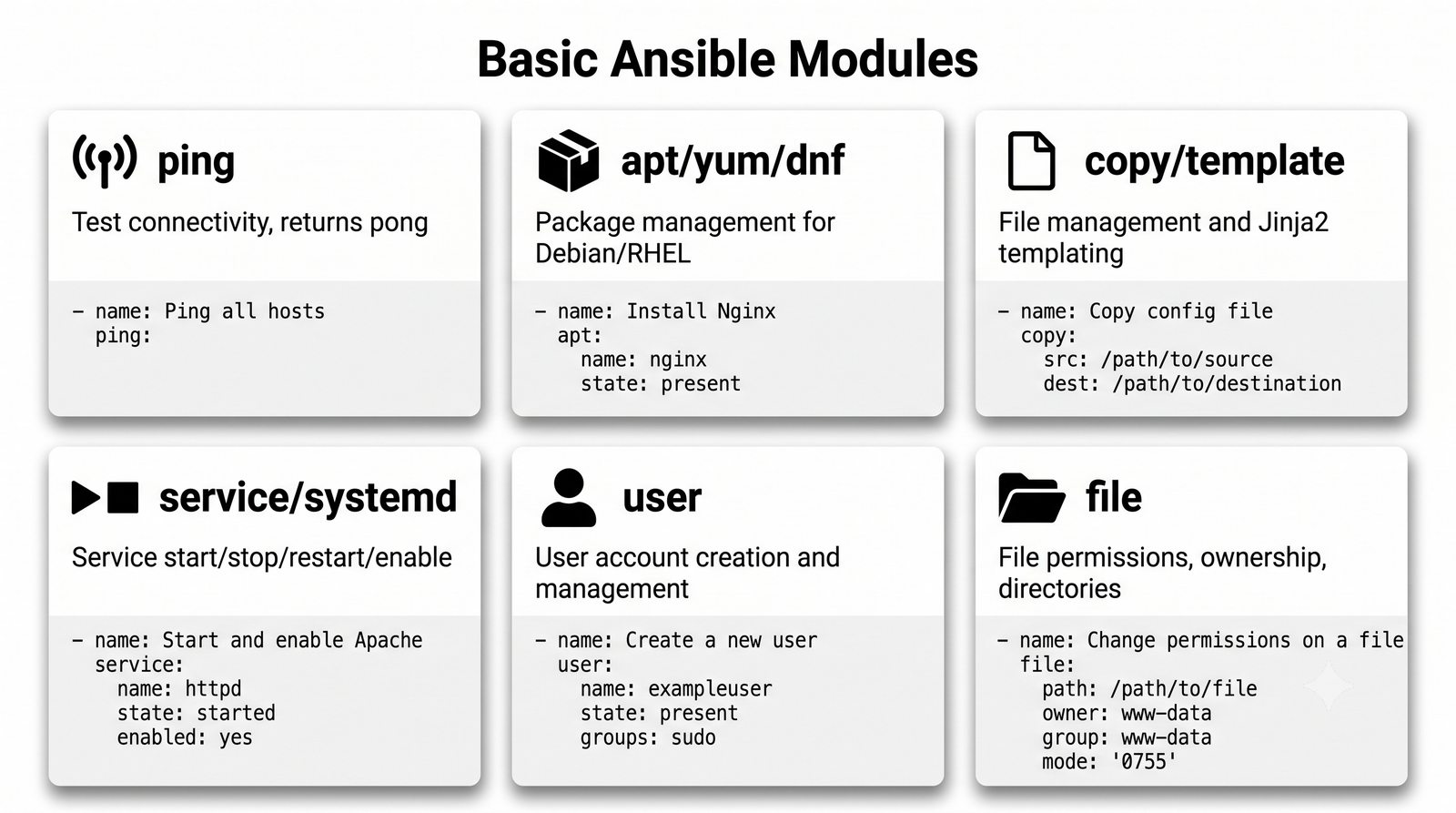
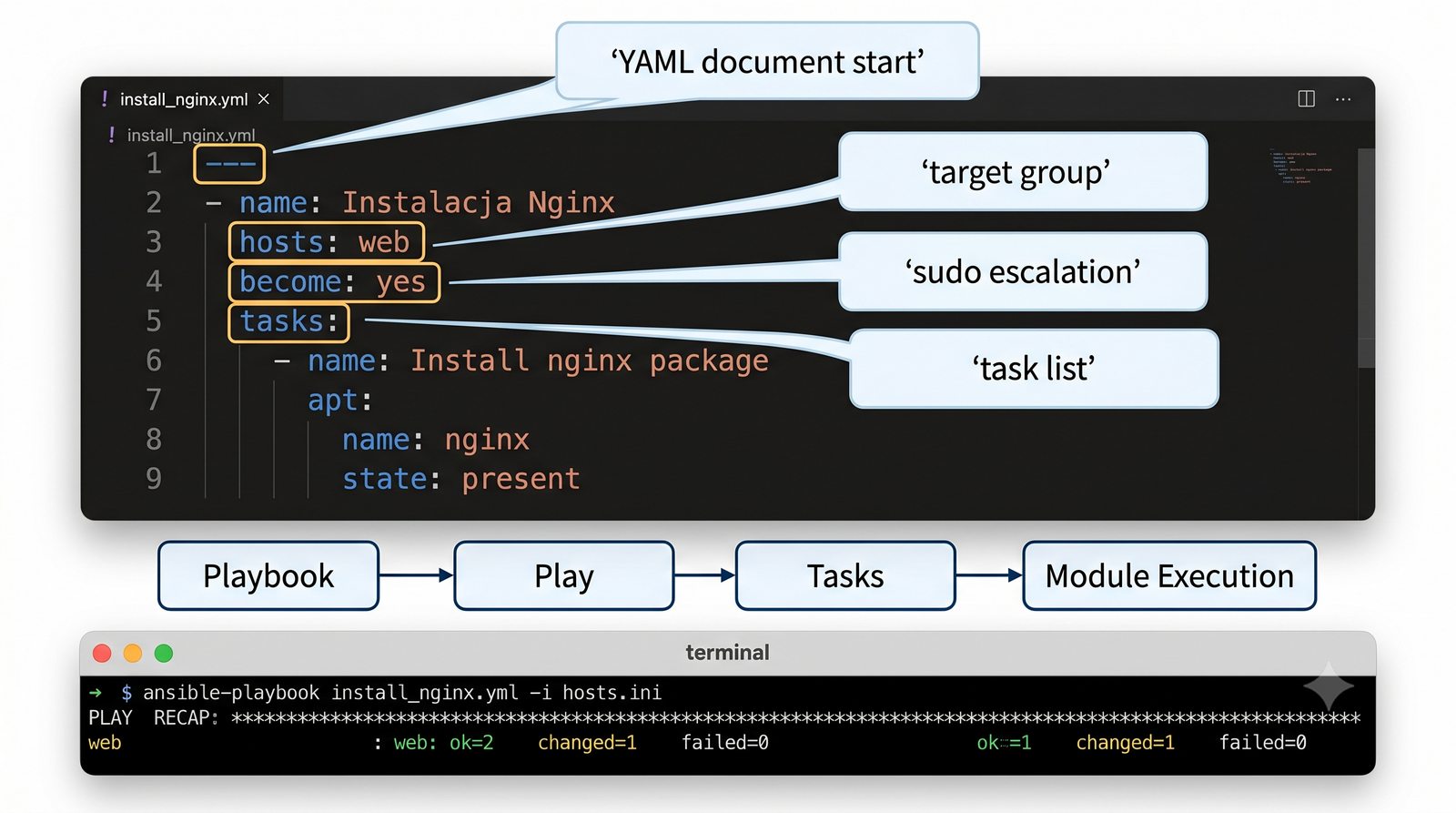
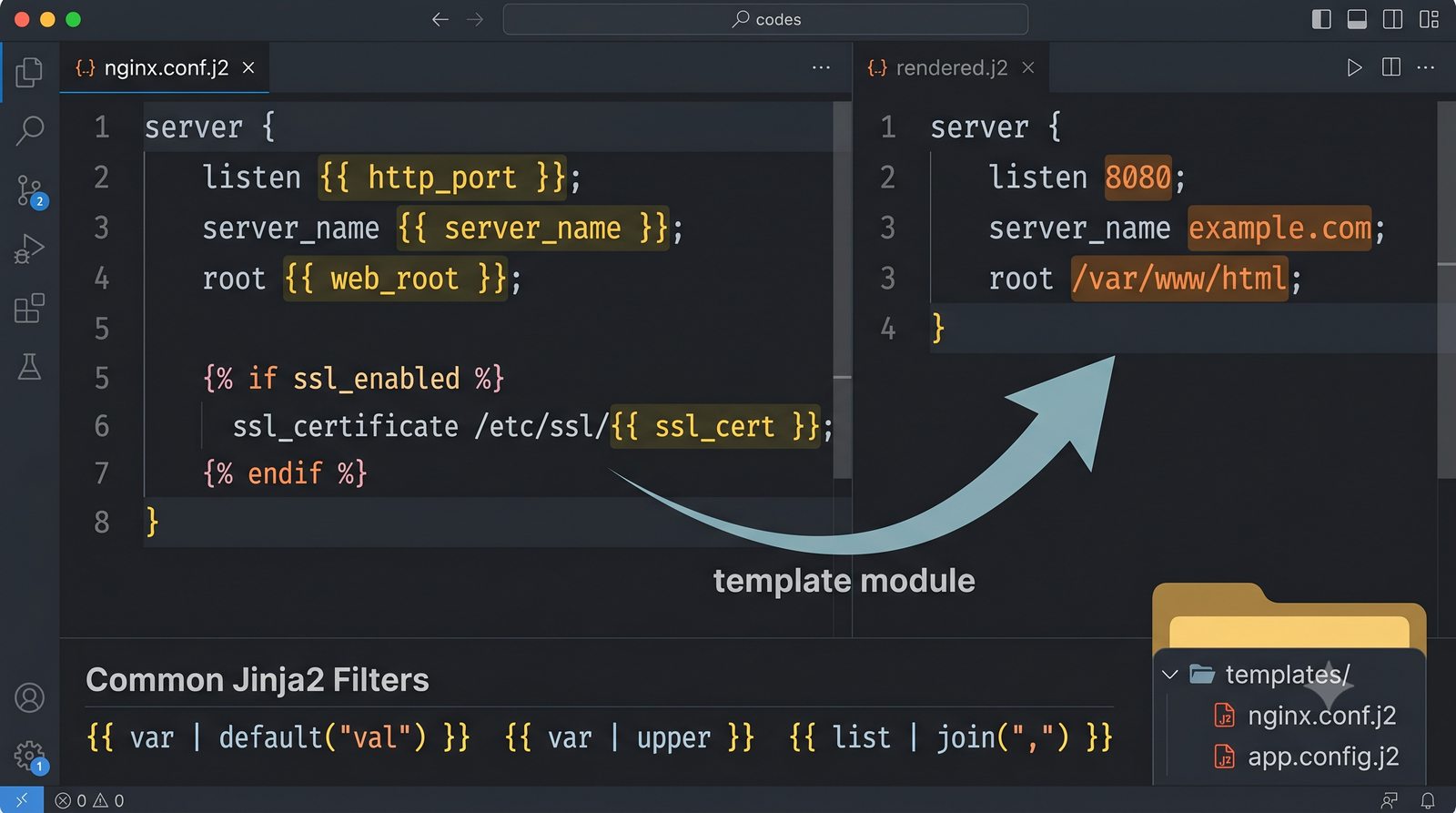
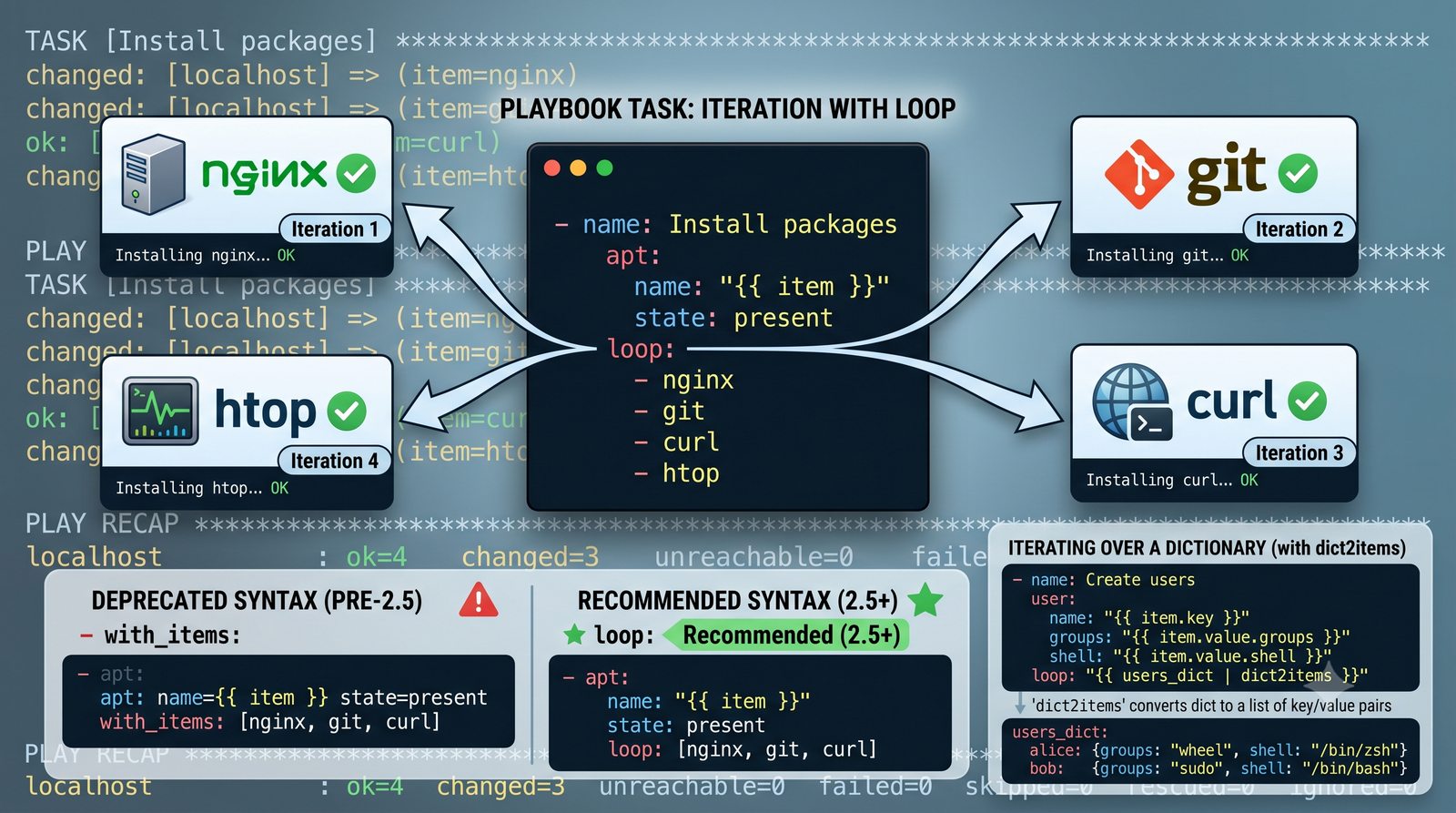
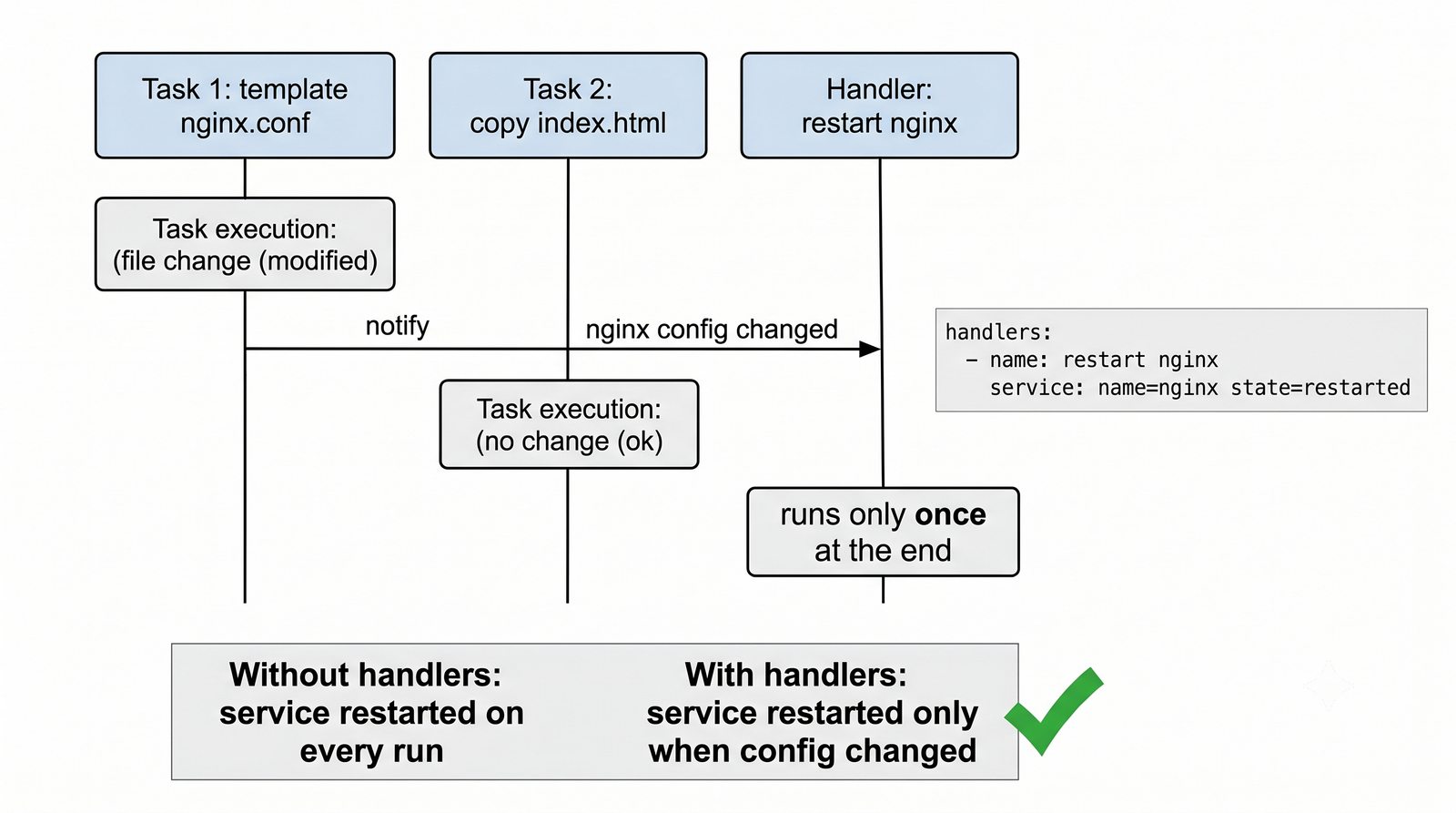
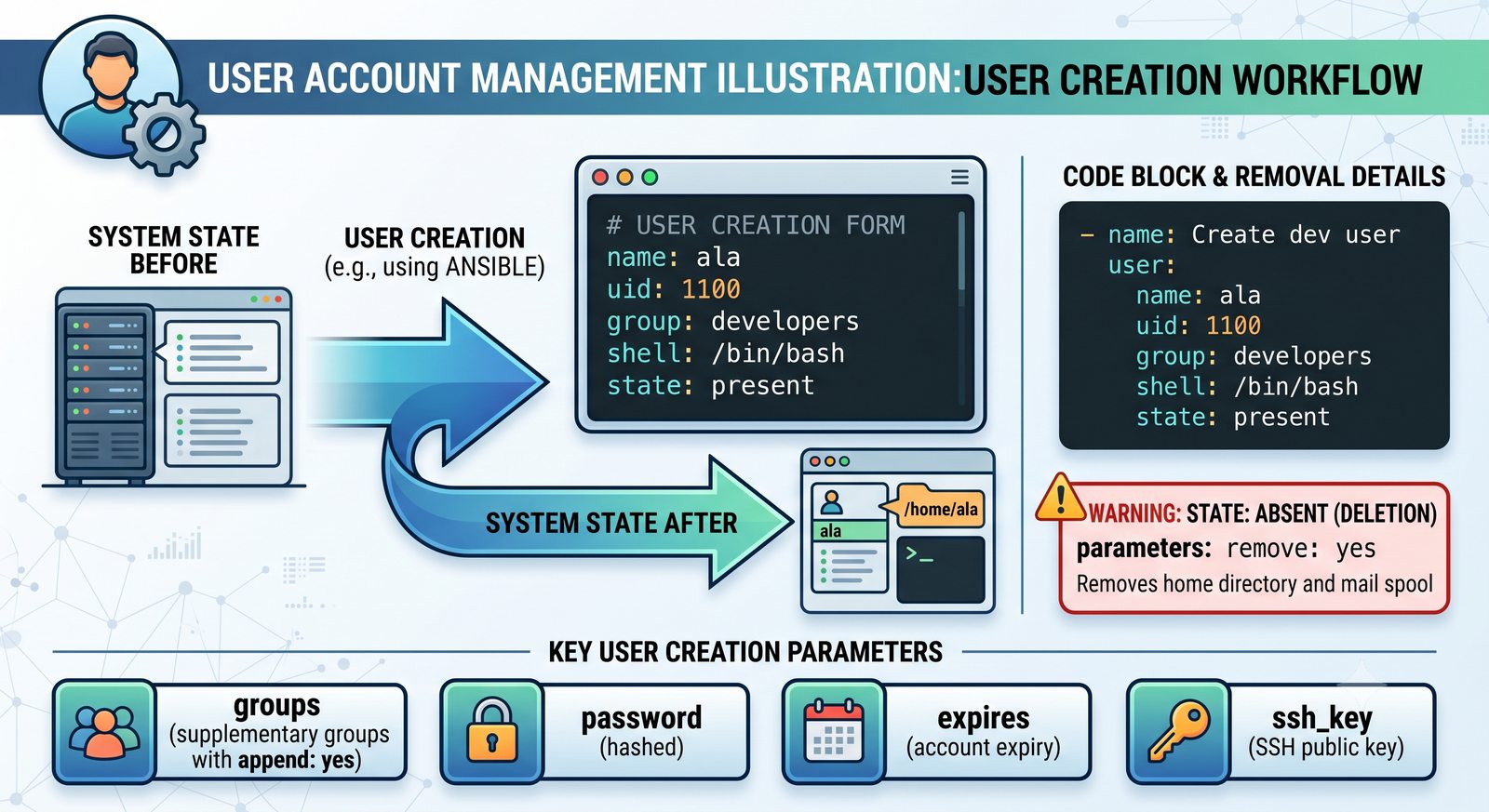
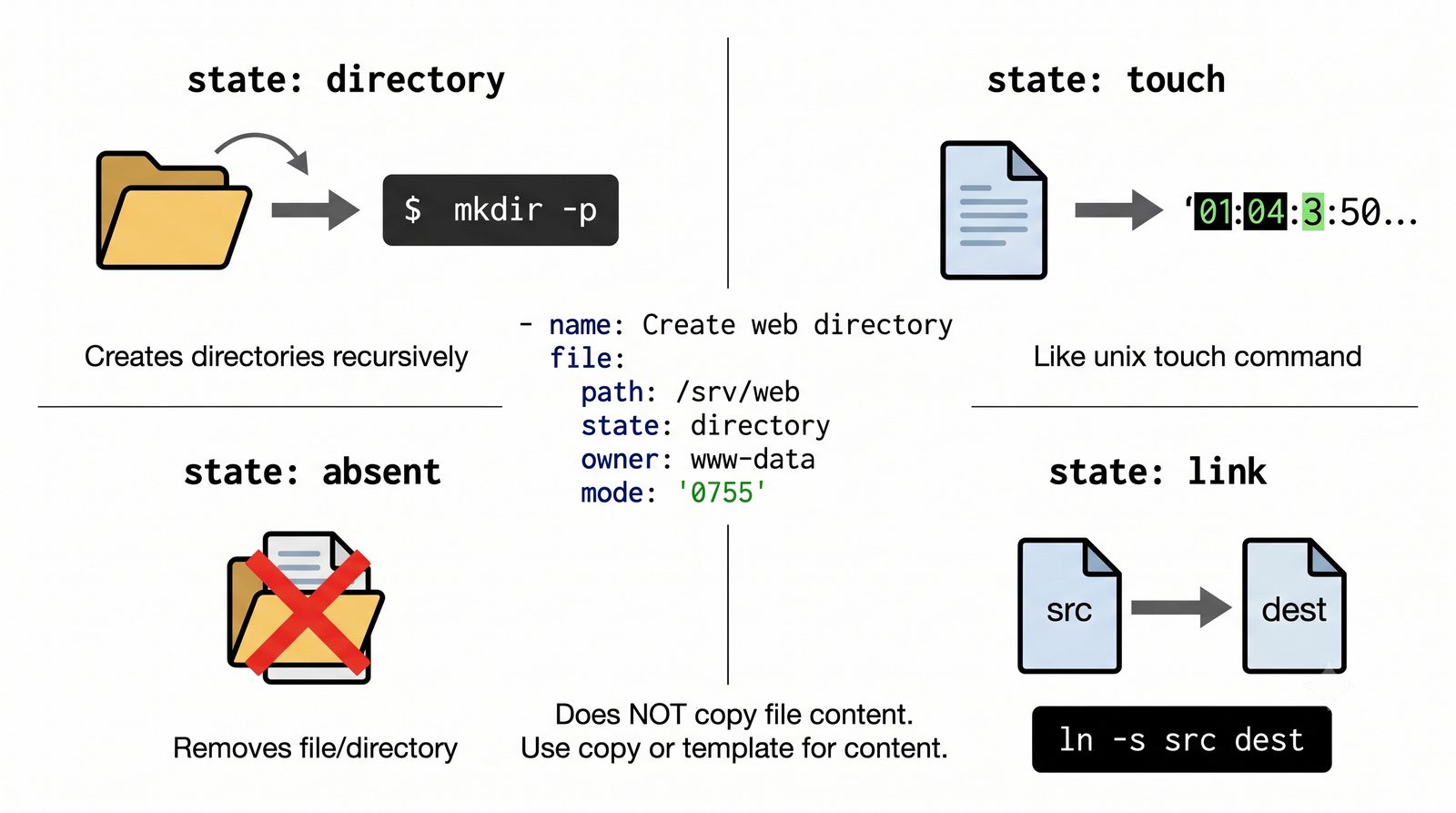
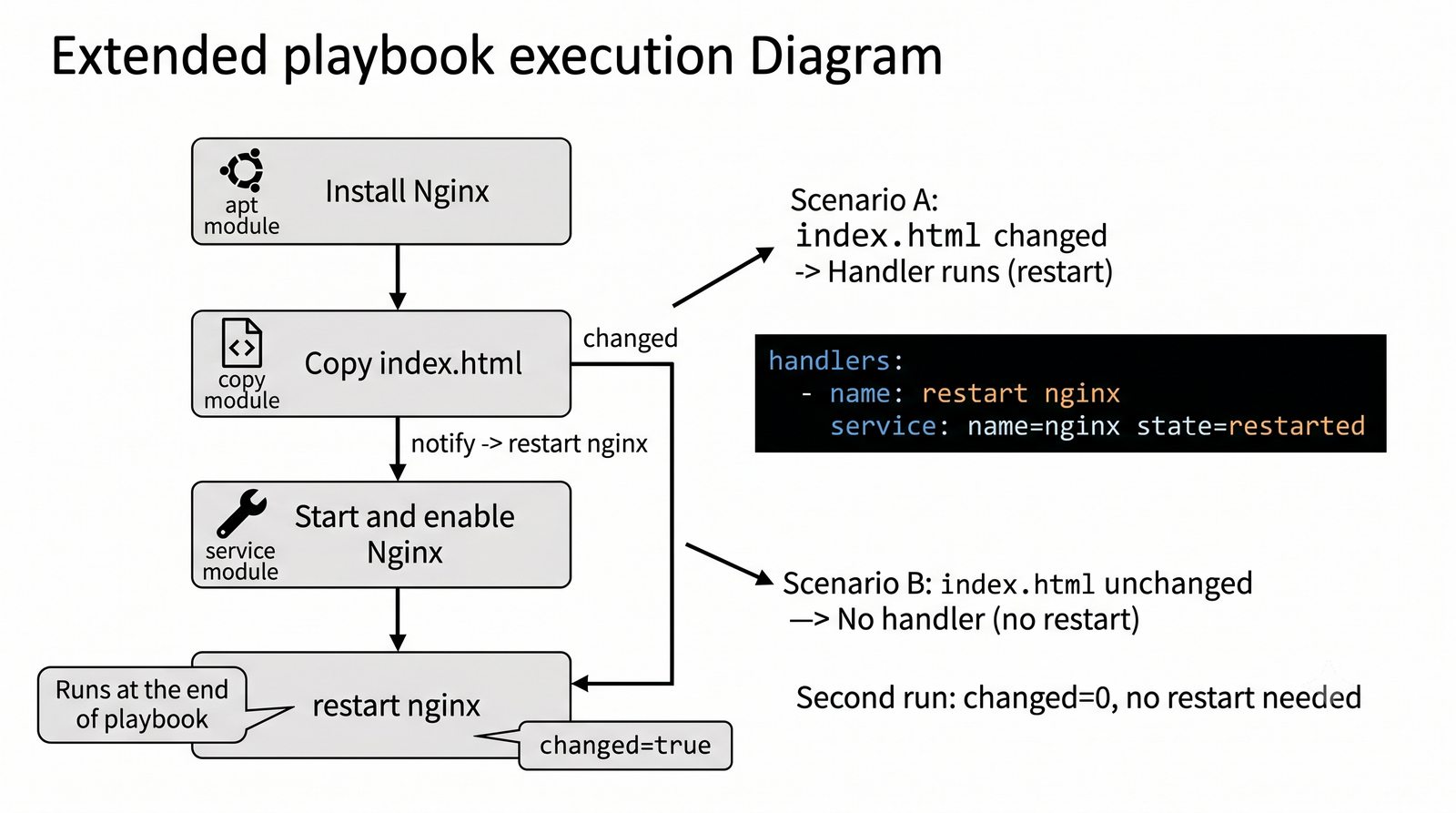
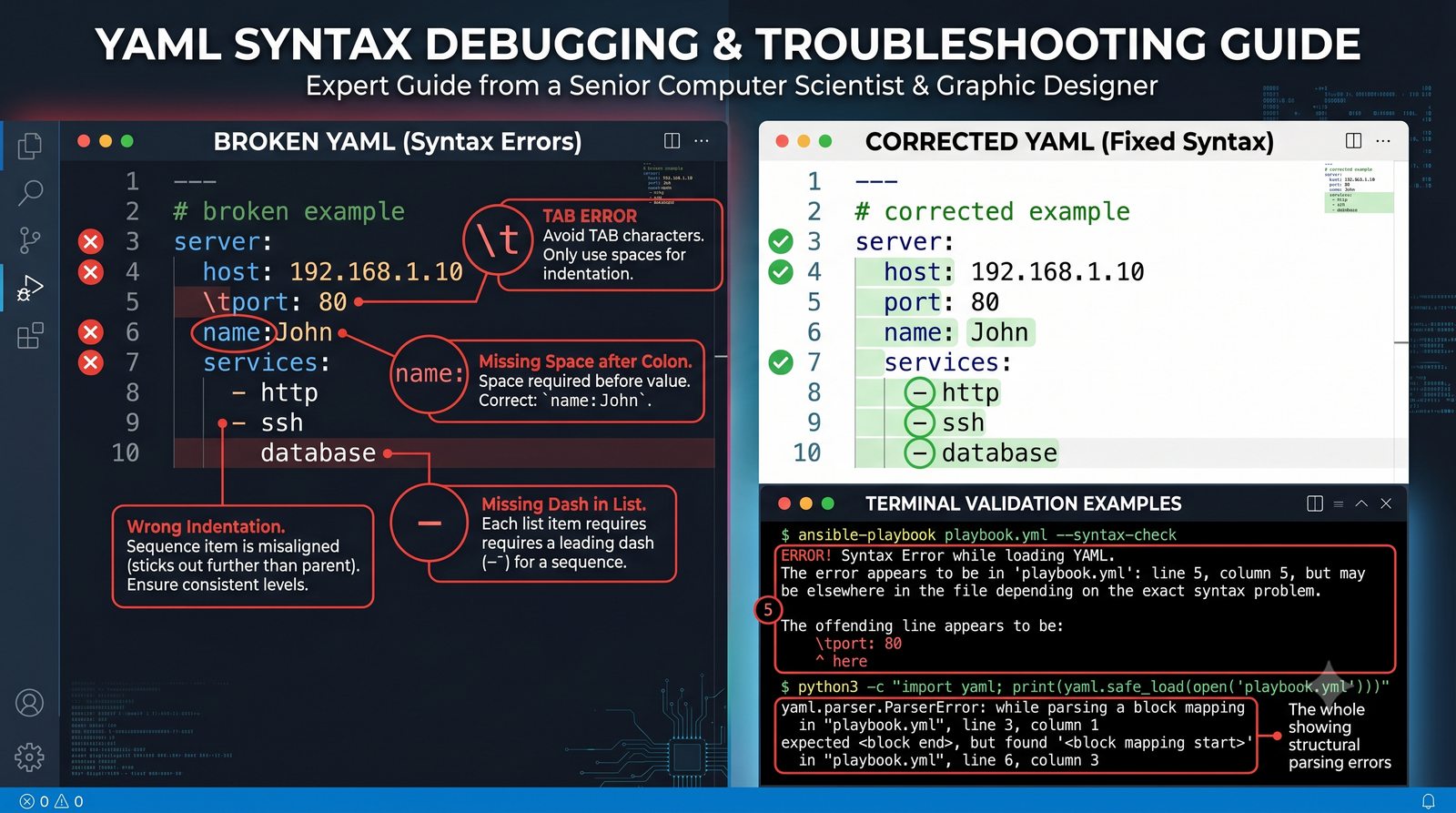
Warsztat praktyczny obejmuje napisanie playbooka instalującego serwer Nginx z wykorzystaniem modułów apt, copy, service oraz handlera do restartu usługi.