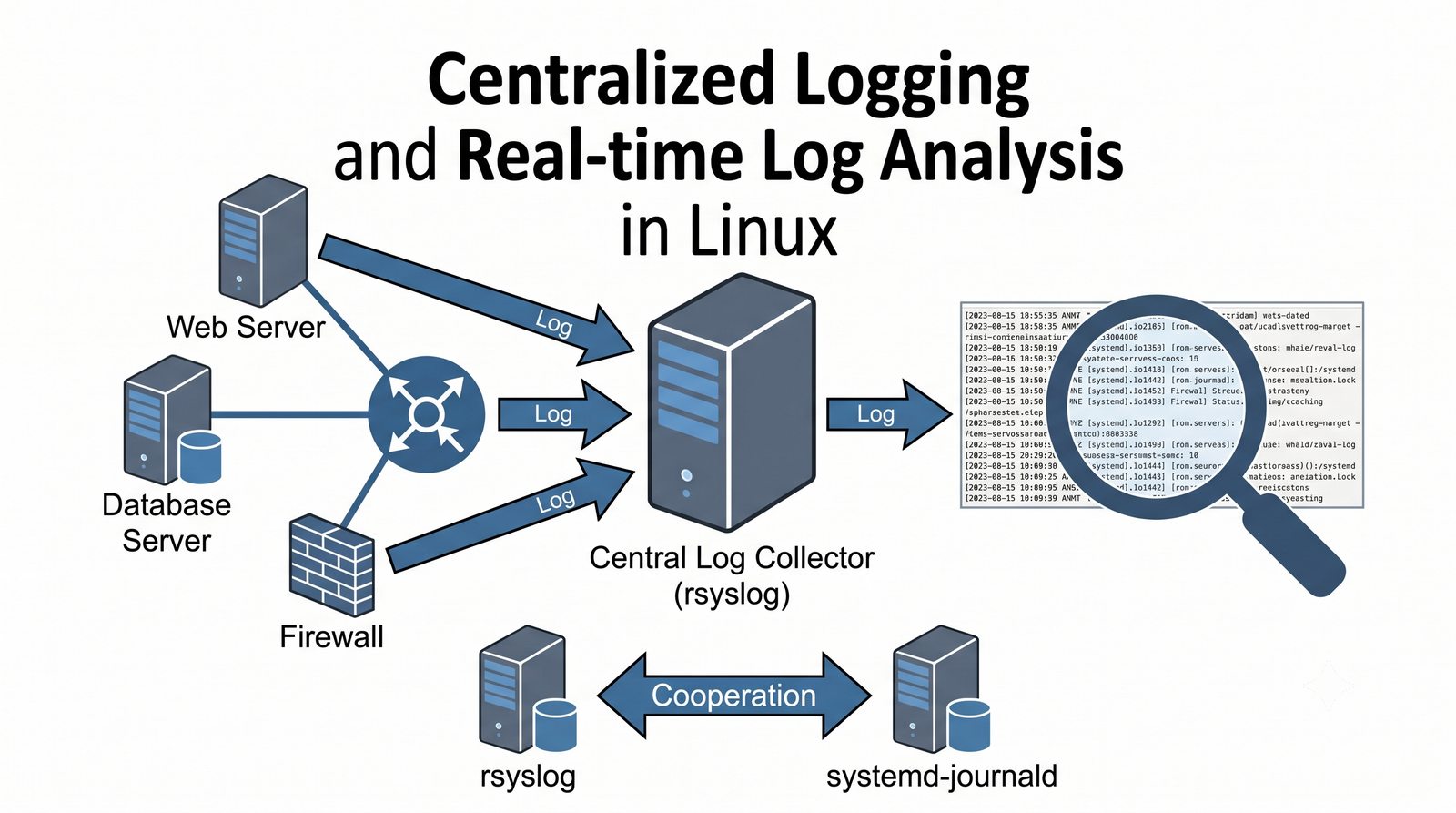
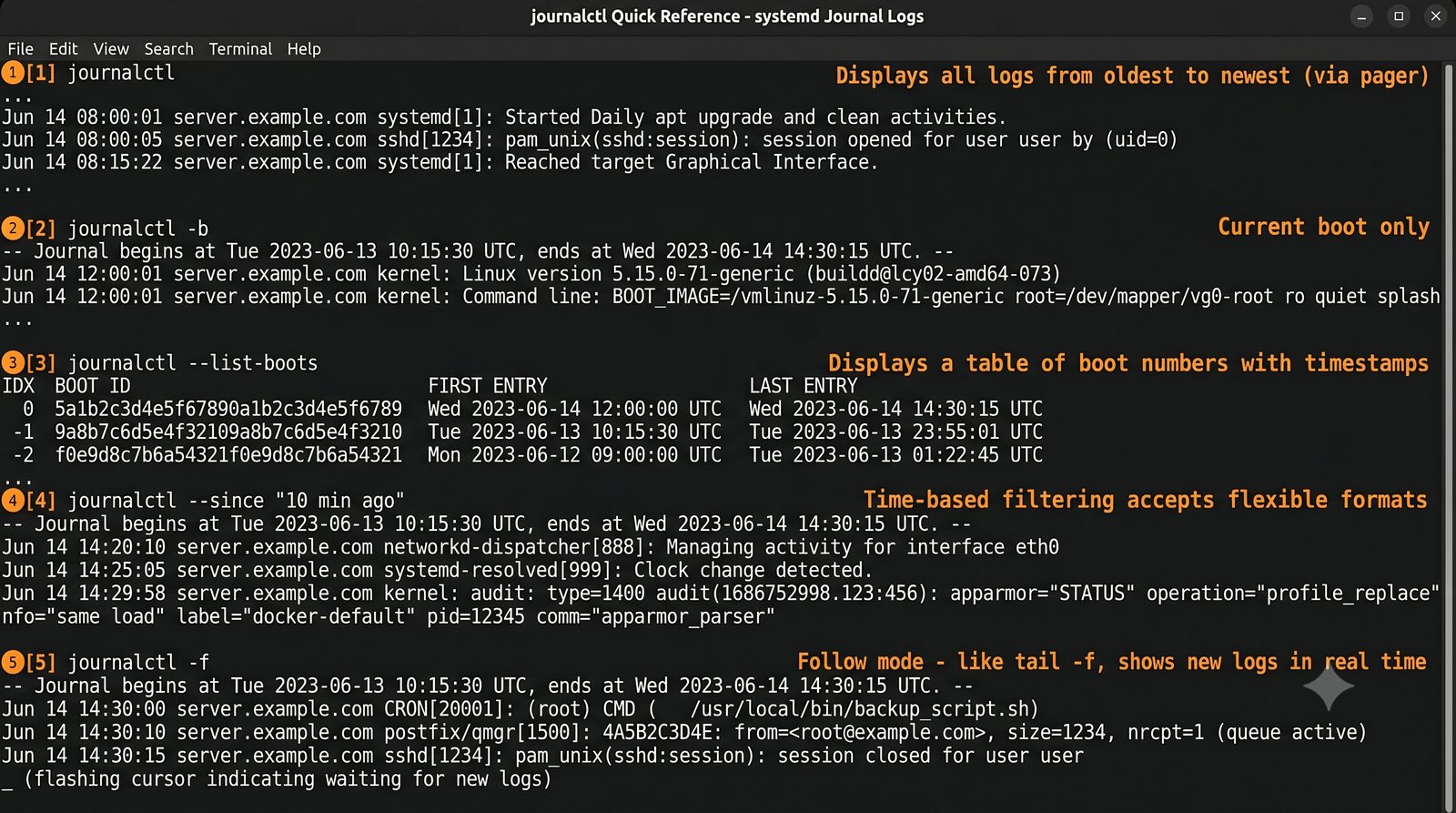
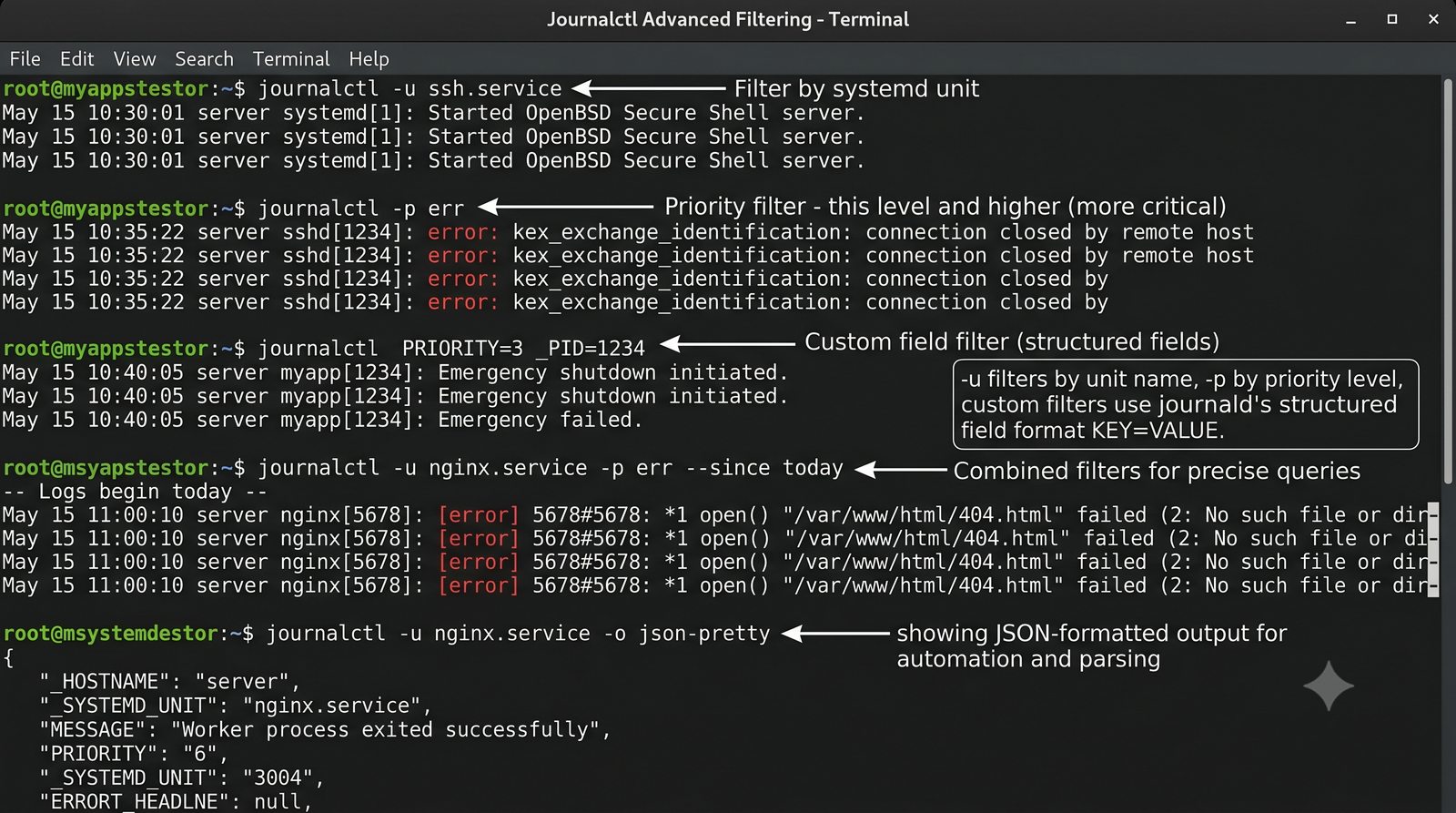
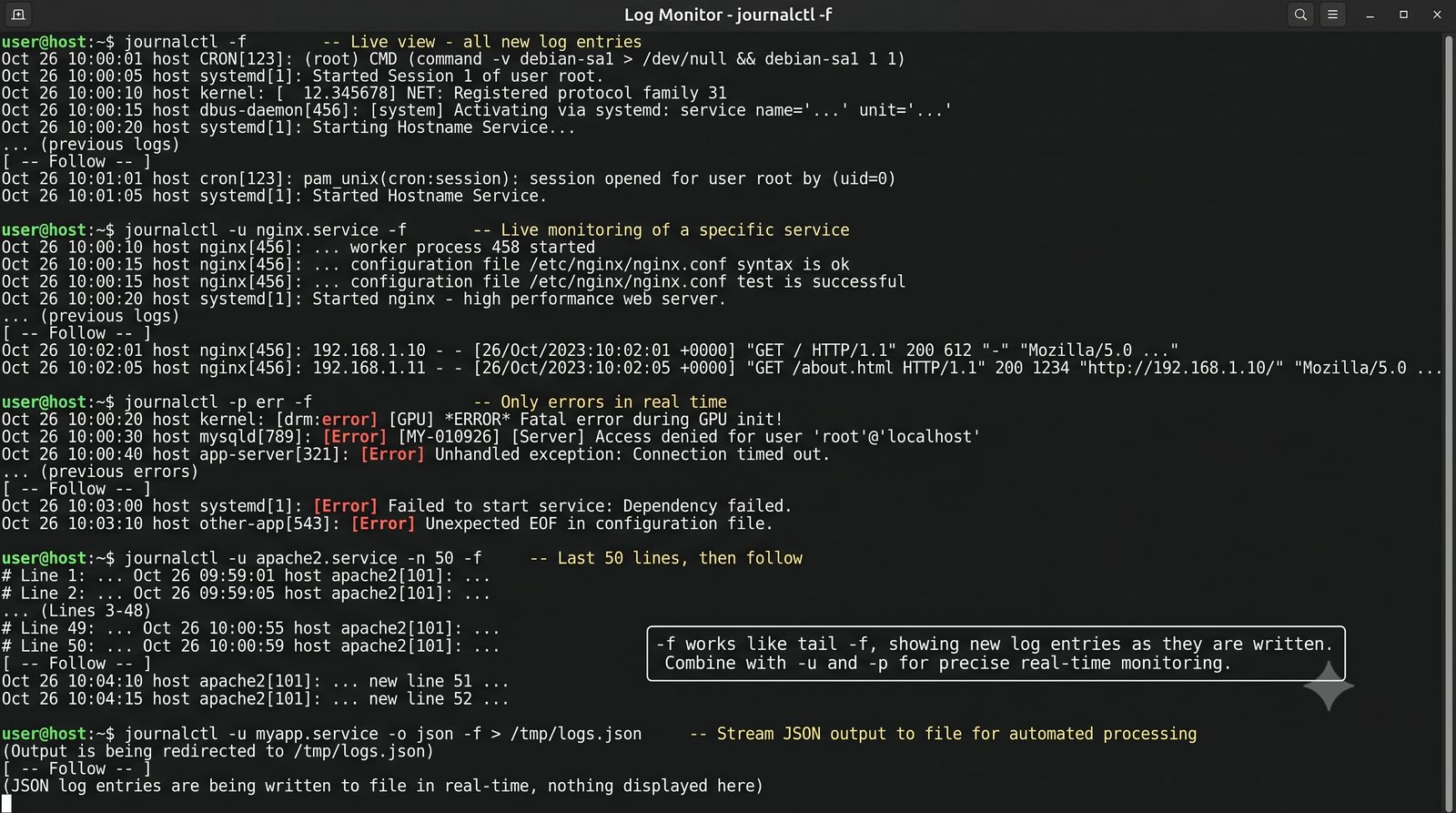
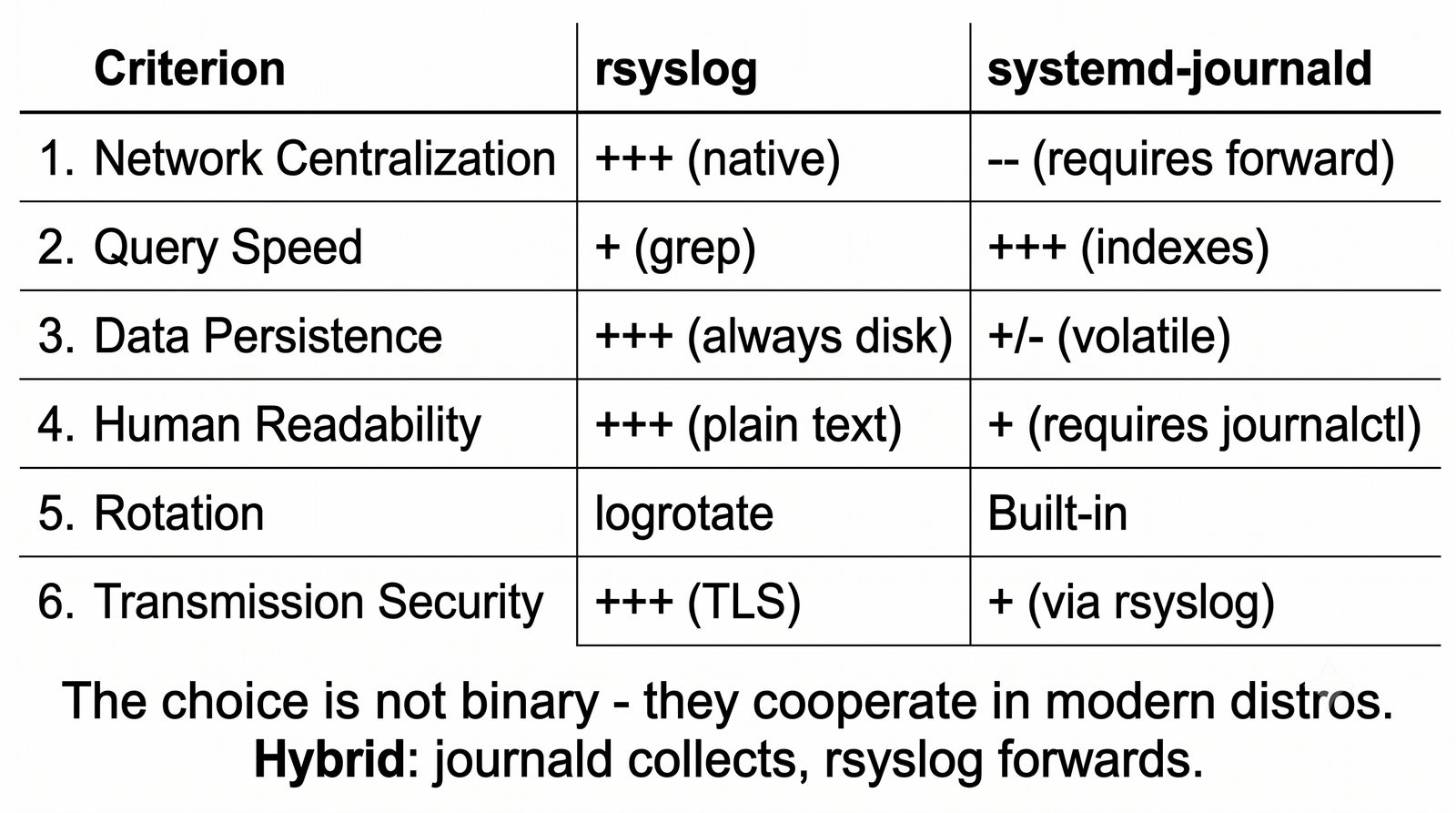
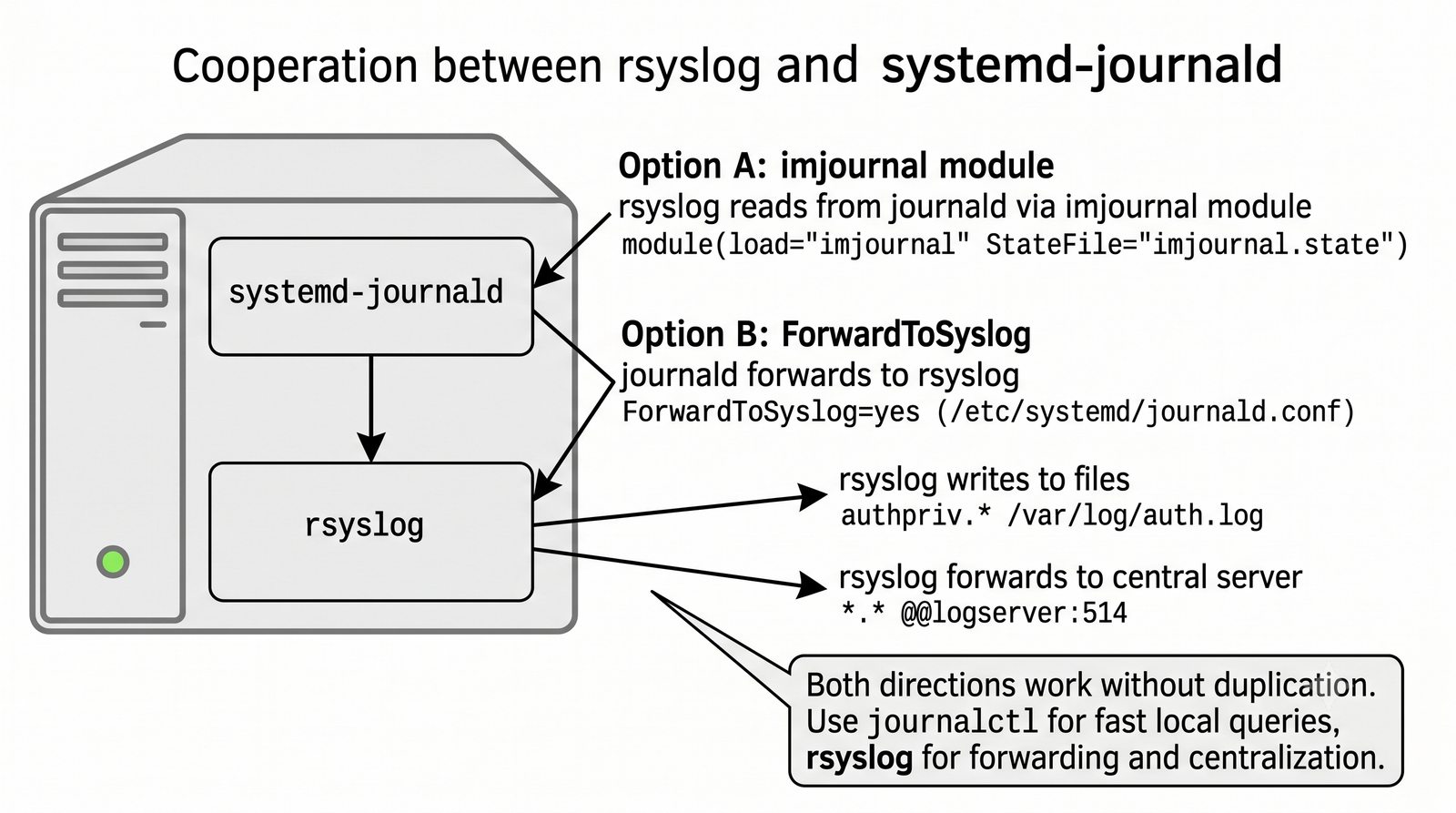
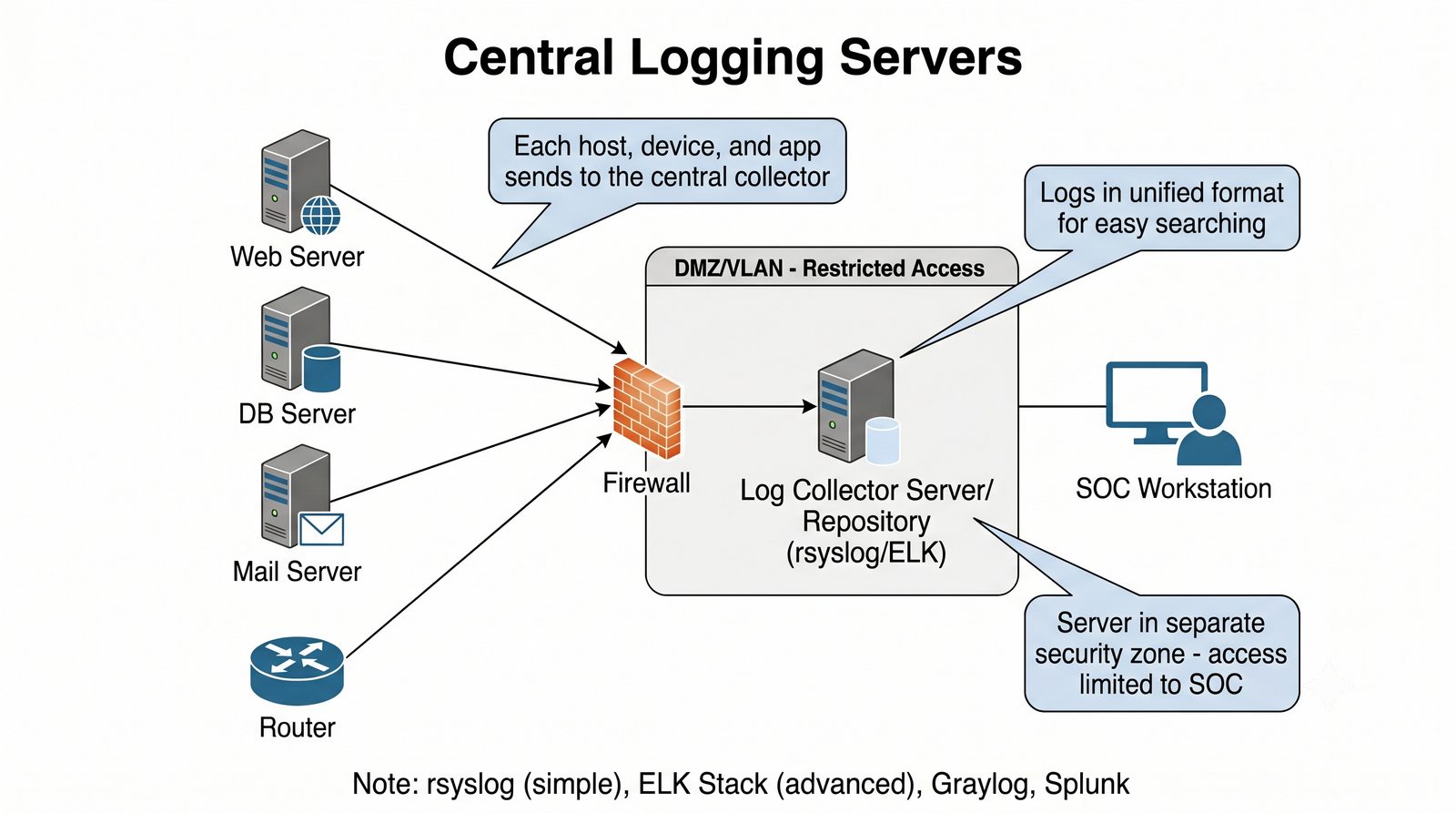
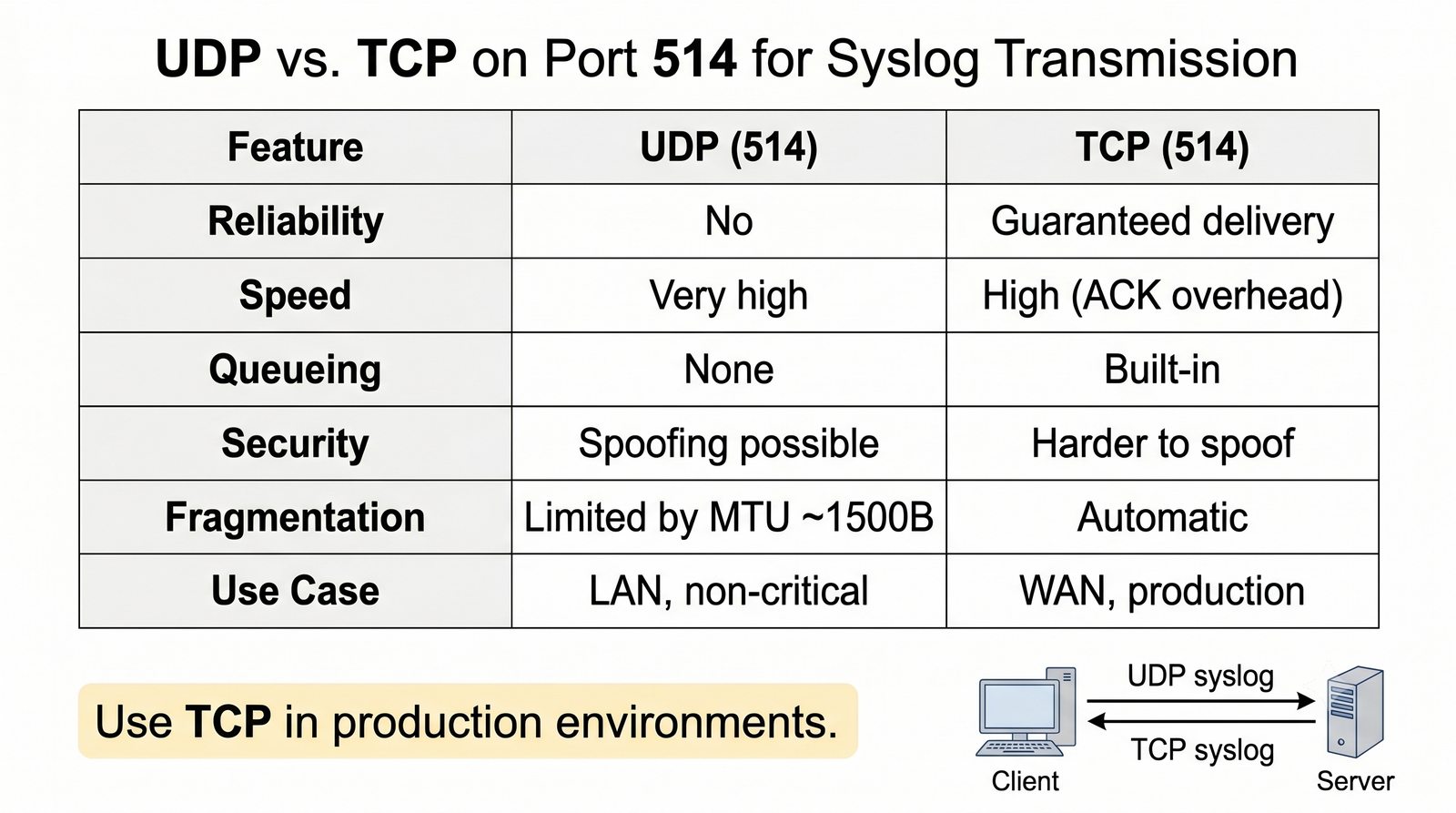
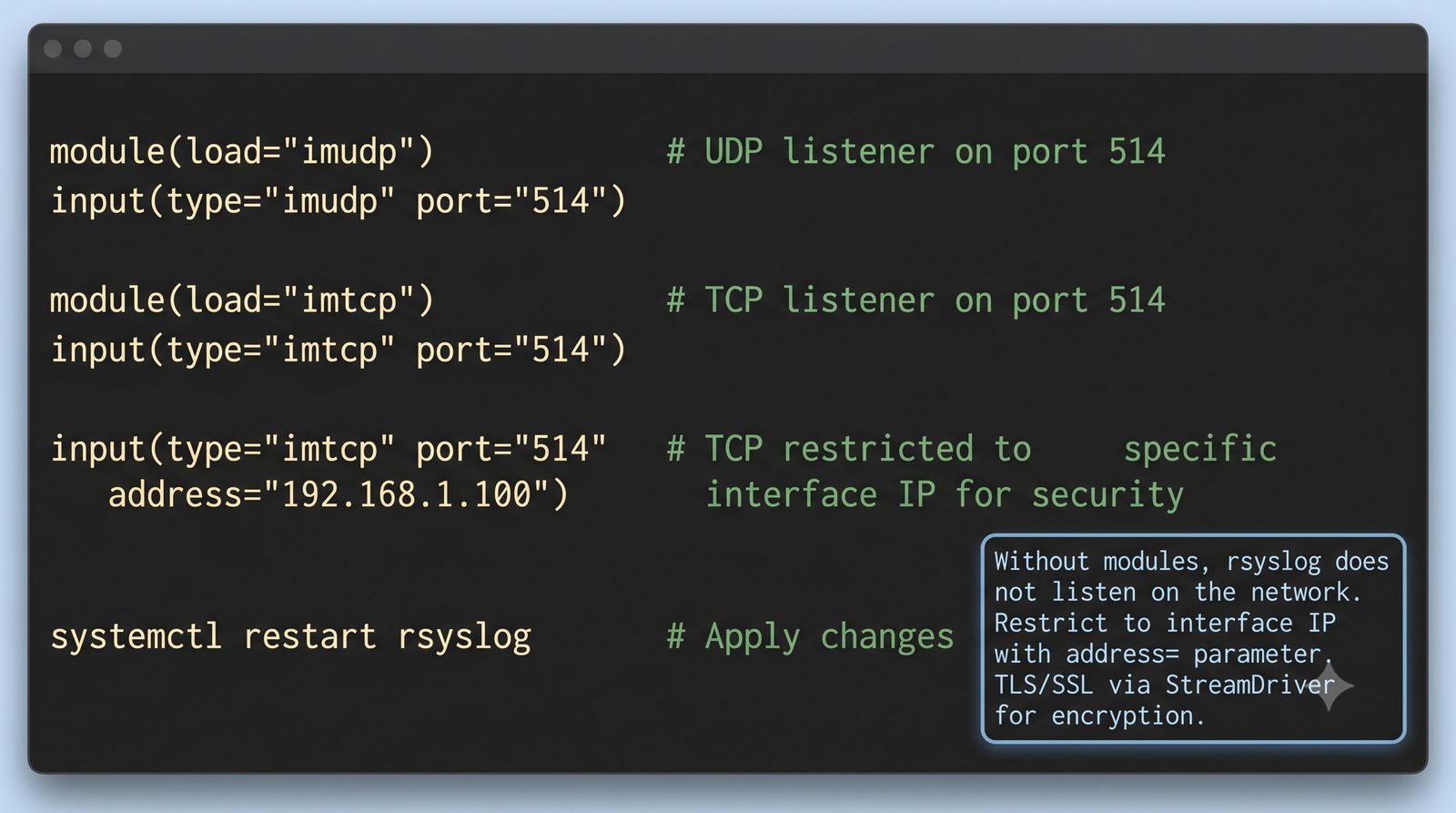
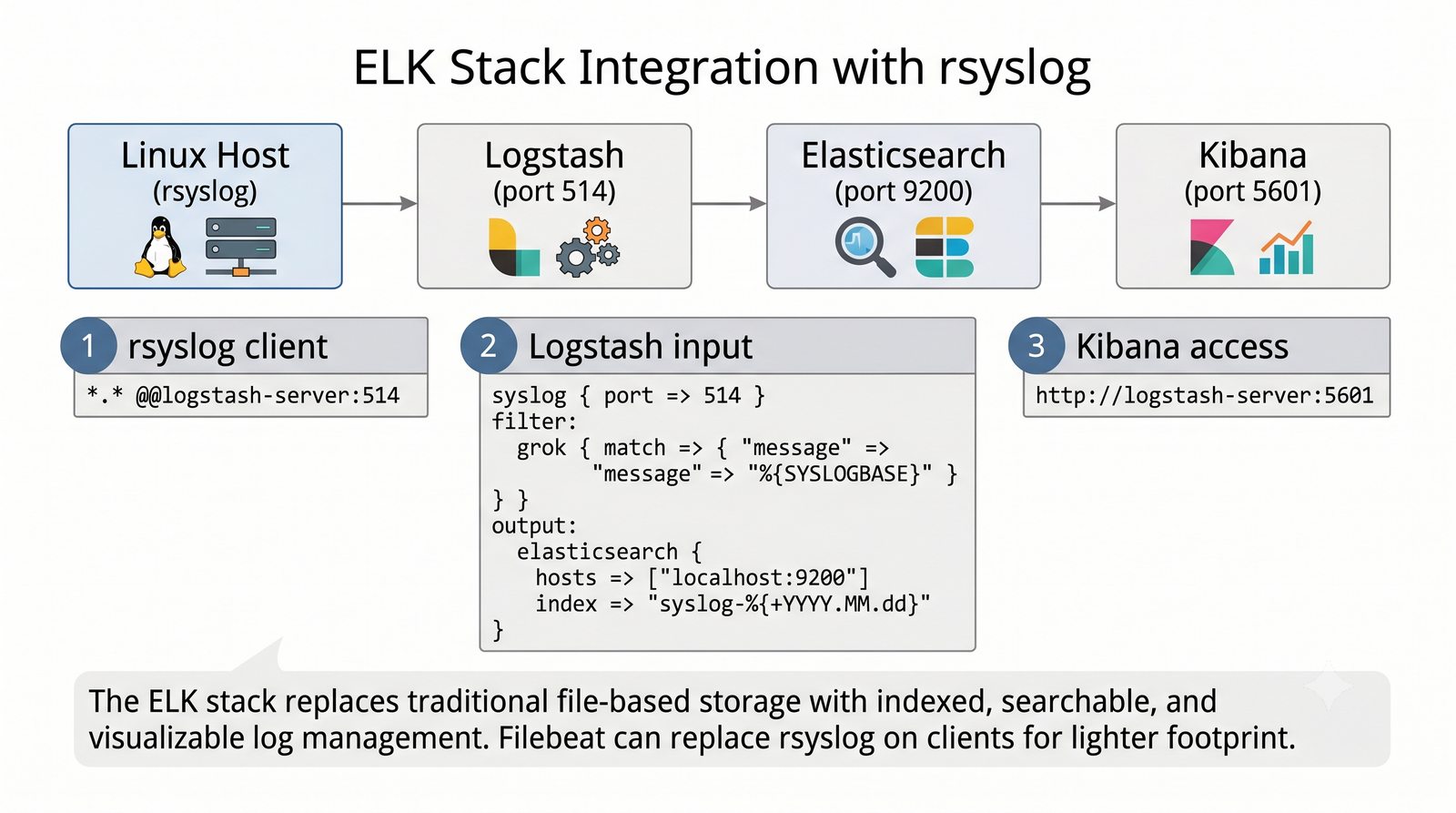
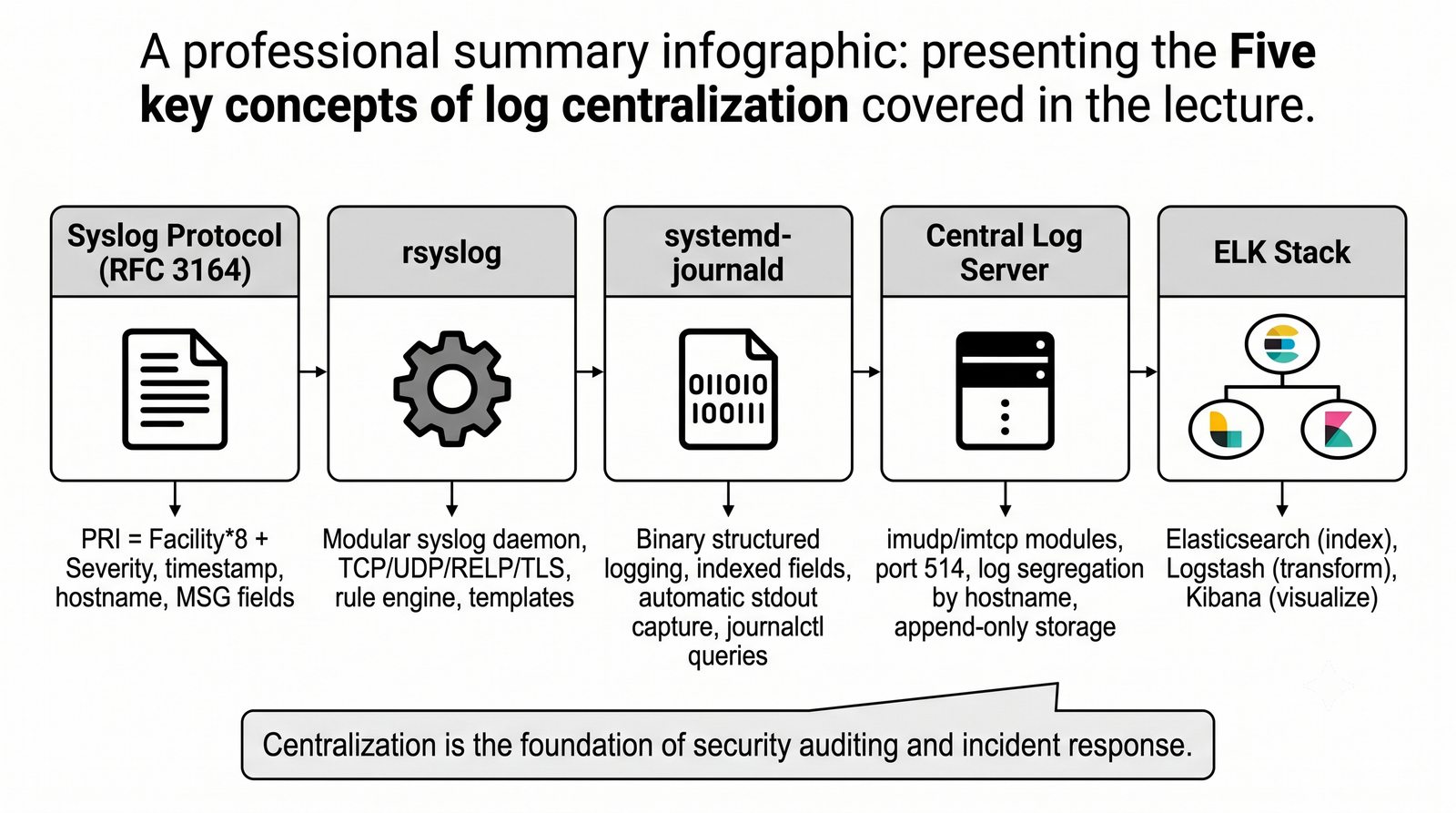
ELK to obecnie najpopularniejszy stos do analizy logów w dużych środowiskach.
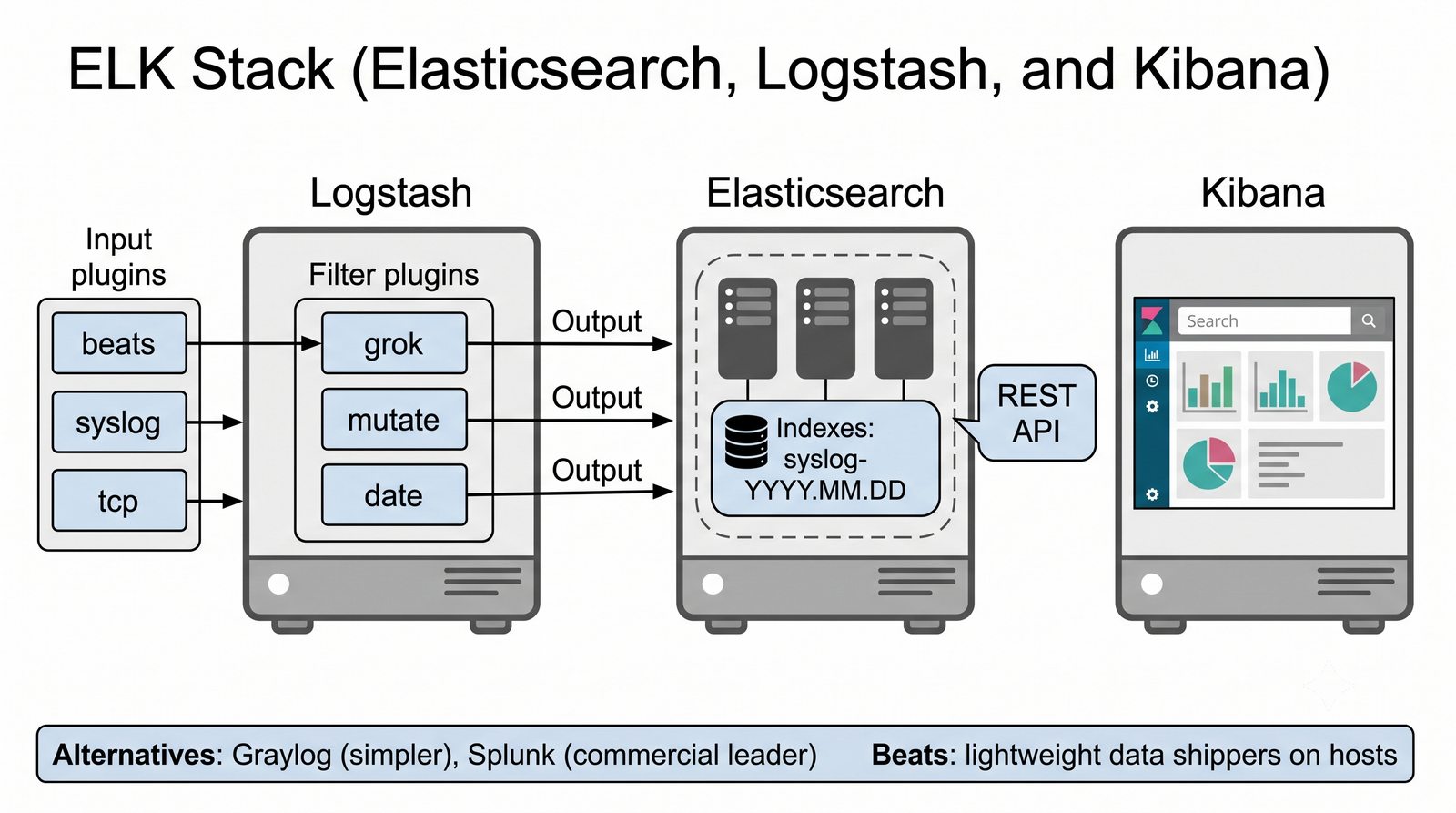
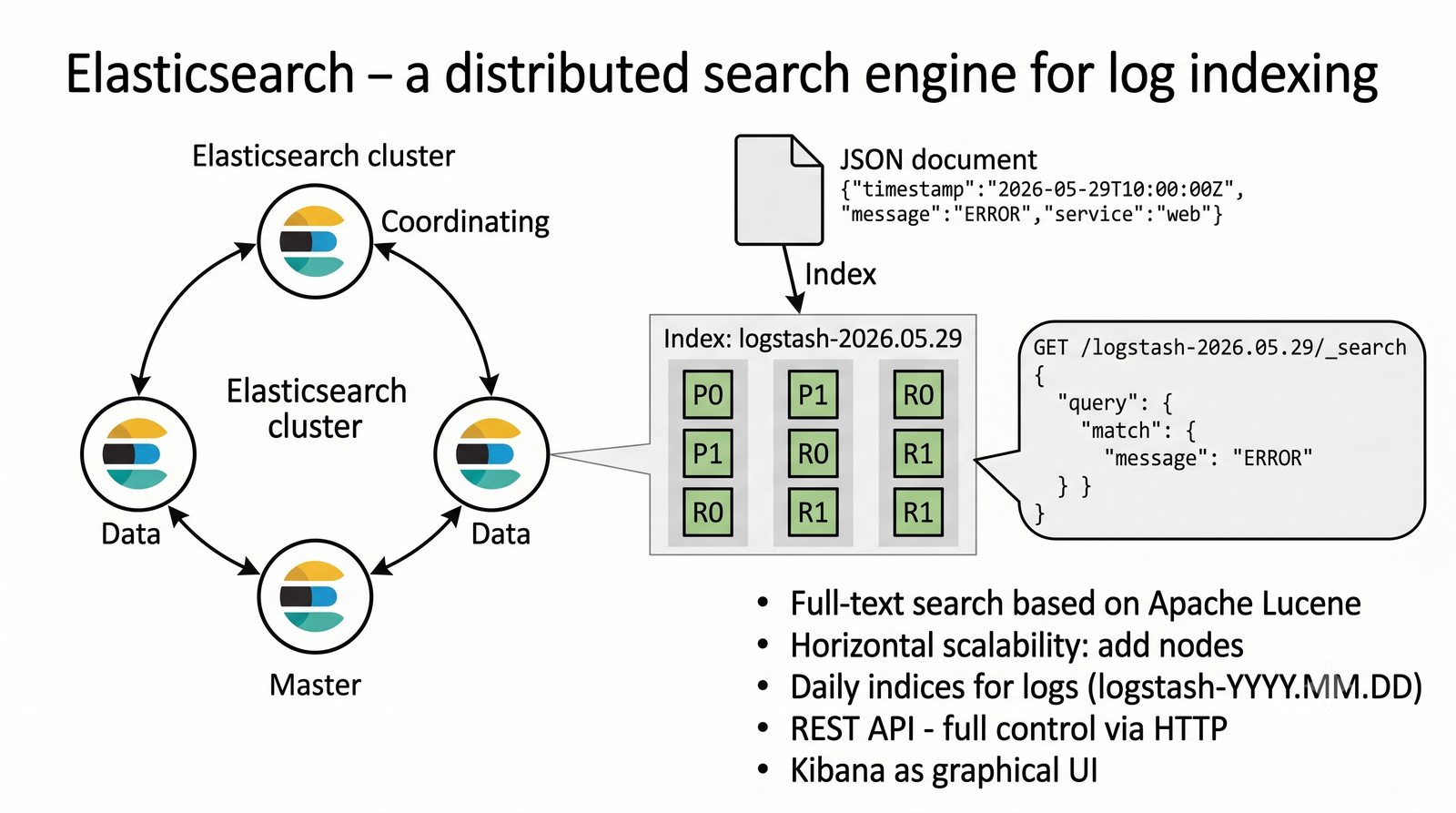
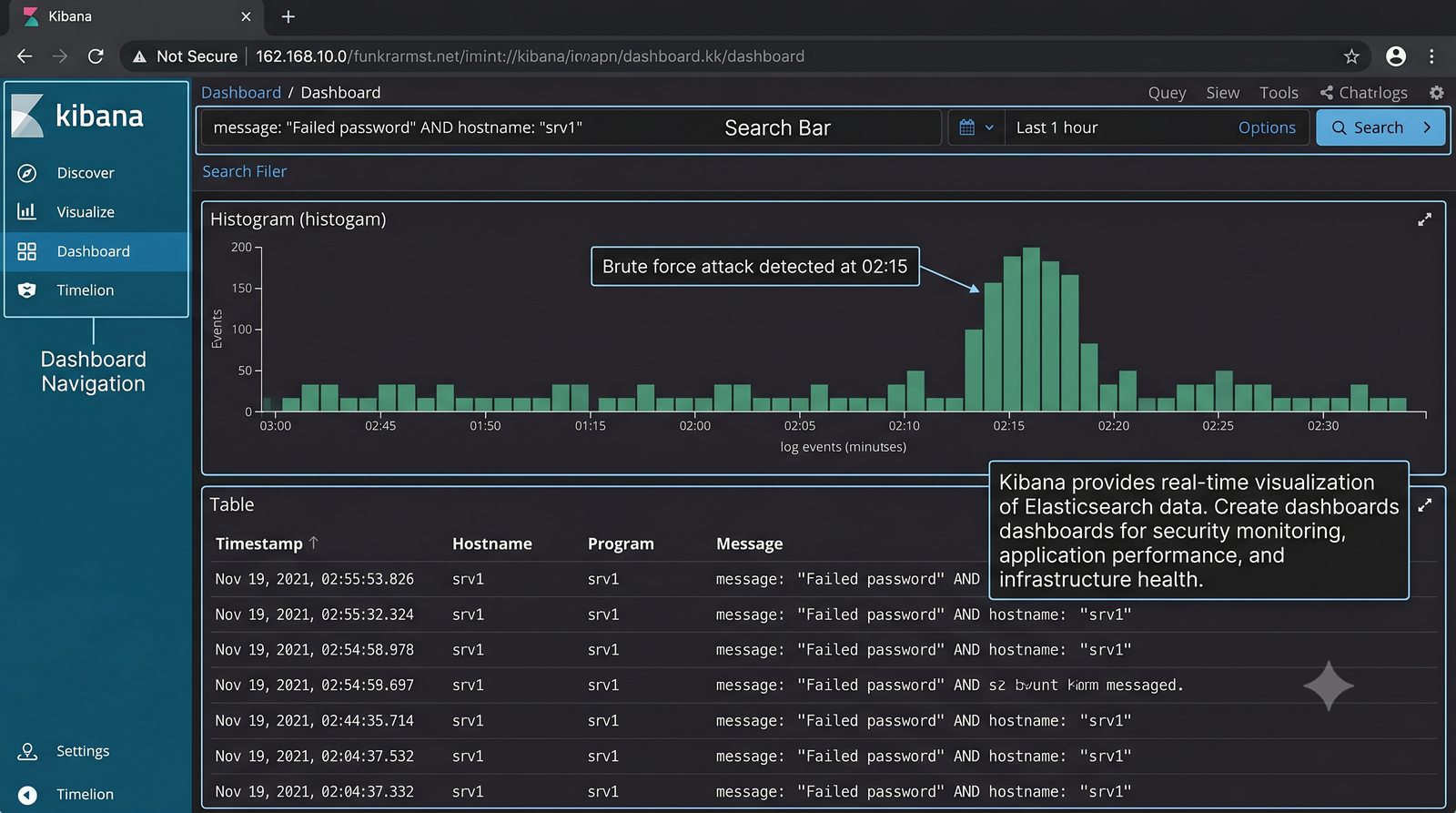
Elasticsearch indeksuje dane w czasie rzeczywistym, Logstash transformuje, Kibana wizualizuje.
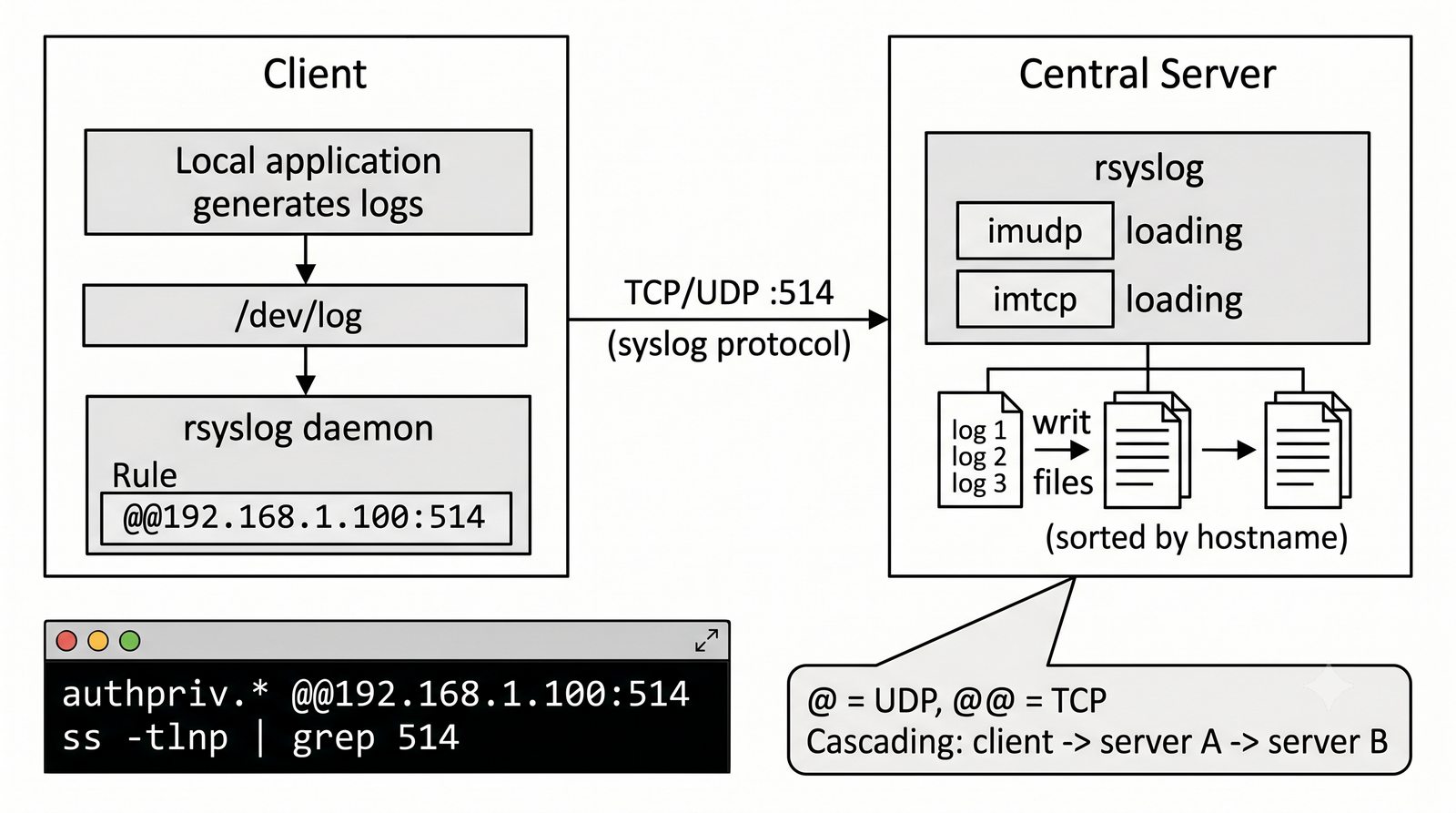
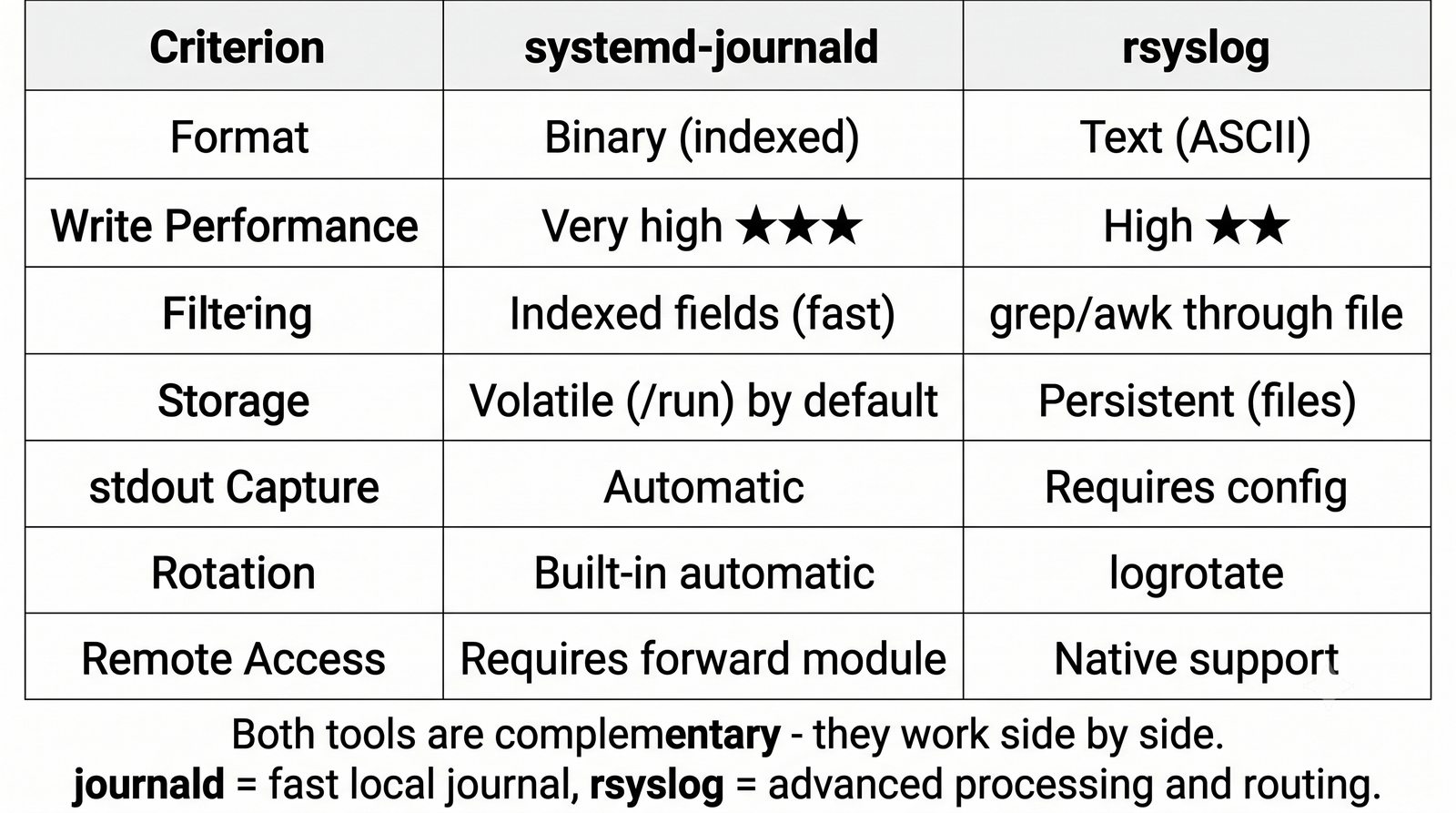
Graylog łączy funkcje kolektora i interfejsu w jednym produkcie, Splunk jest liderem komercyjnym.
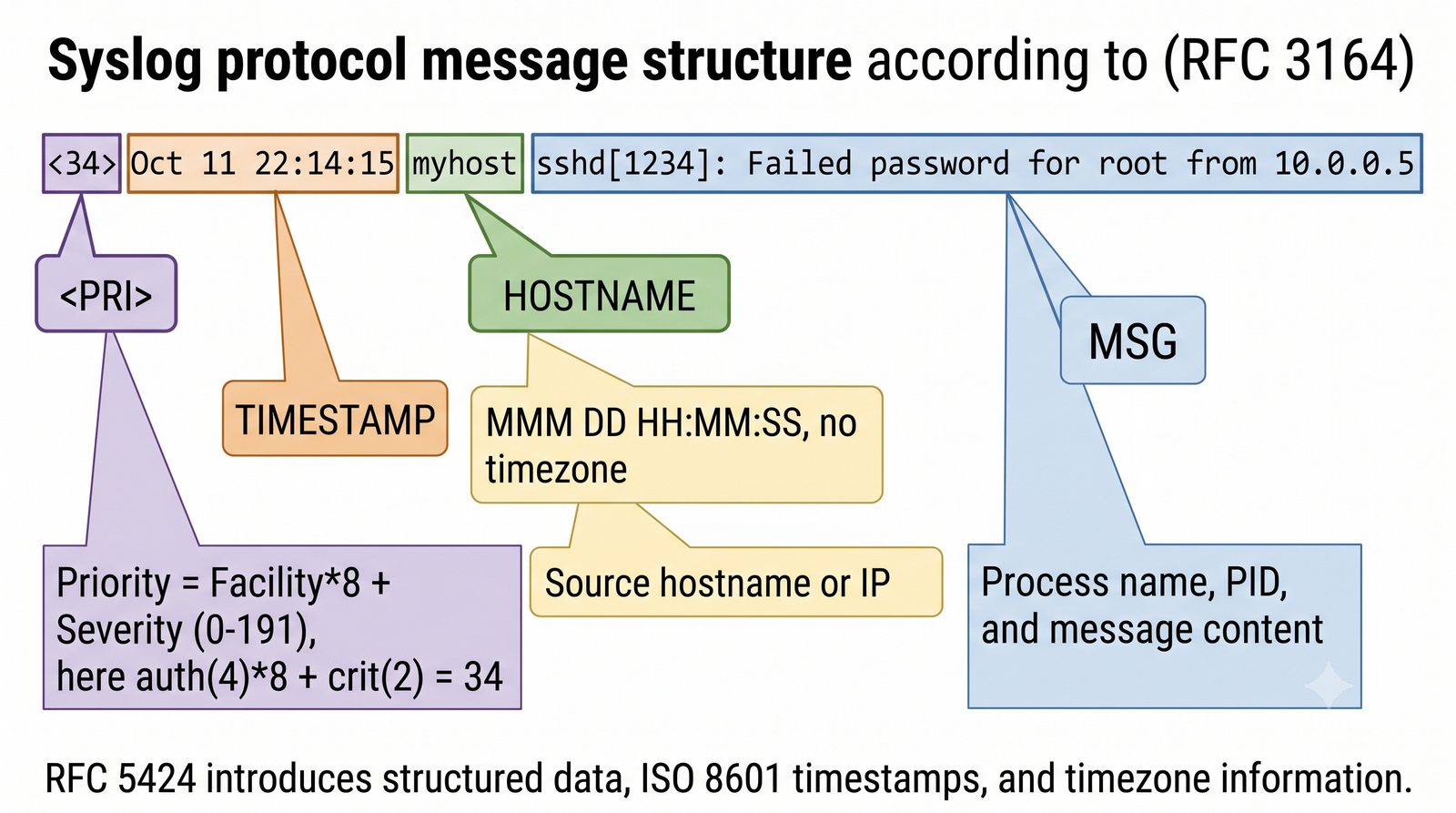
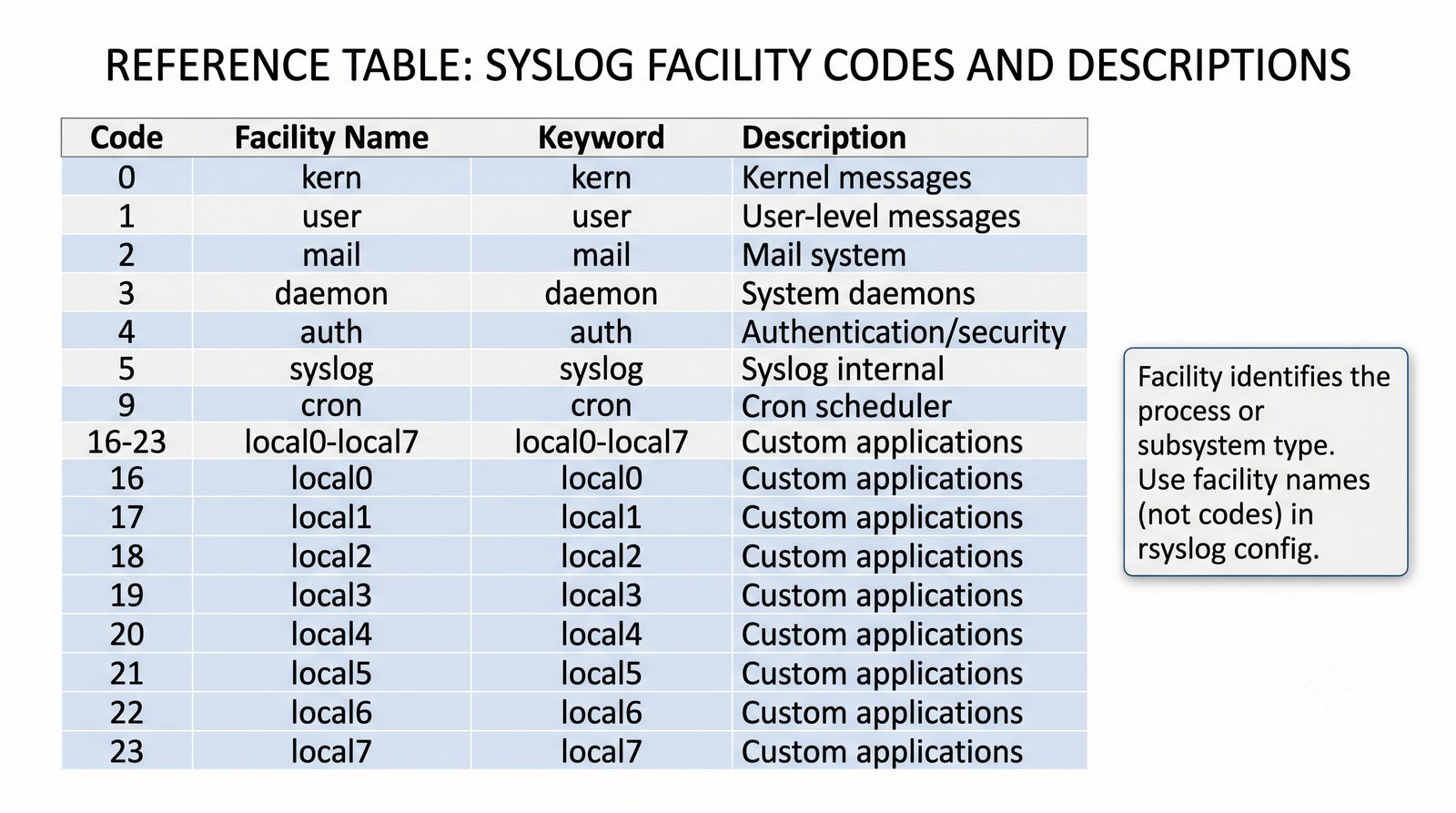
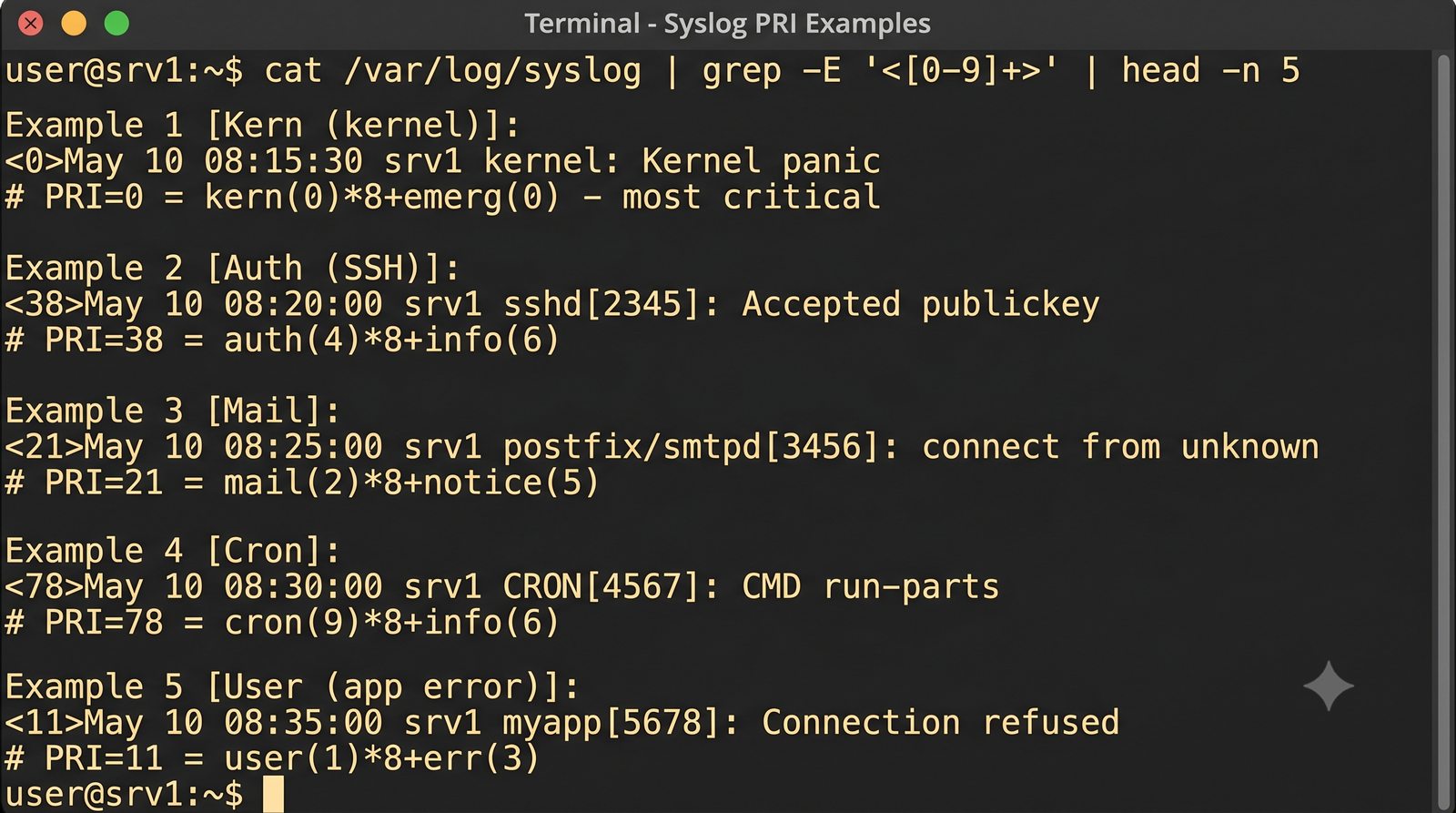
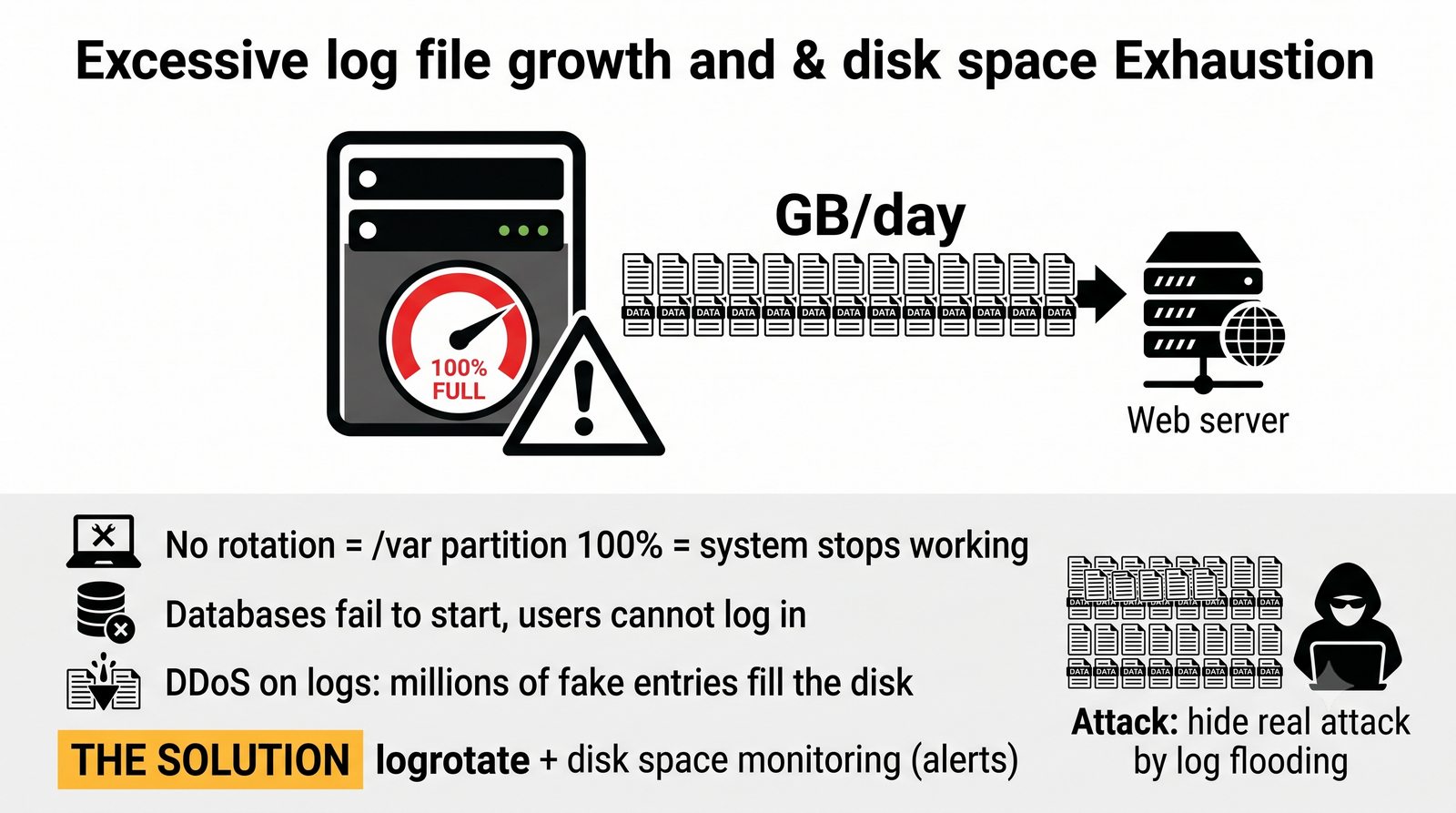
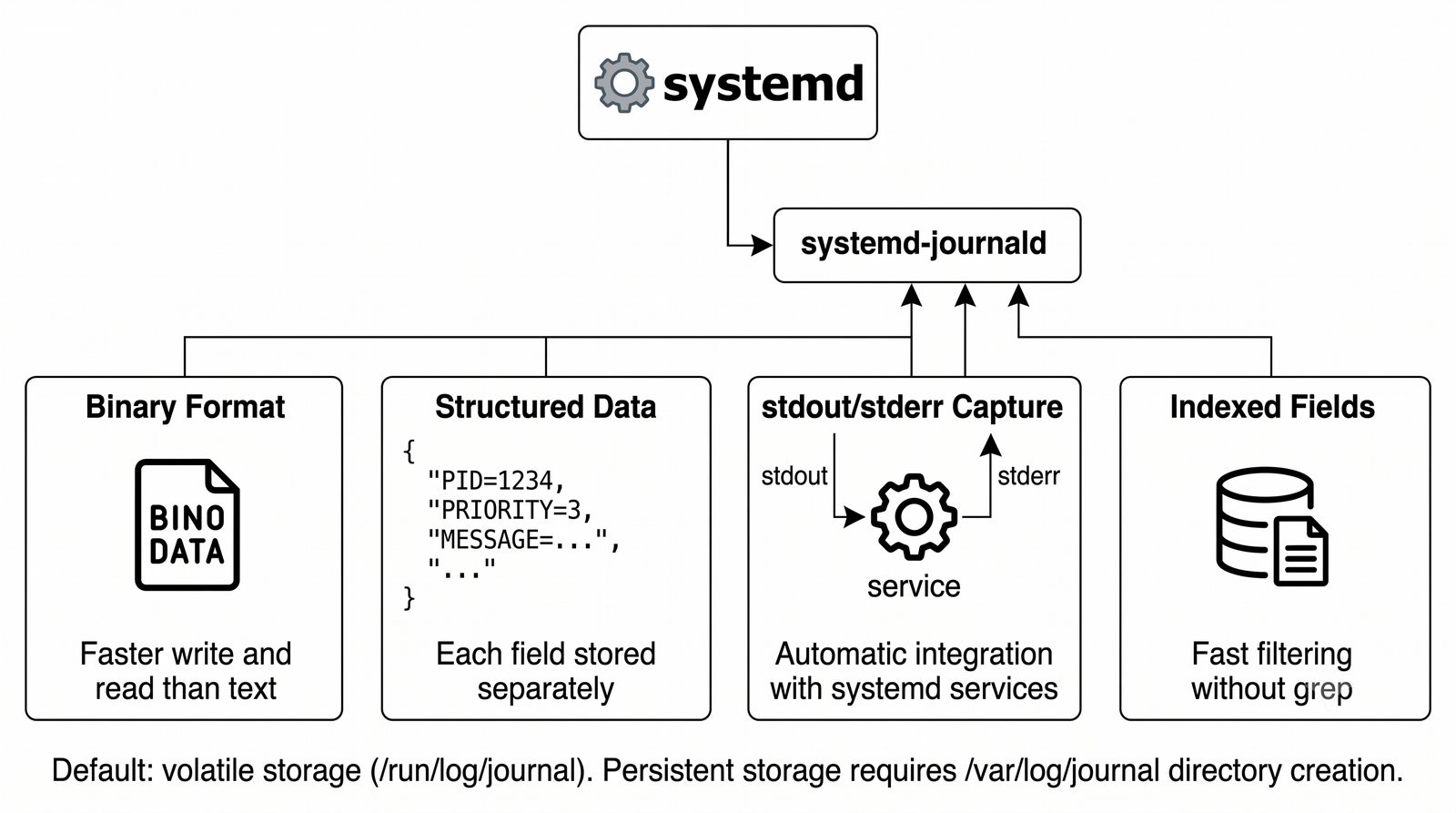
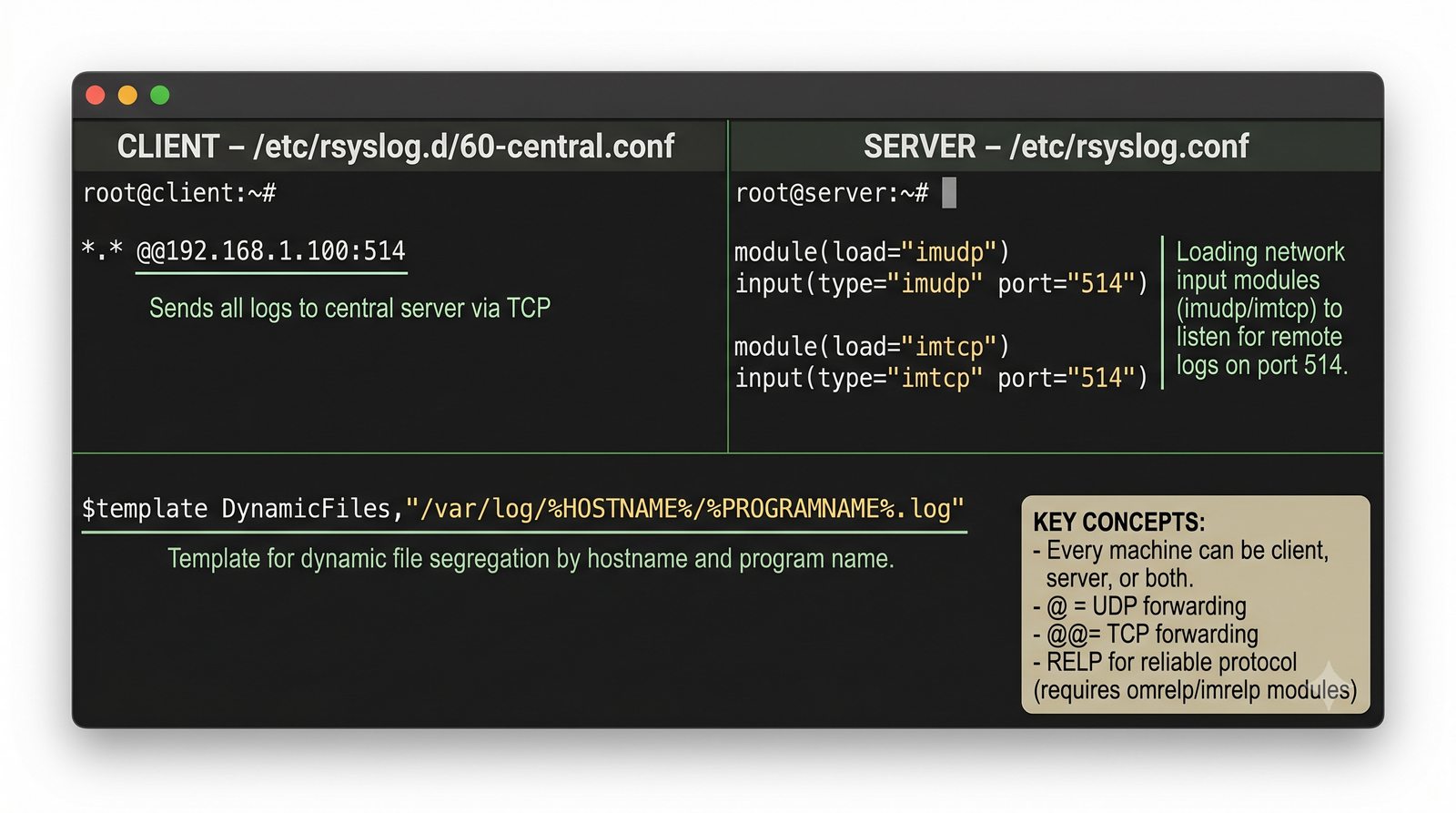
Stos ELK (Elasticsearch, Logstash, Kibana) jest rozwijany przez firmę Elastic i dostępny w wersji open source (z ograniczeniami w darmowej licencji podstawowej) oraz w płatnych wersjach oferujących dodatkowe funkcje bezpieczeństwa, monitorowania i alertowania.
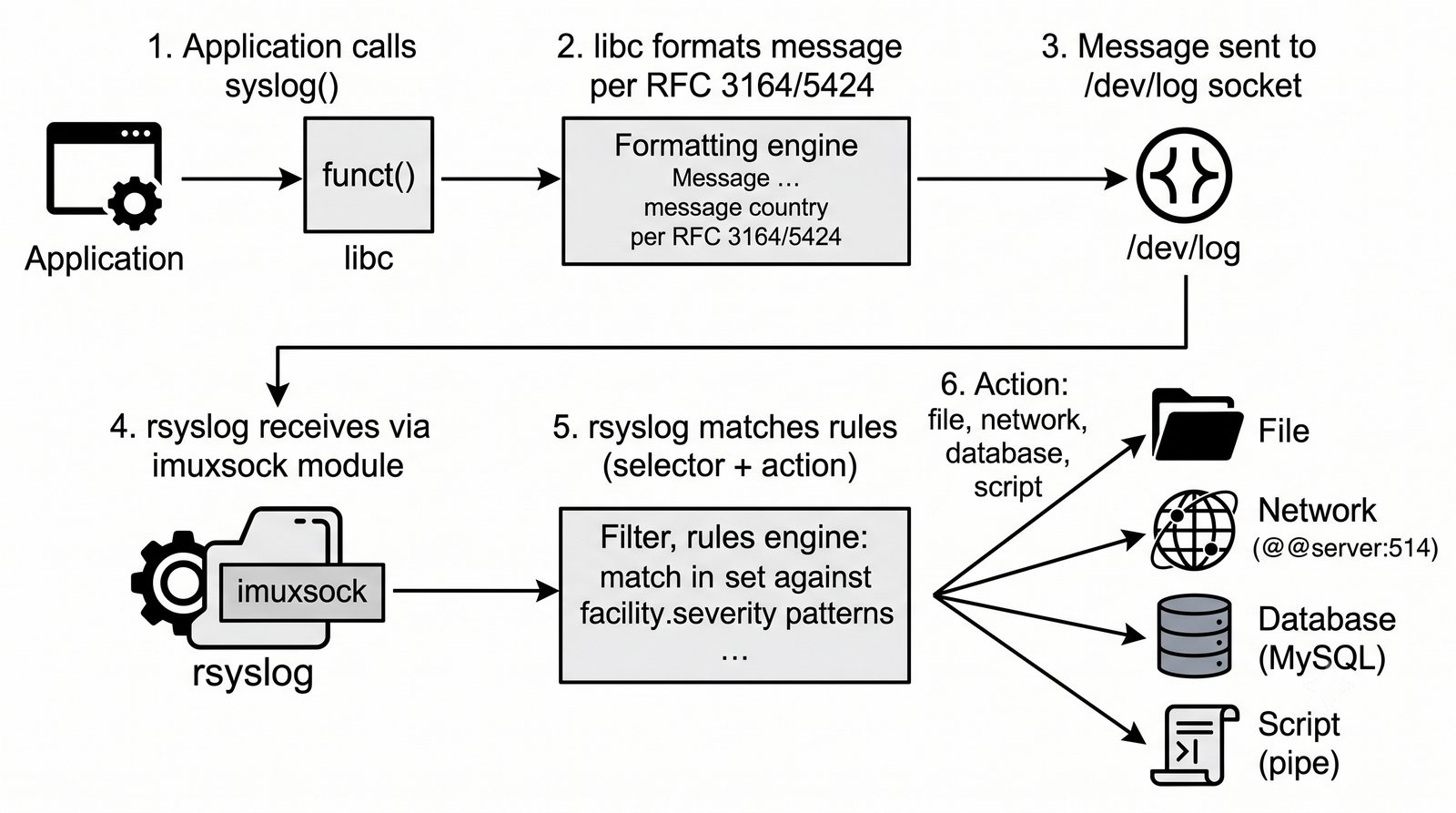
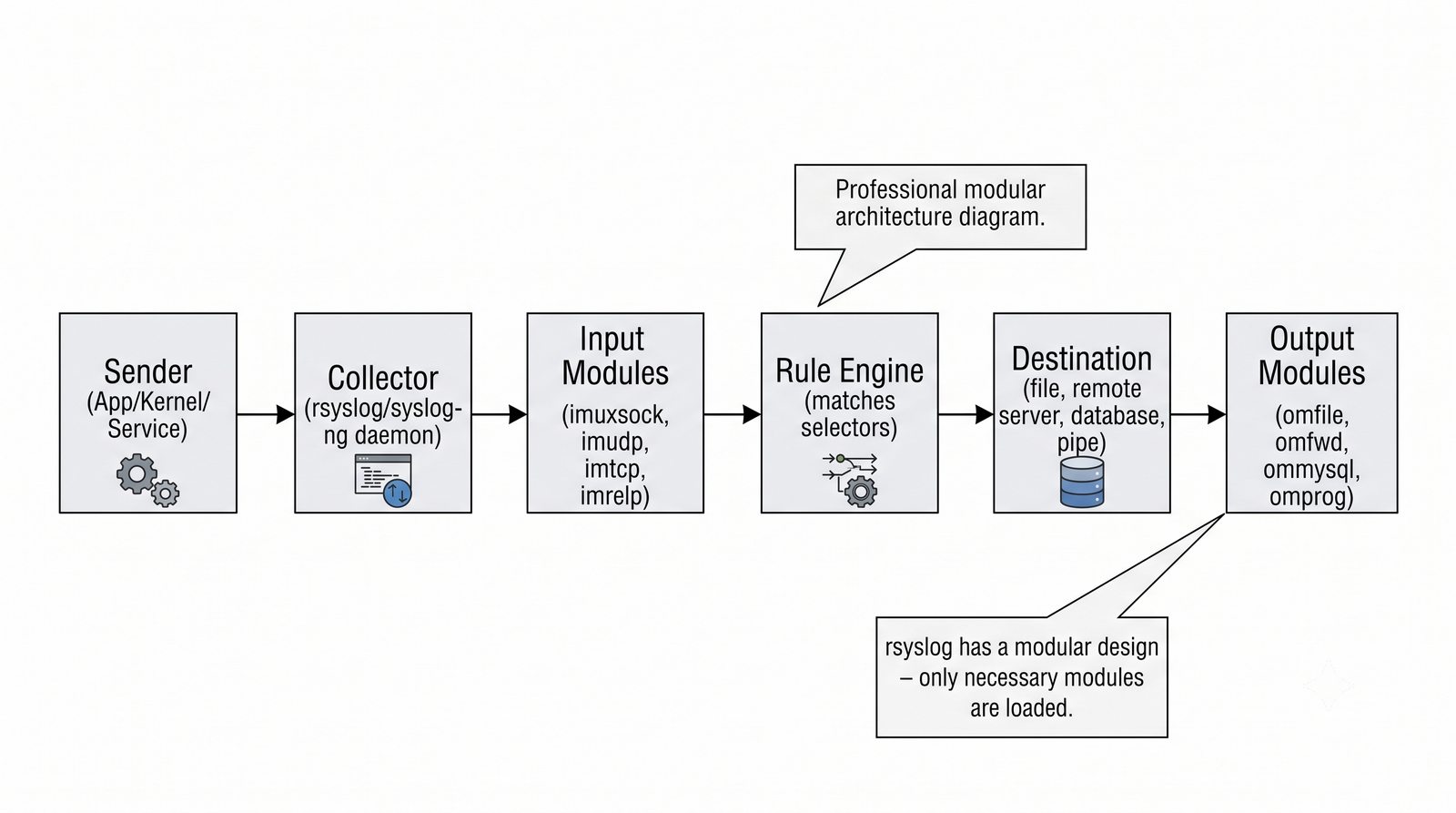
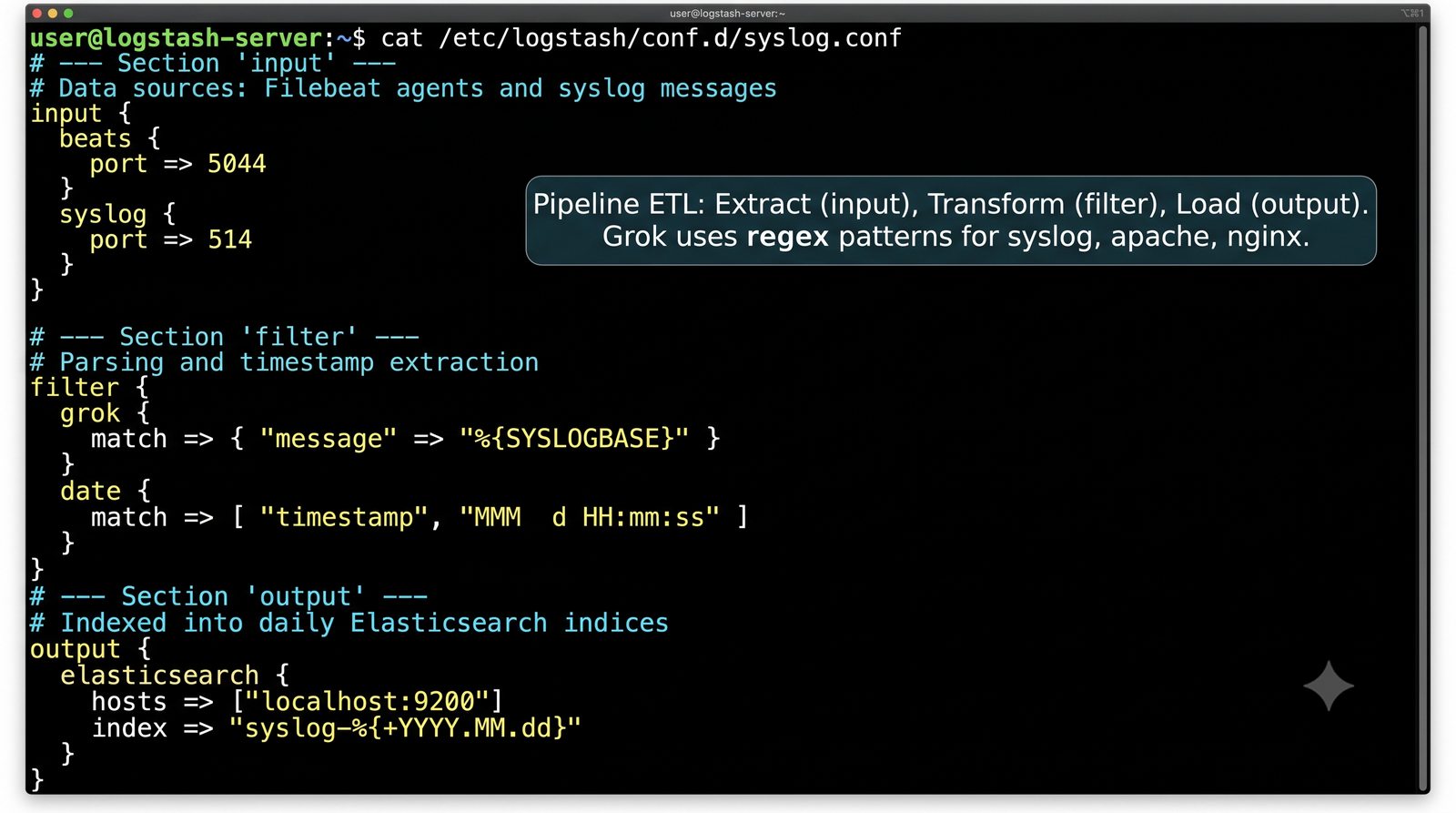
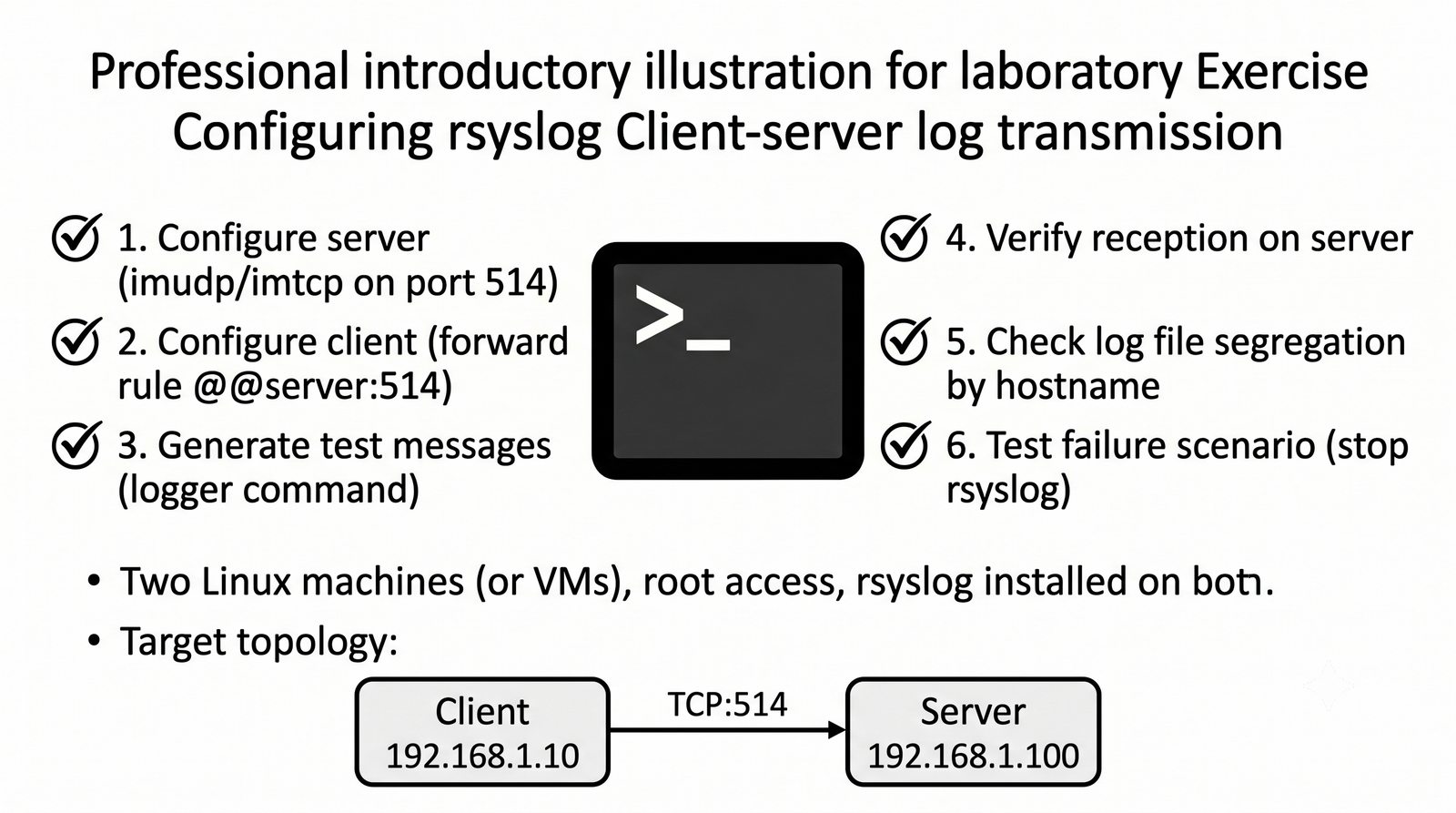
Logstash pełni funkcję potoku ETL (Extract, Transform, Load) - odbiera logi z wielu źródeł (syslog, beat, HTTP, TCP/UDP), parsuje je za pomocą filtrów (grok, mutate, date, geoip) i wysyła do wybranego magazynu, którym najczęściej jest Elasticsearch, ale może być również Kafka, S3 lub plik.
Graylog stanowi prostszą alternatywę dla ELK, oferując wbudowany kolektor syslog, interfejs WWW z wyszukiwarką i dashboardami oraz mechanizm alertów w jednym zintegrowanym produkcie, co czyni go łatwiejszym w konfiguracji dla mniejszych zespołów.