Architektury sieci wirtualnych w systemie Linux
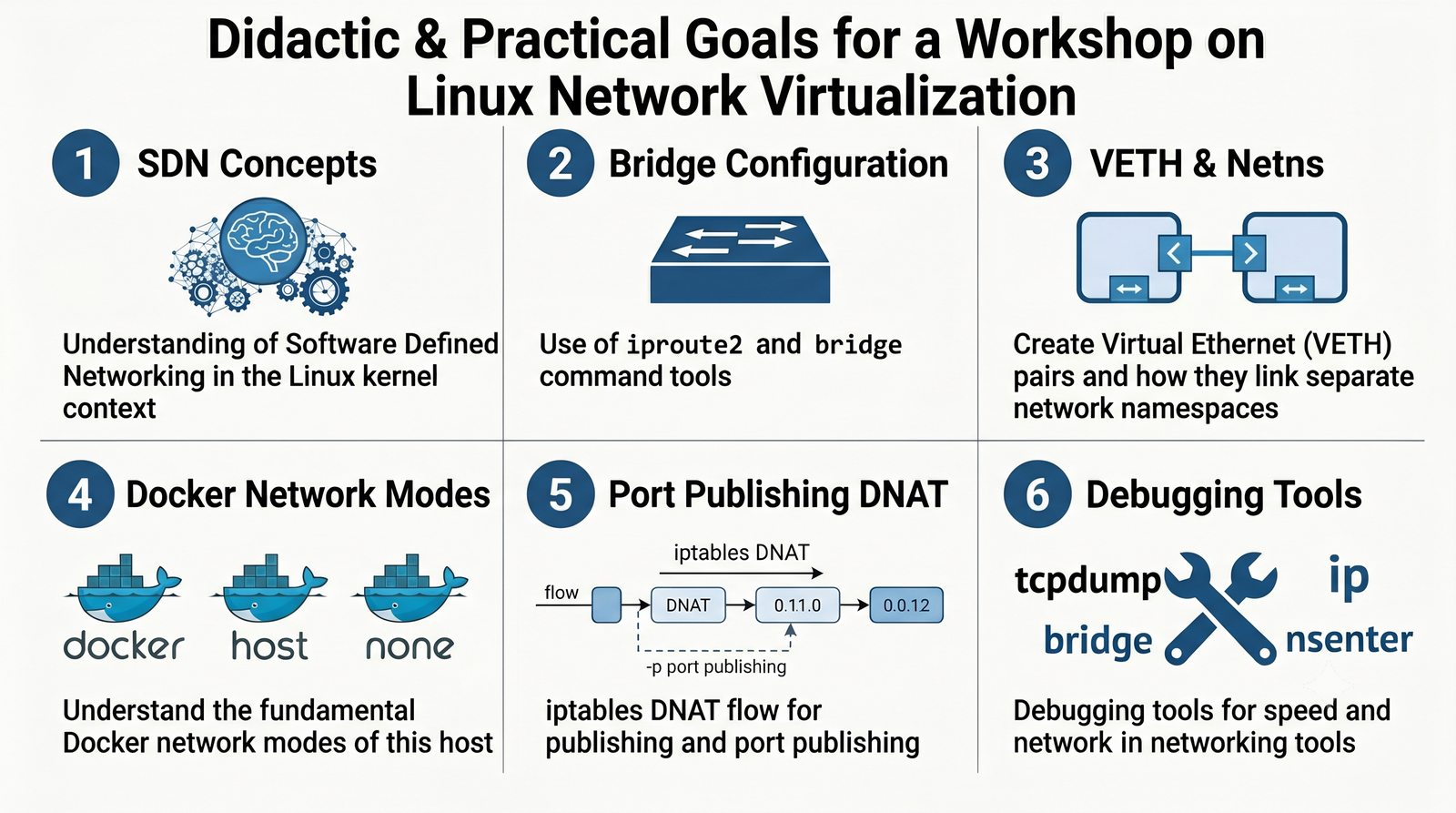
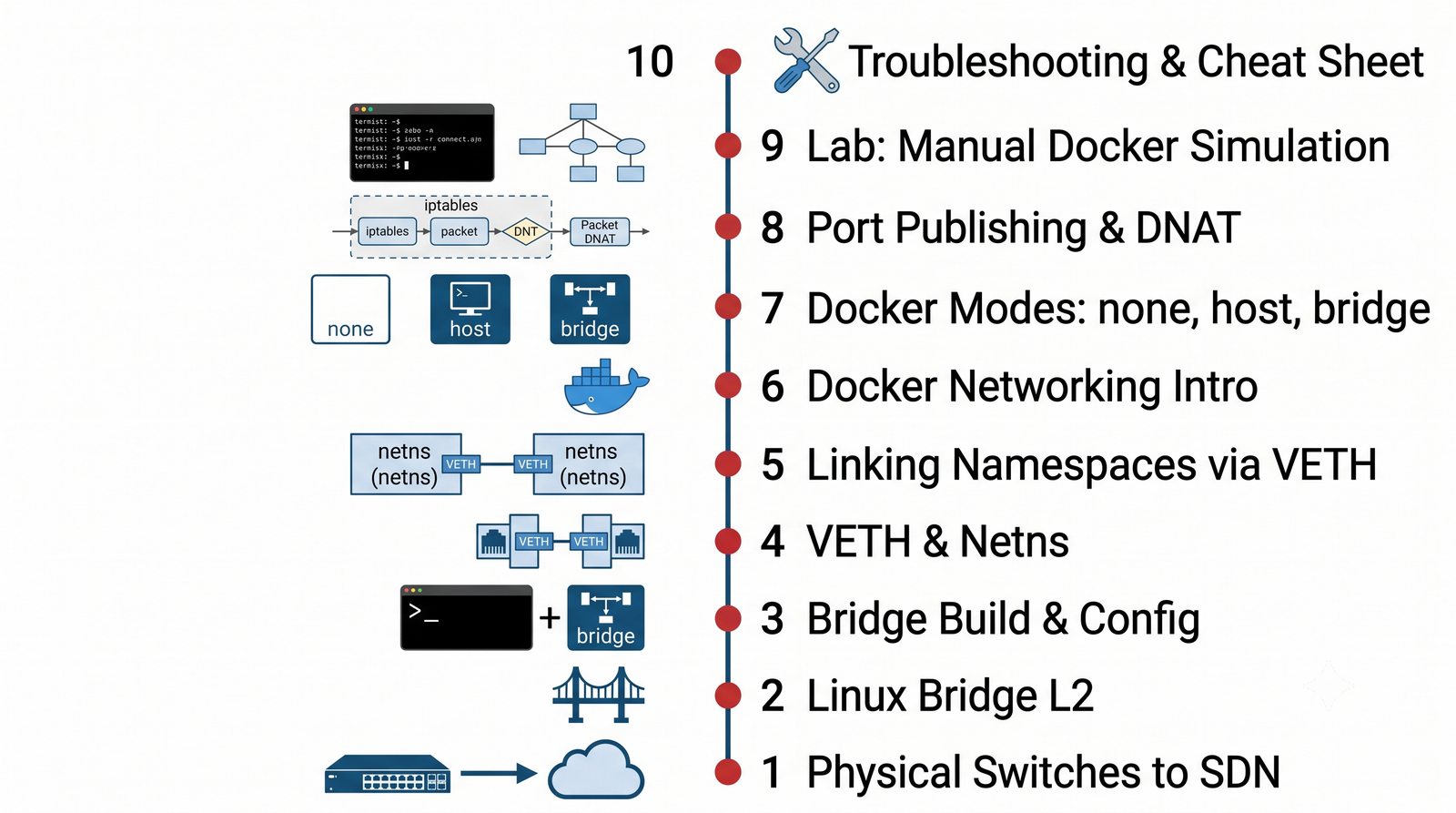
Prezentacja dotyczy zaawansowanych mechanizmów wirtualizacji sieci w systemie Linux, ze szczególnym uwzględnieniem mostków sieciowych (bridge), wirtualnych par Ethernet (VETH) oraz sieci w środowisku Docker. Materiał obejmuje zarówno podstawy teoretyczne, jak i praktyczne laboratorium.
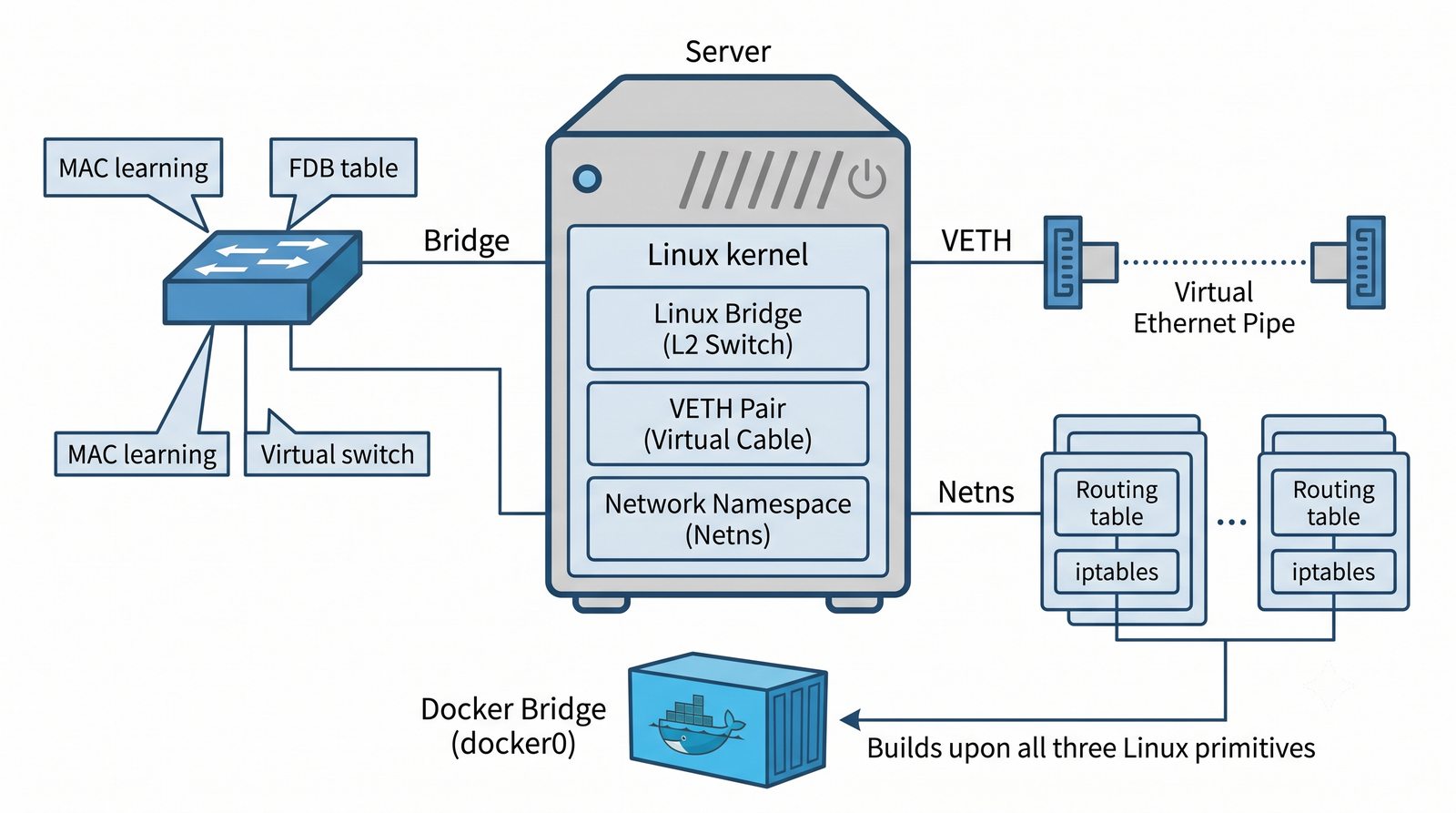
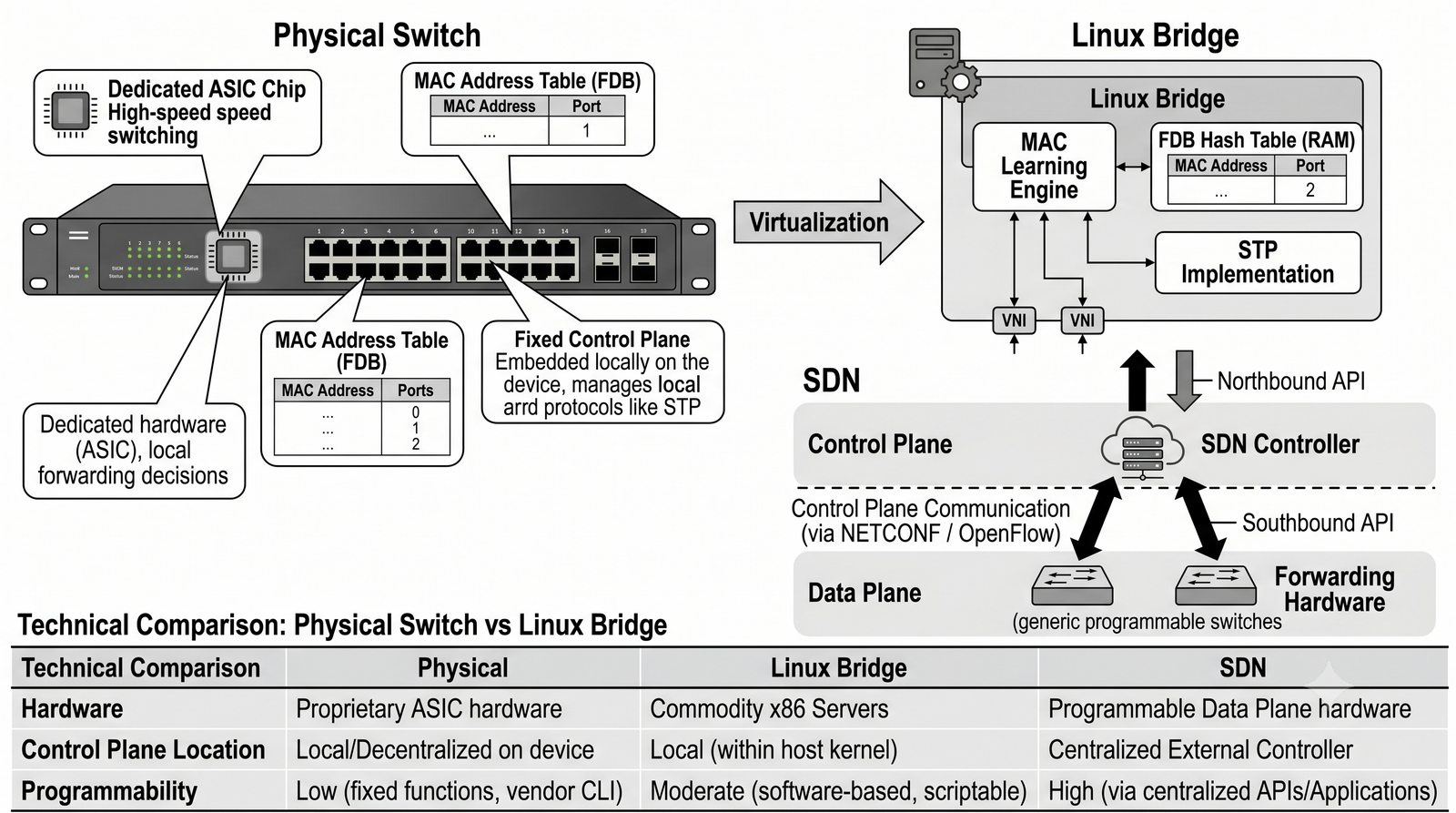
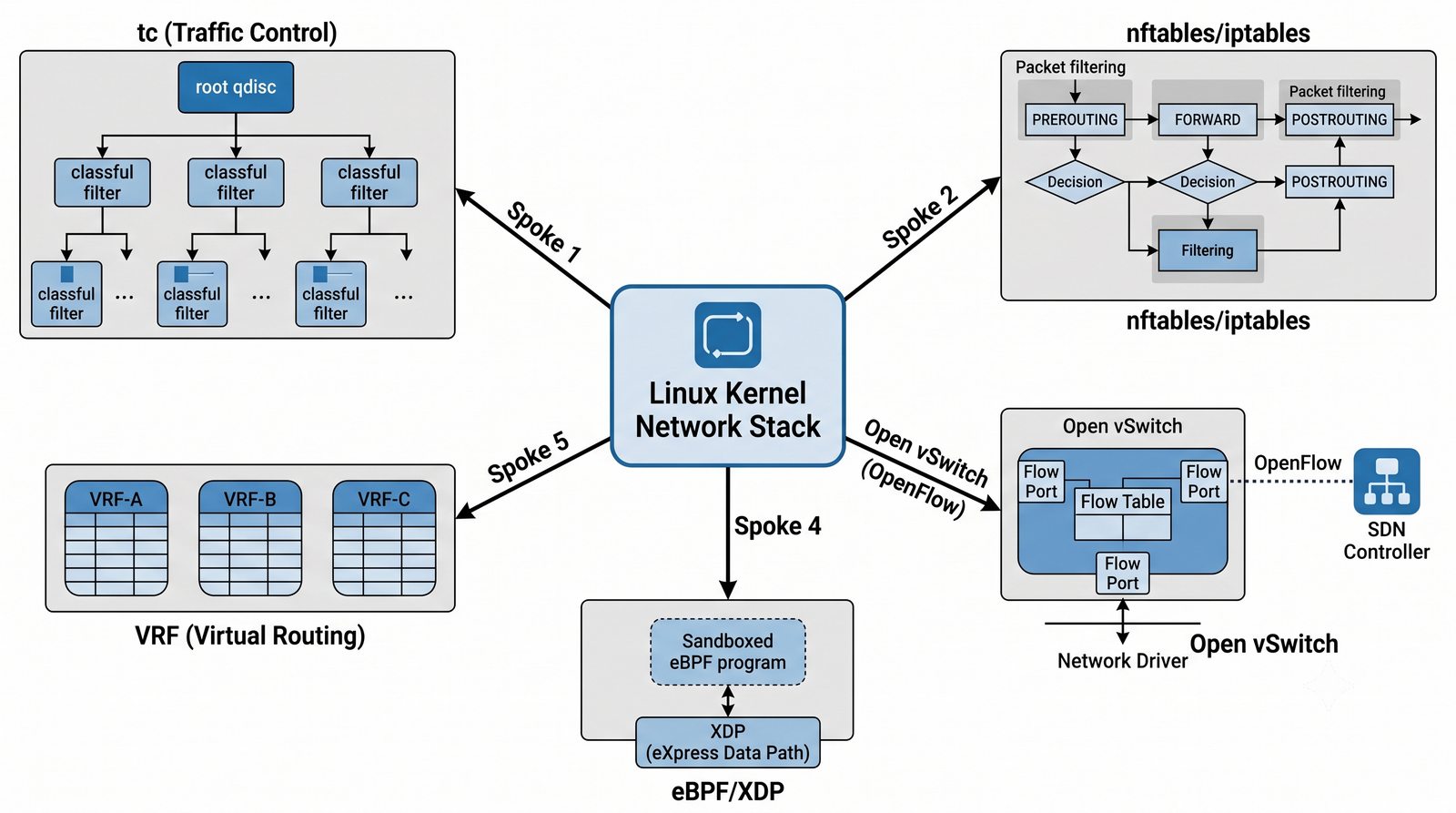
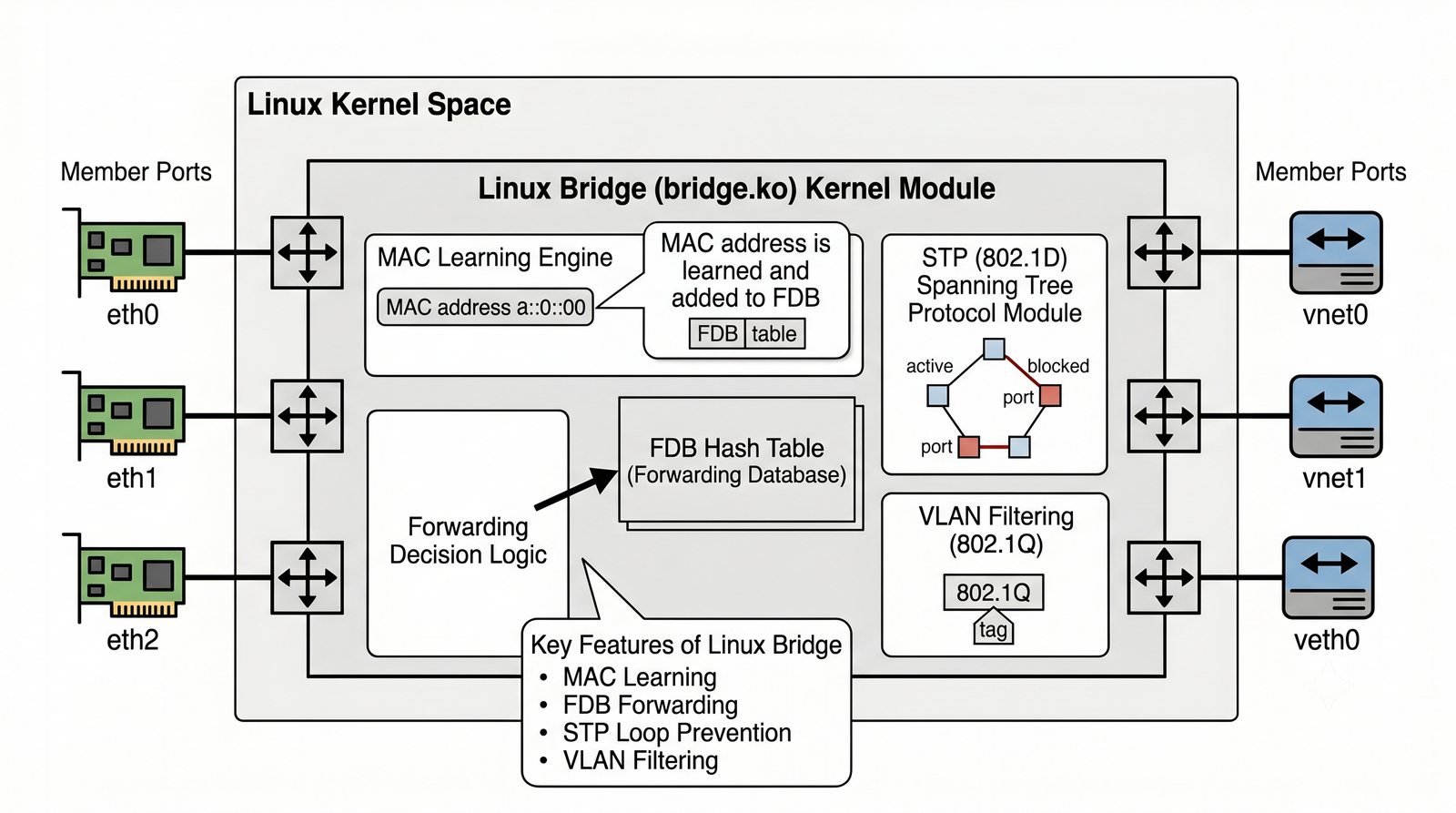
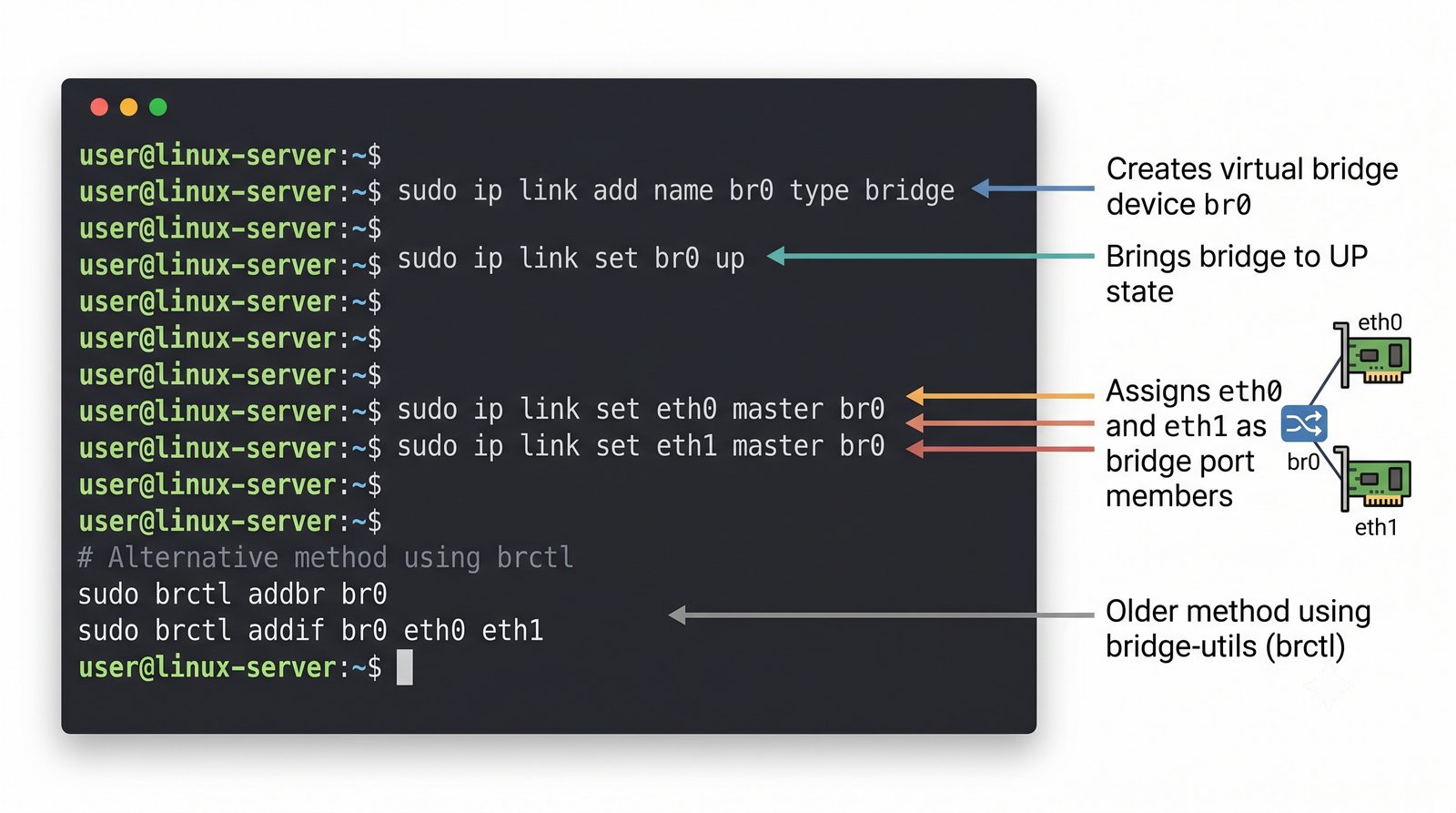
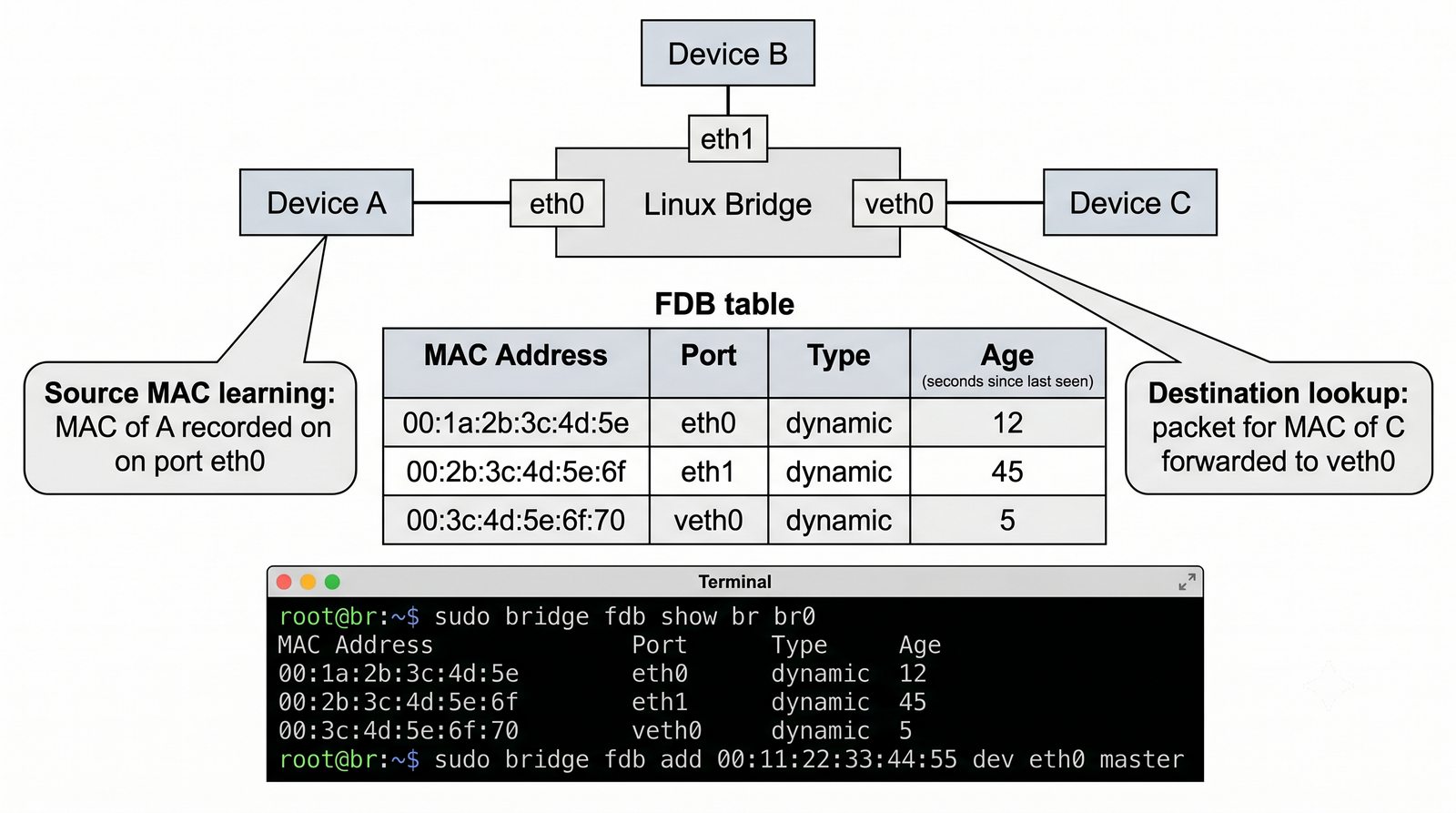
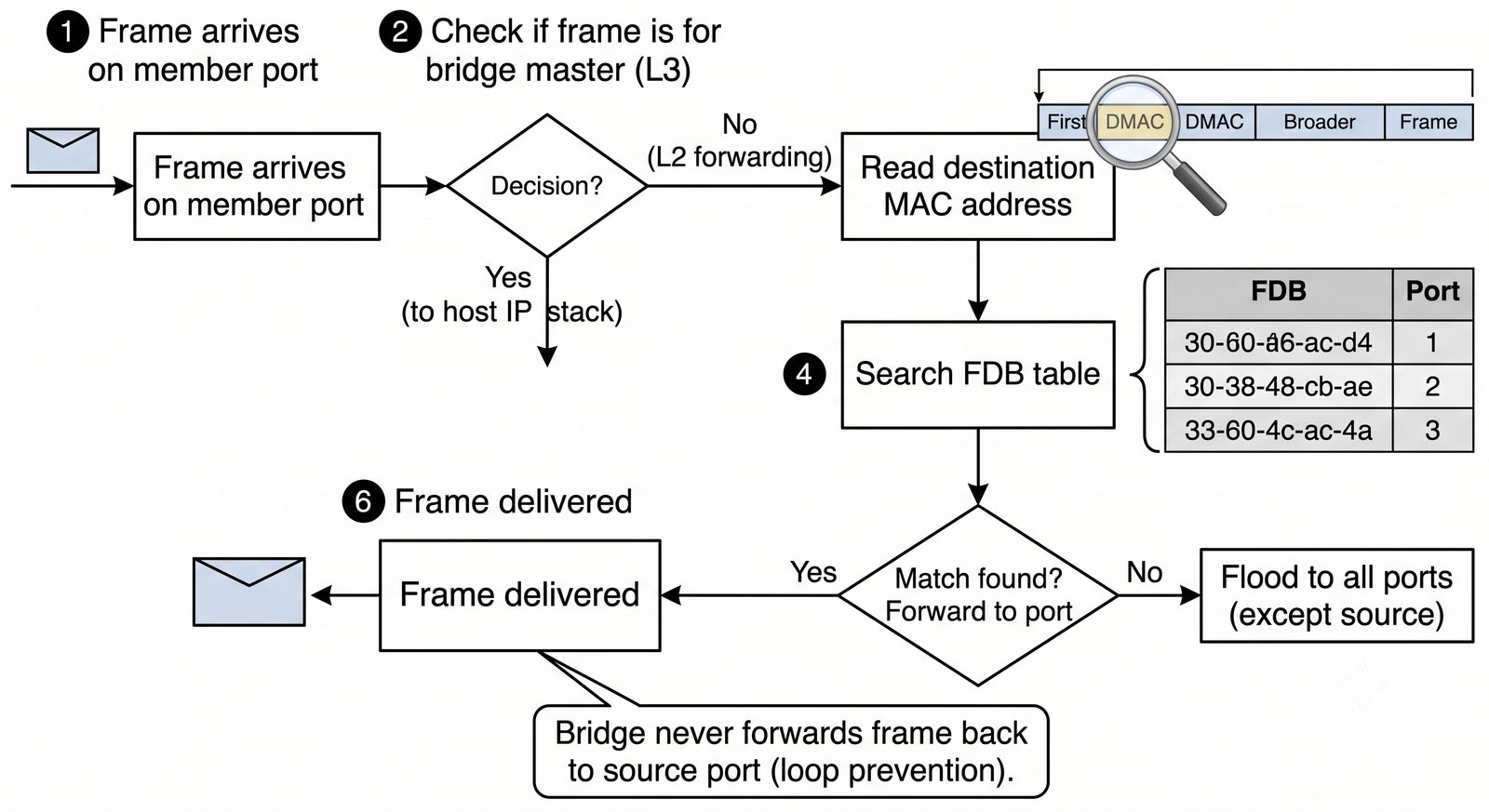
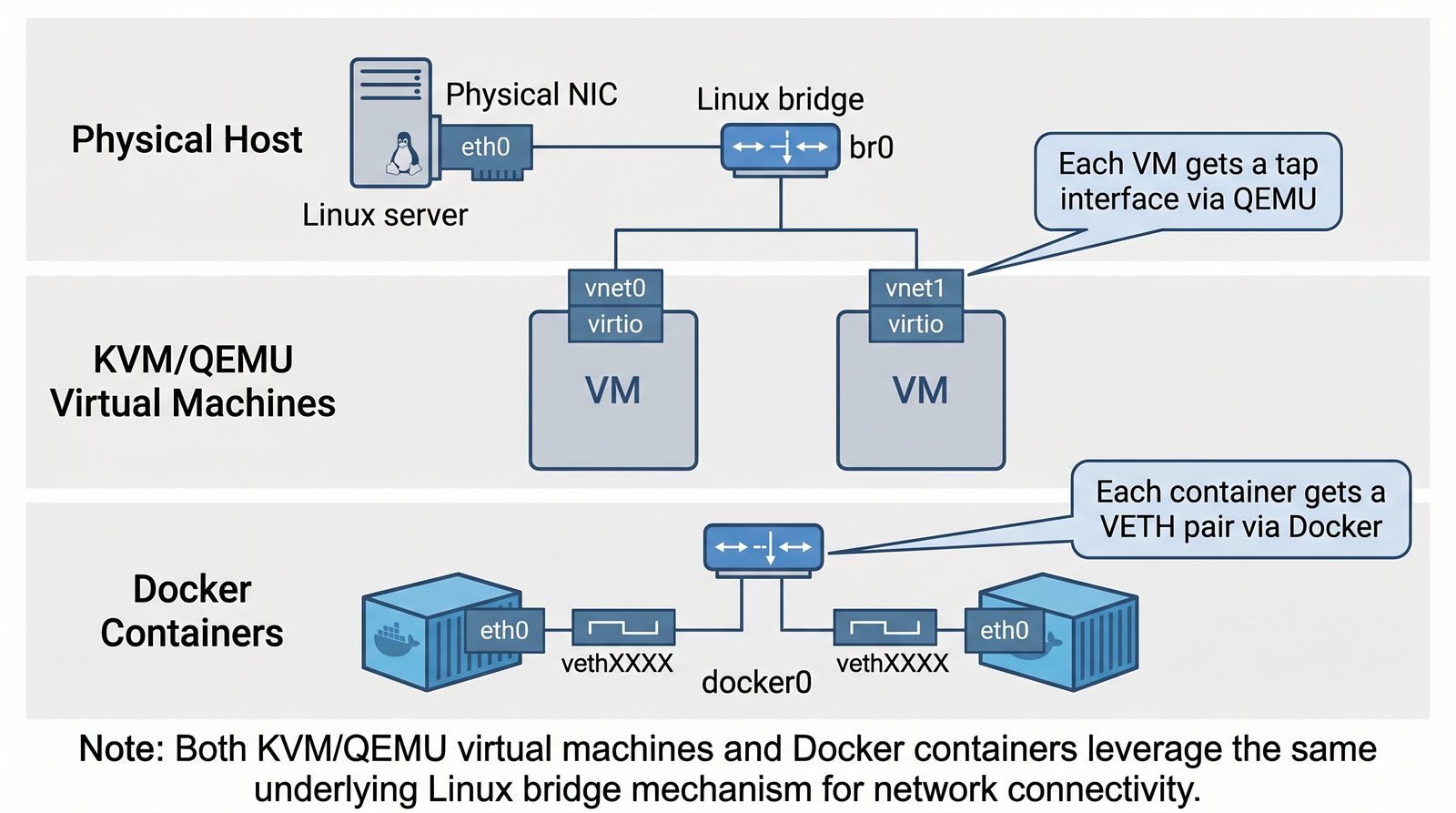
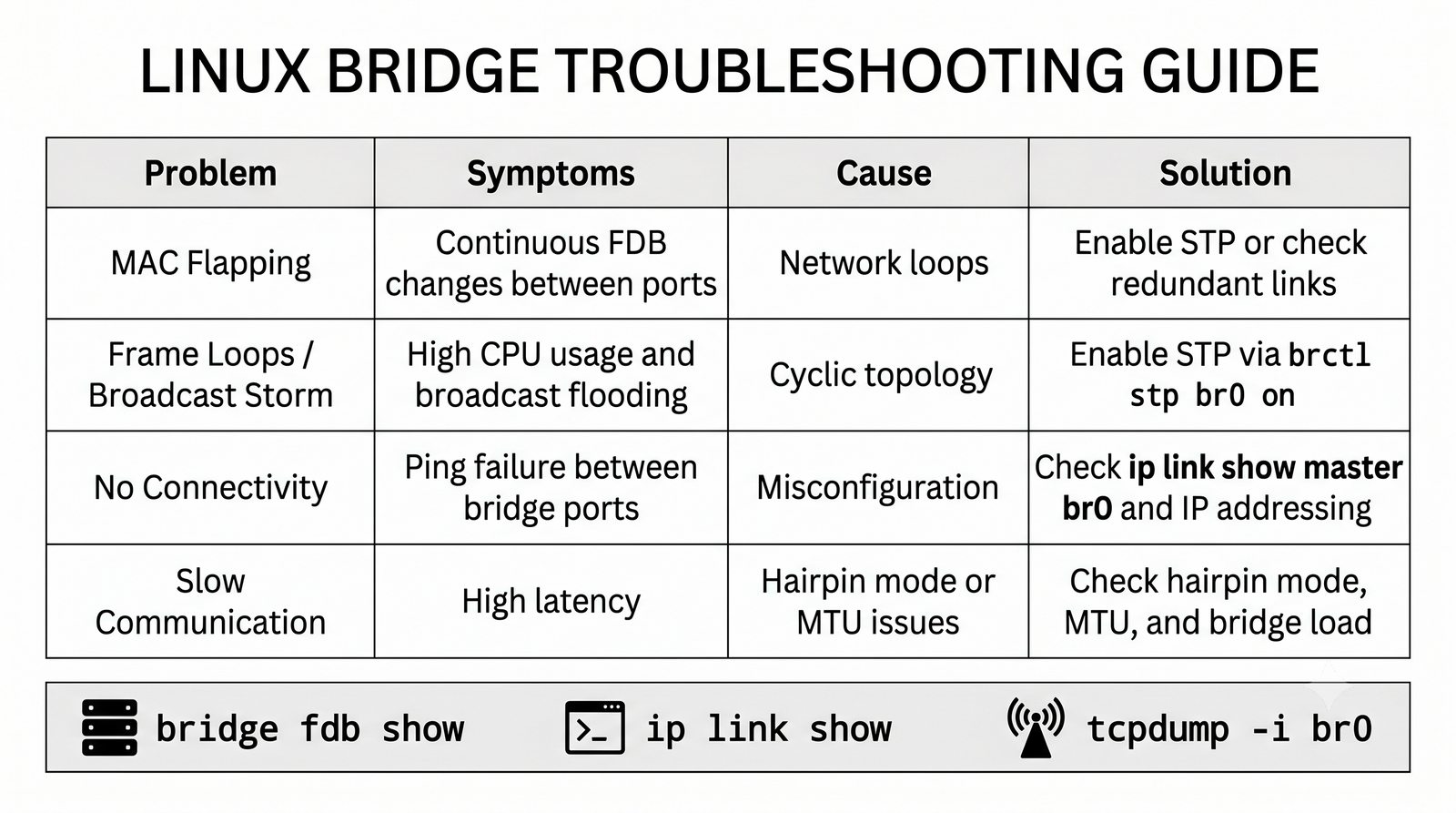
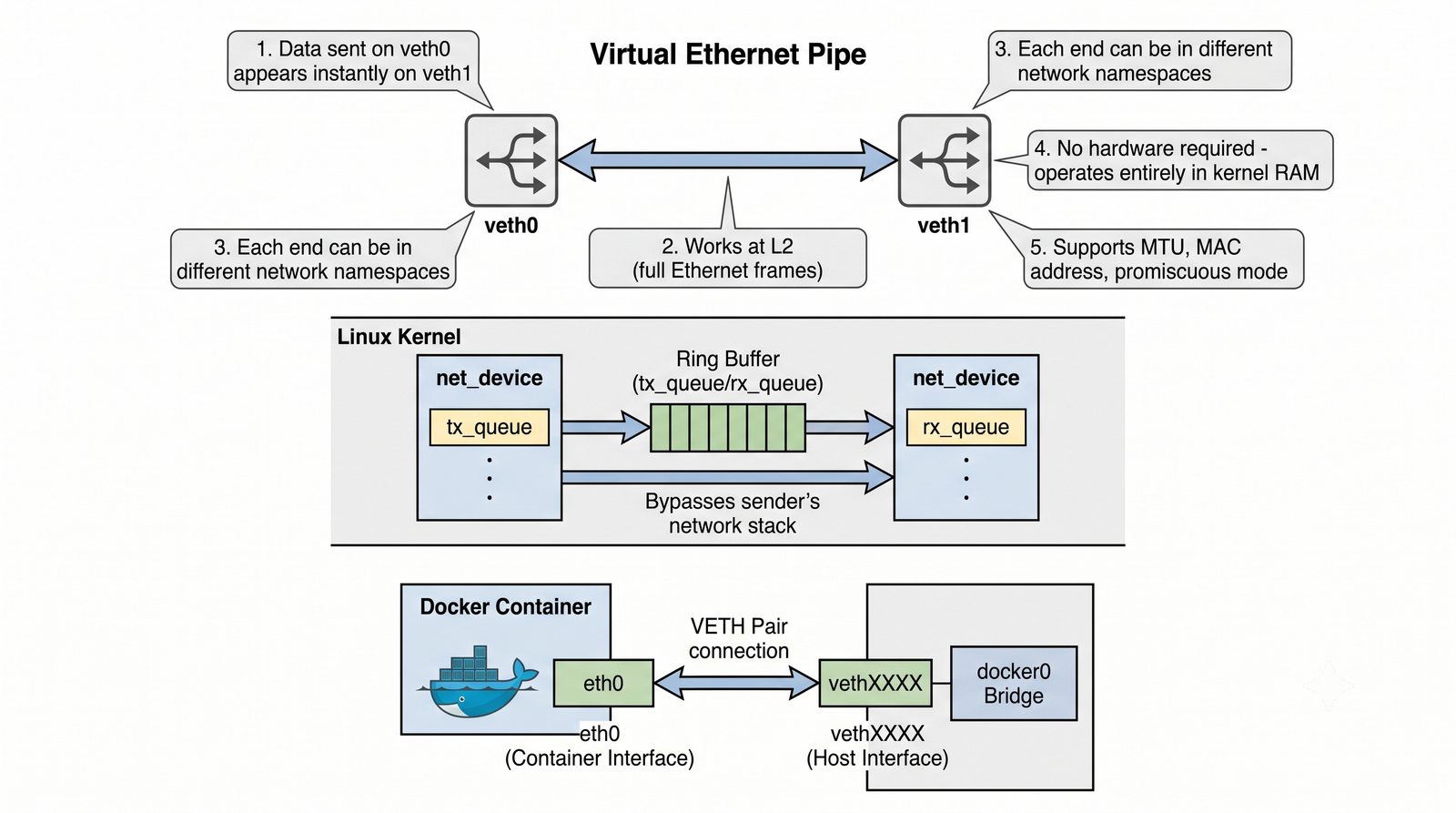
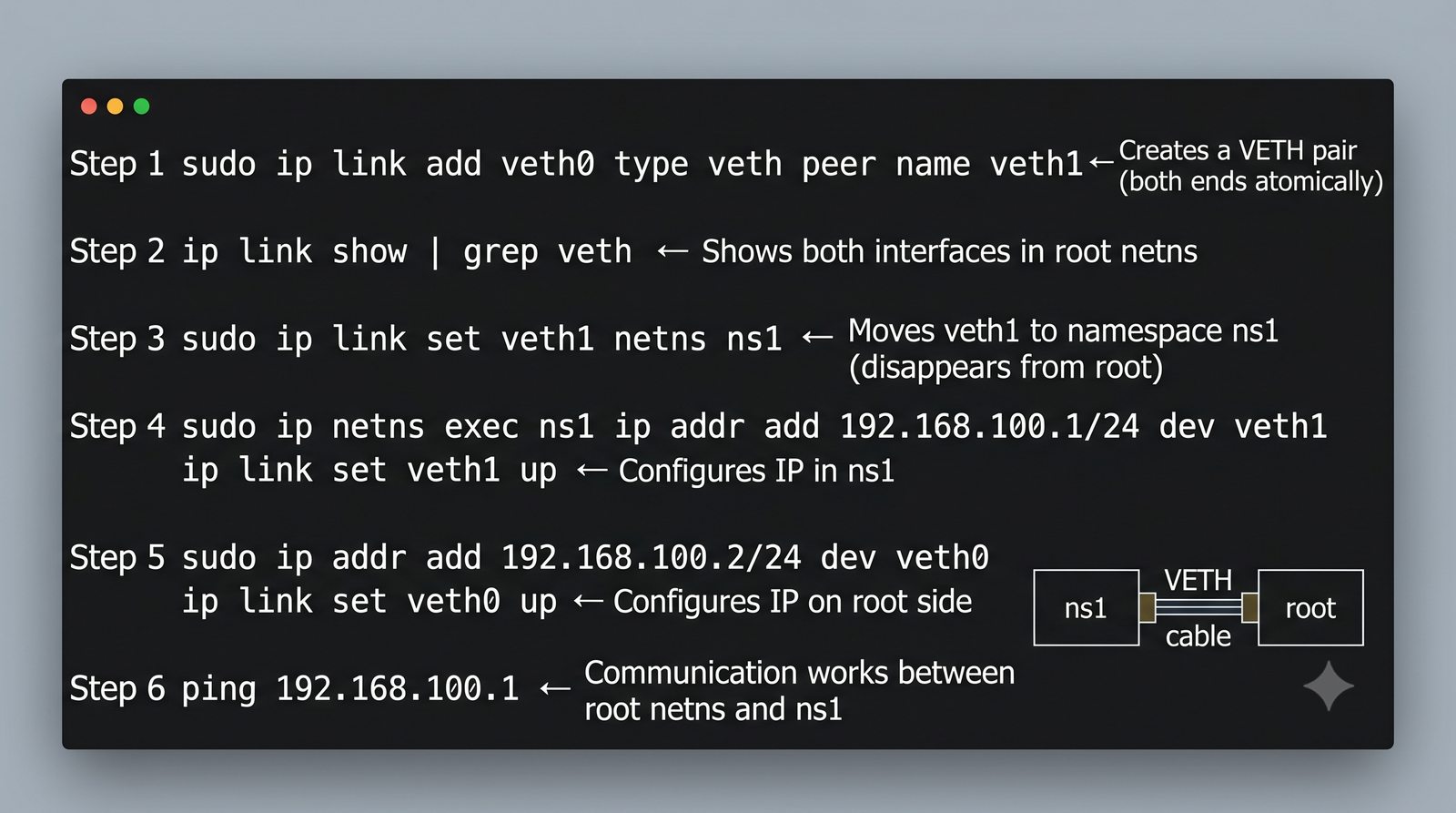
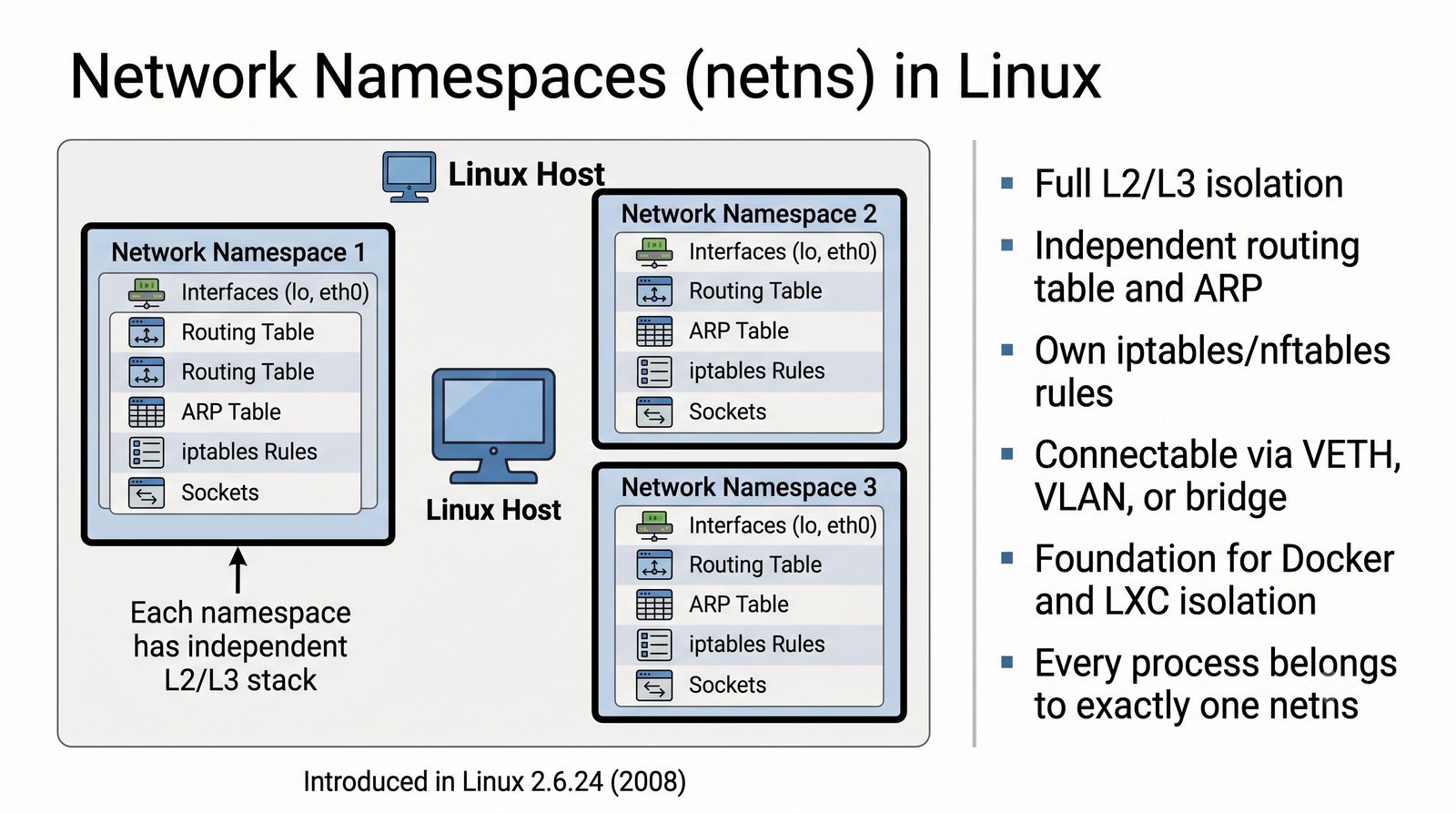
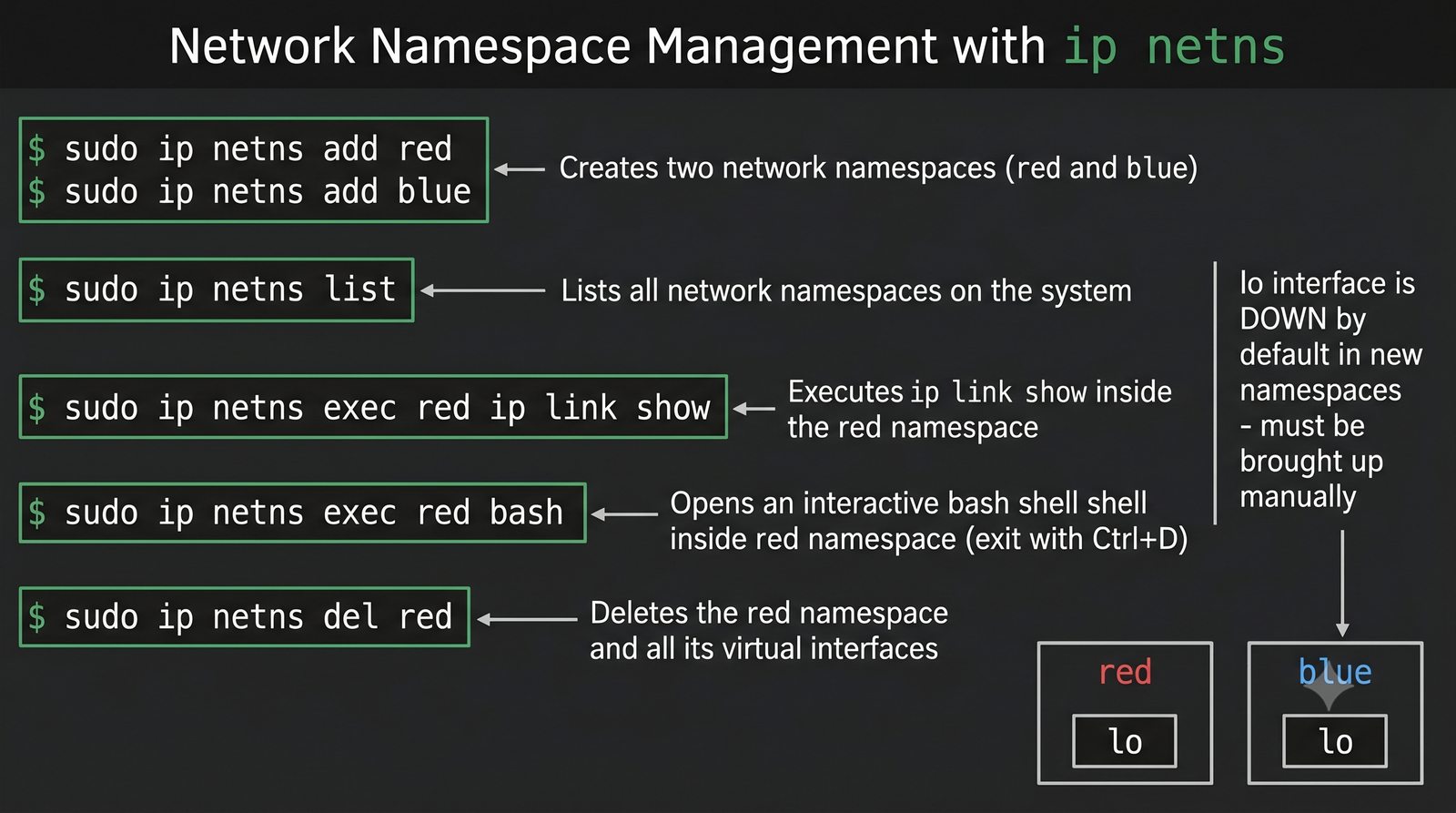
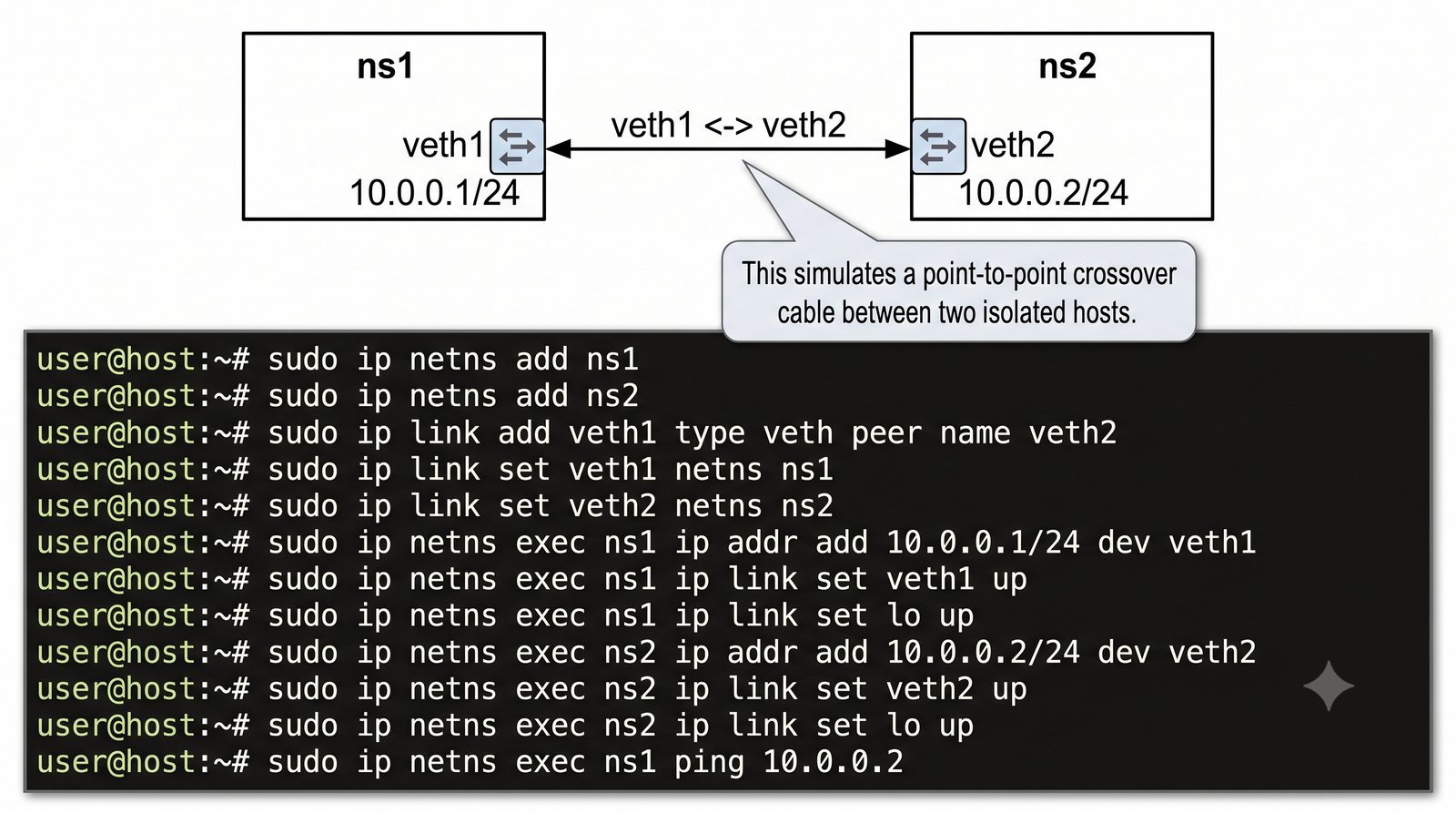
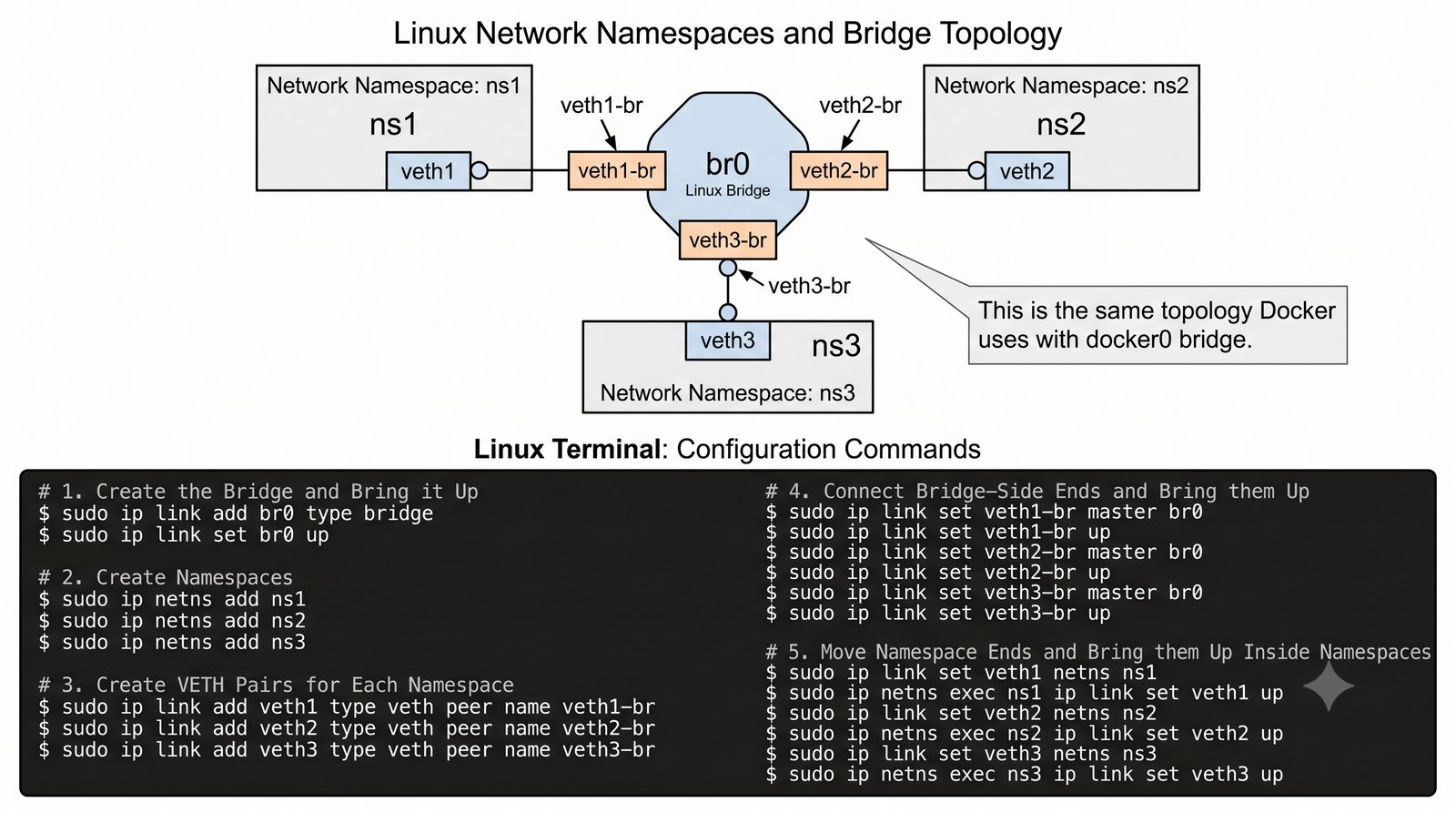
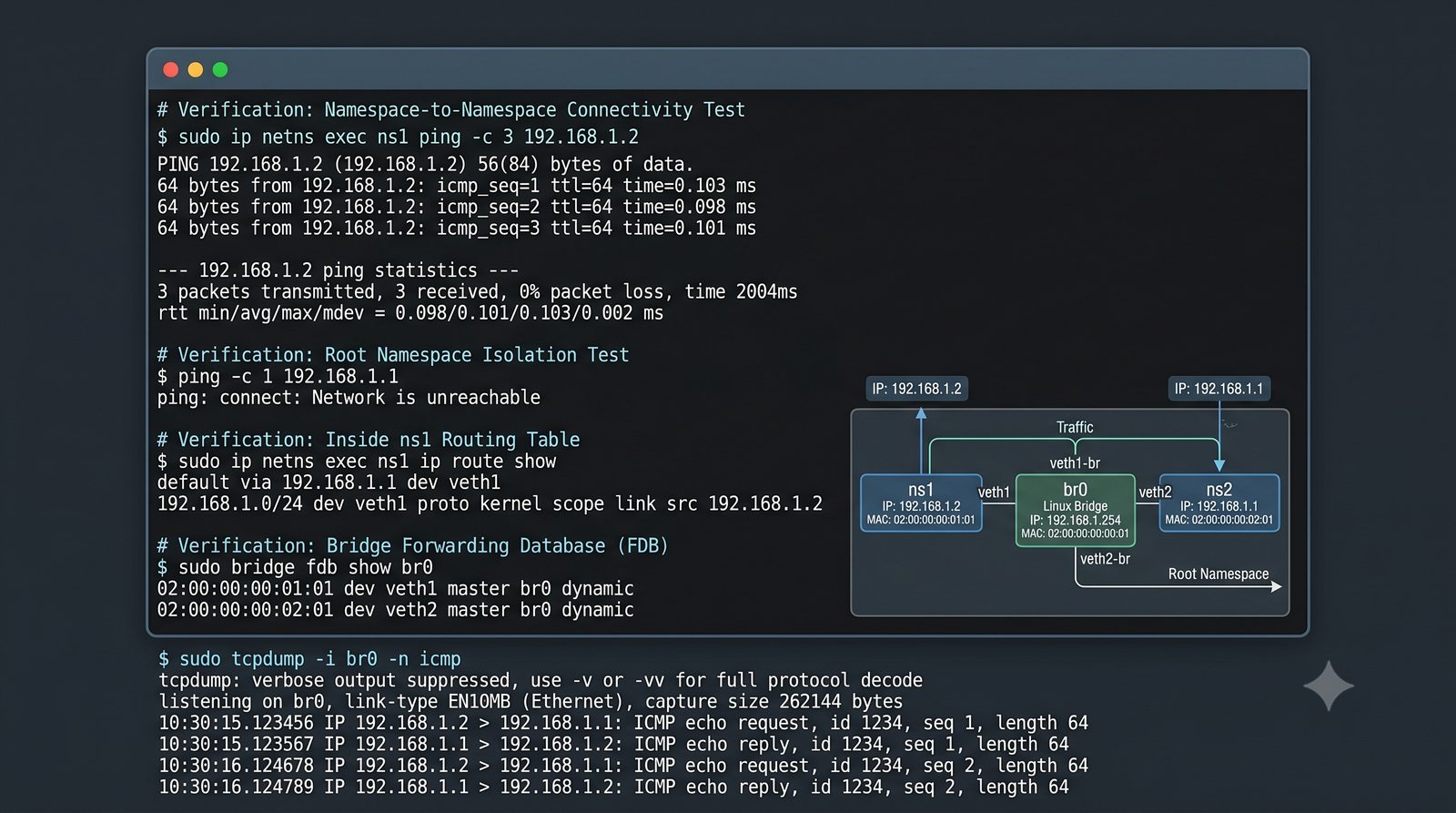
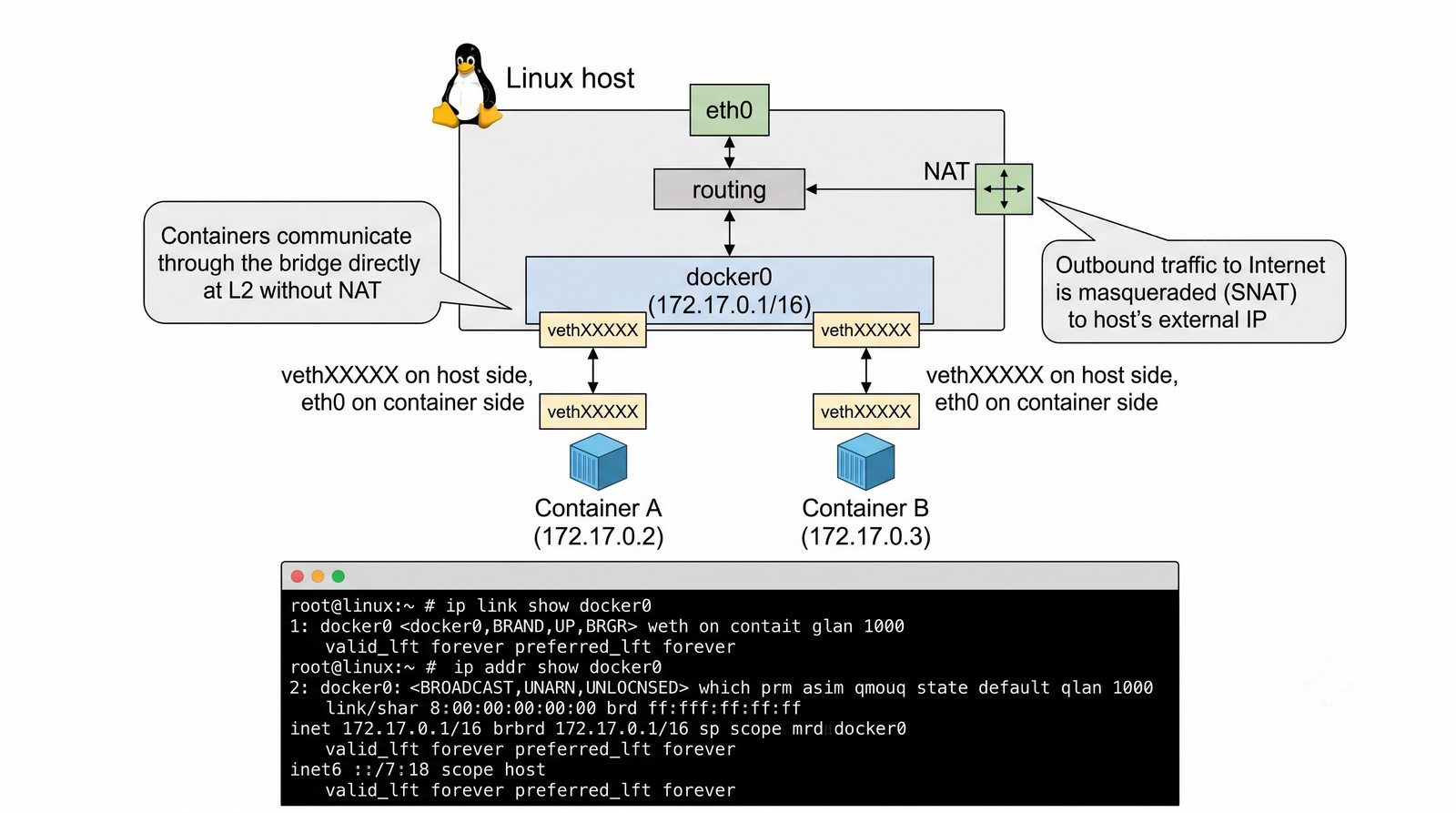
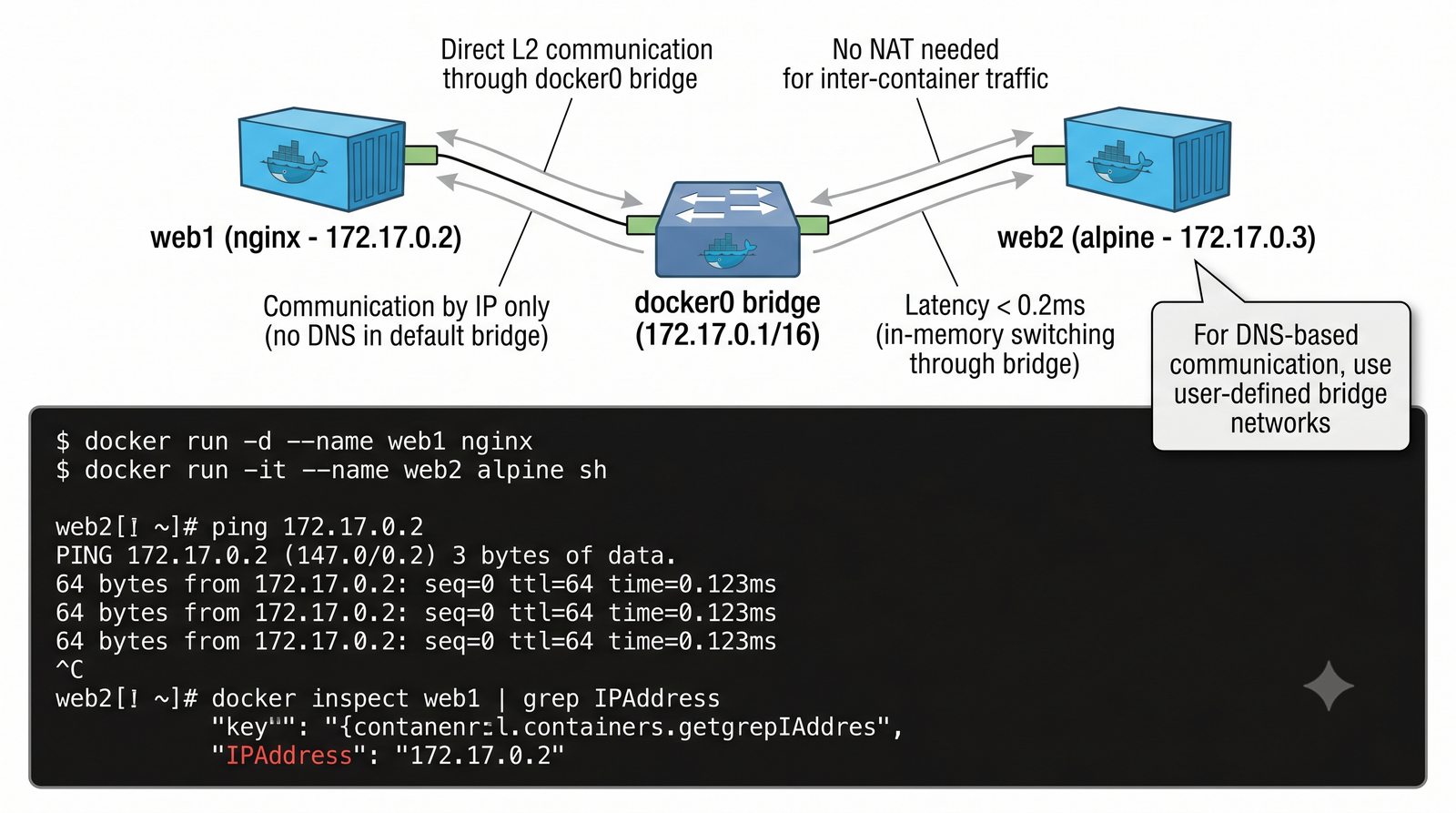
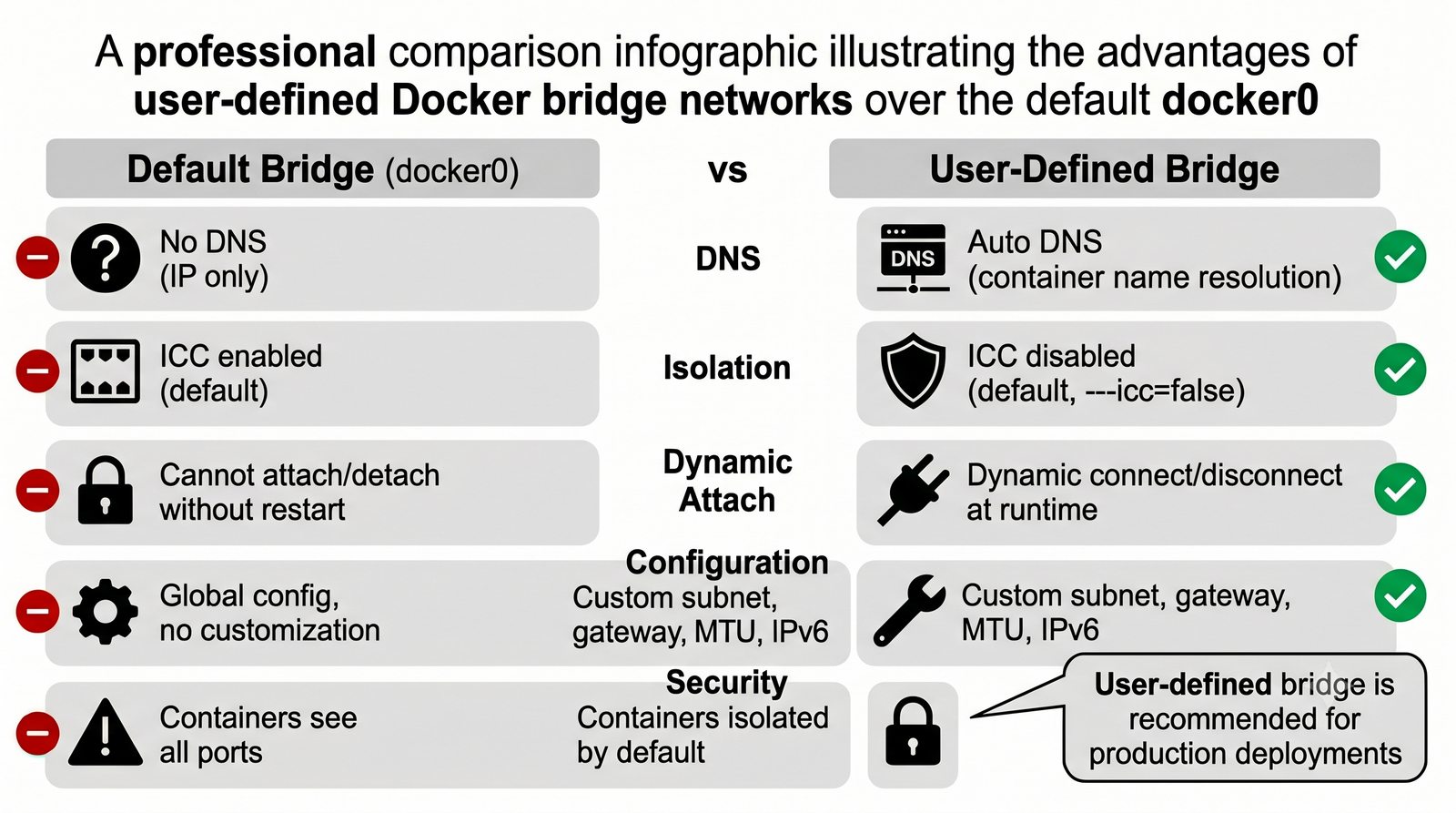
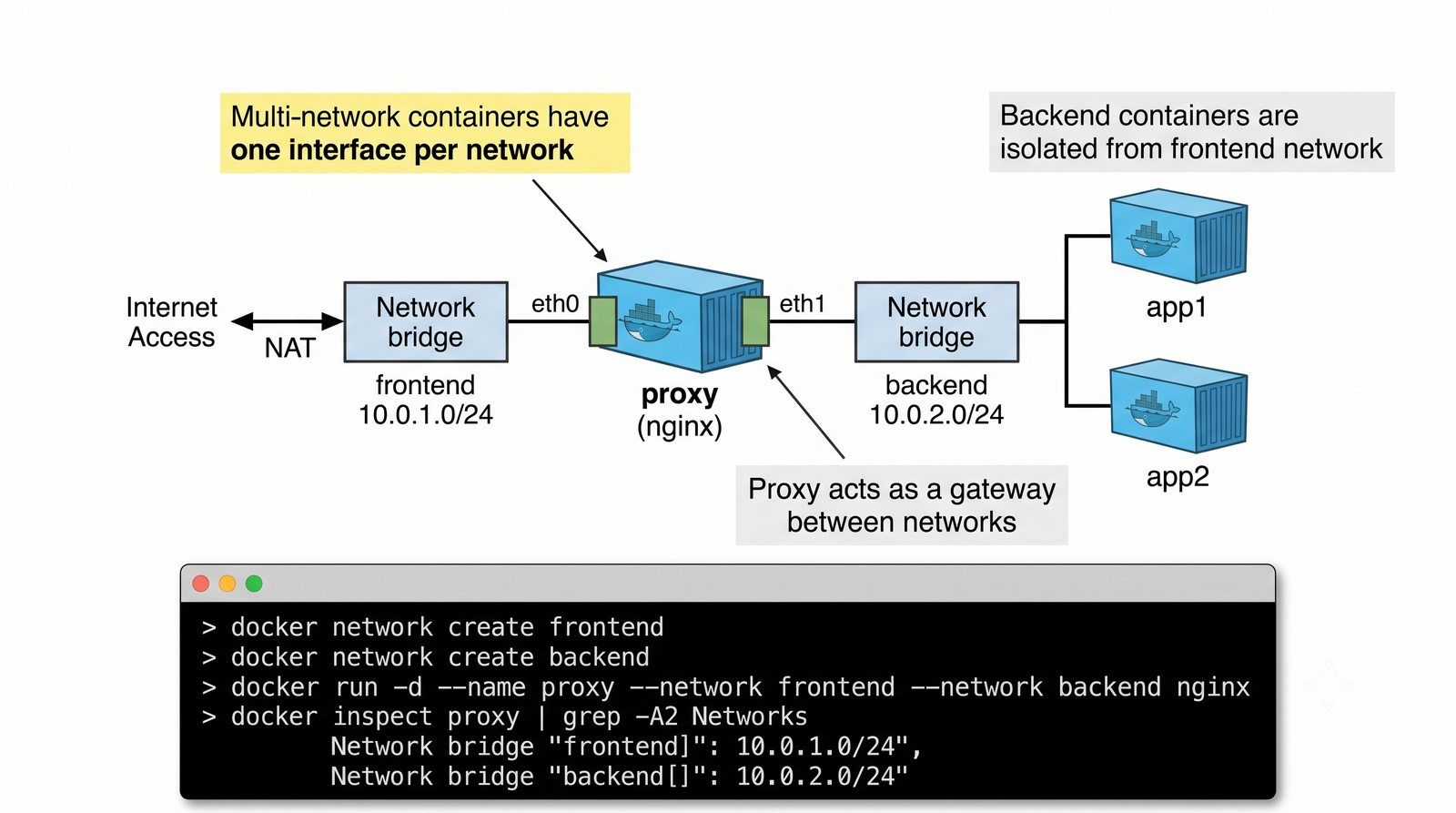
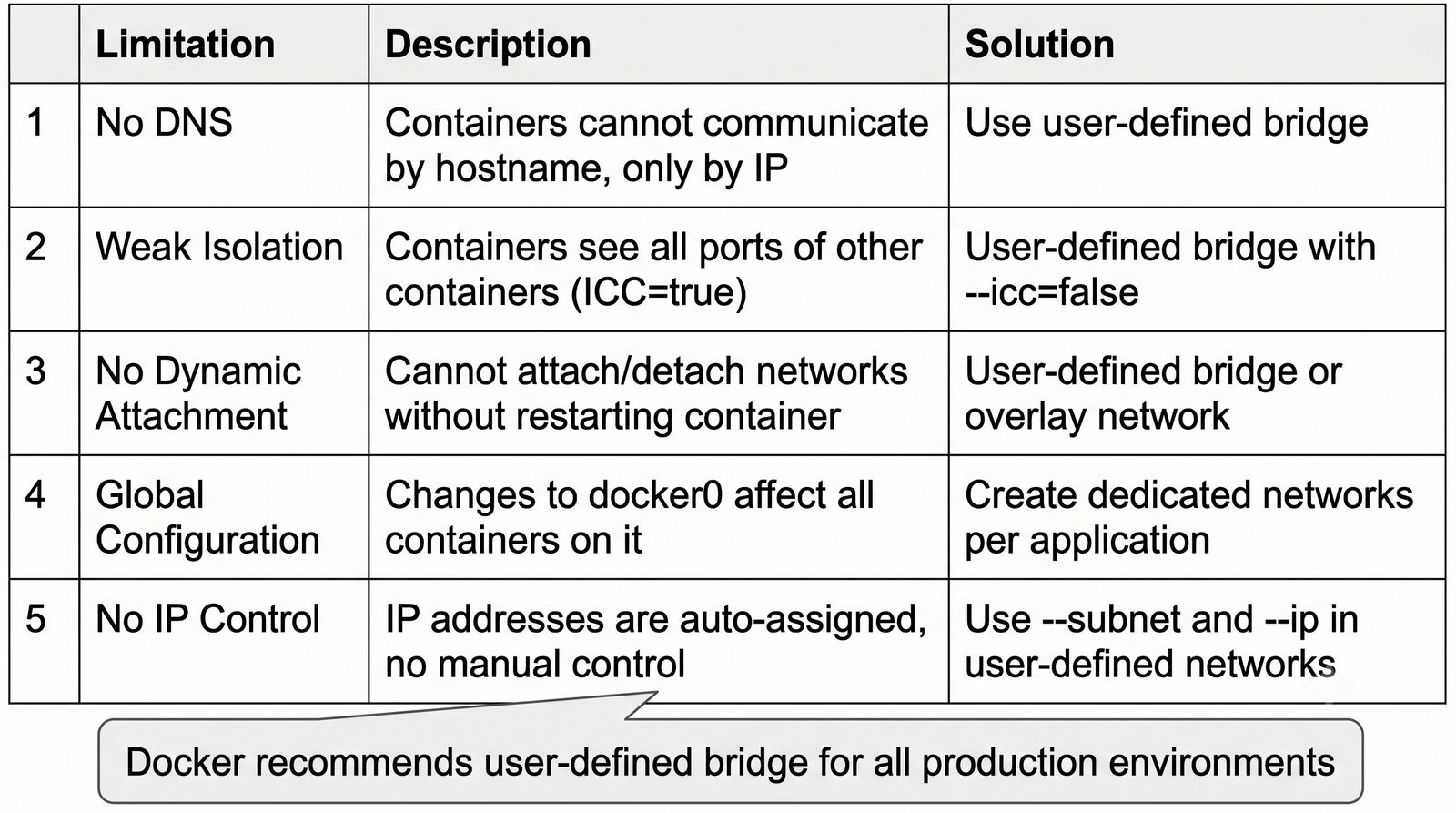
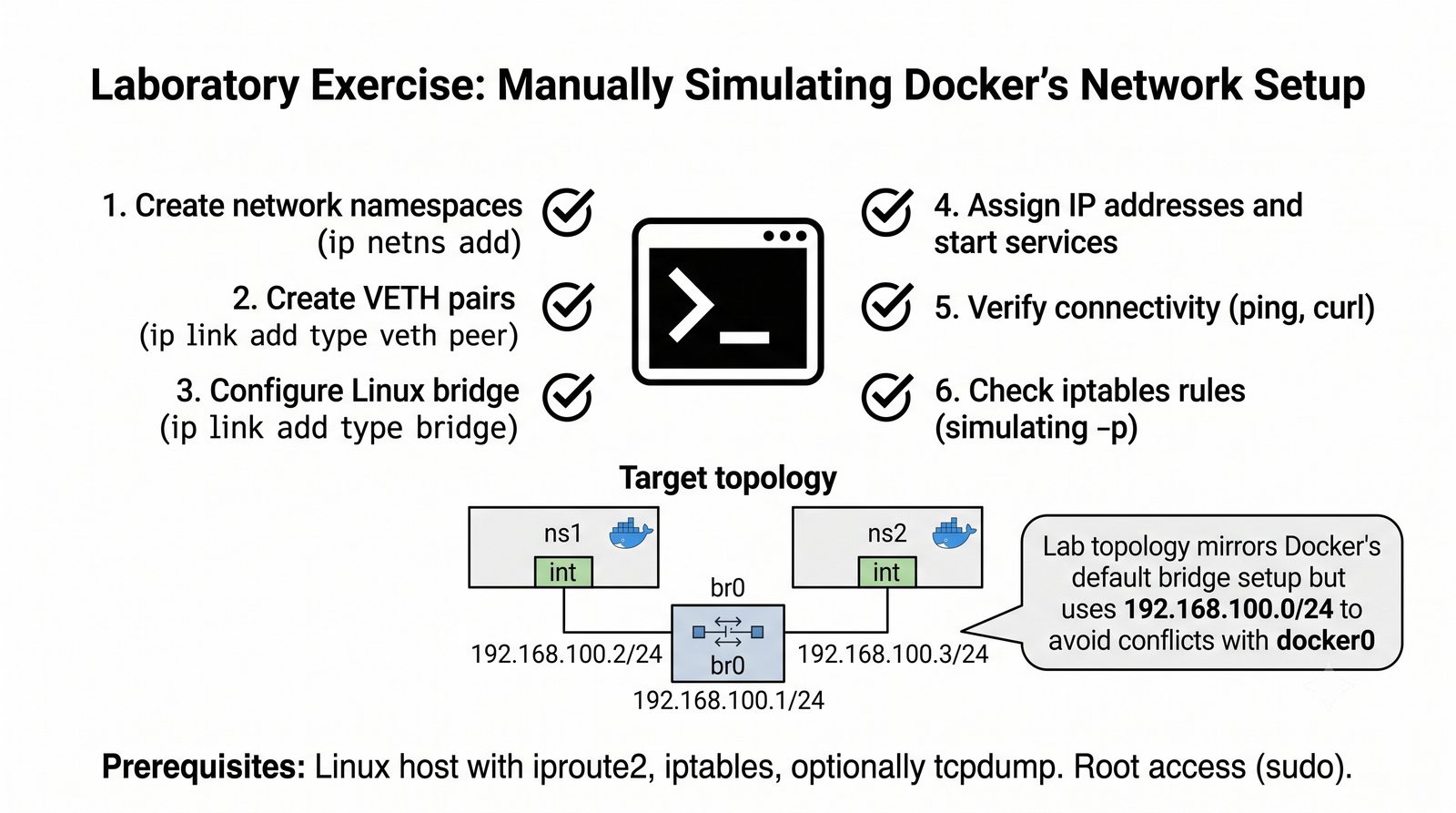
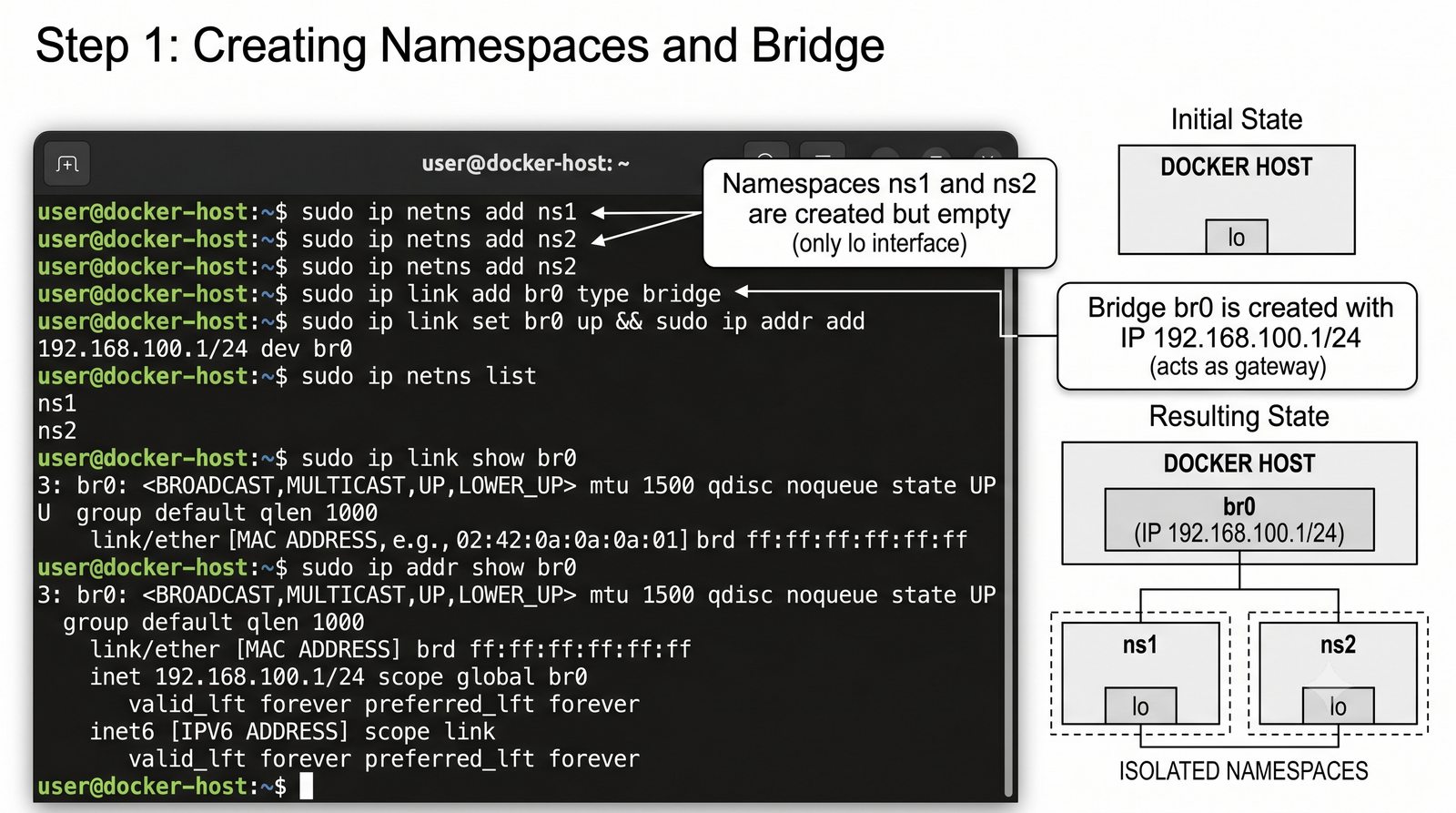
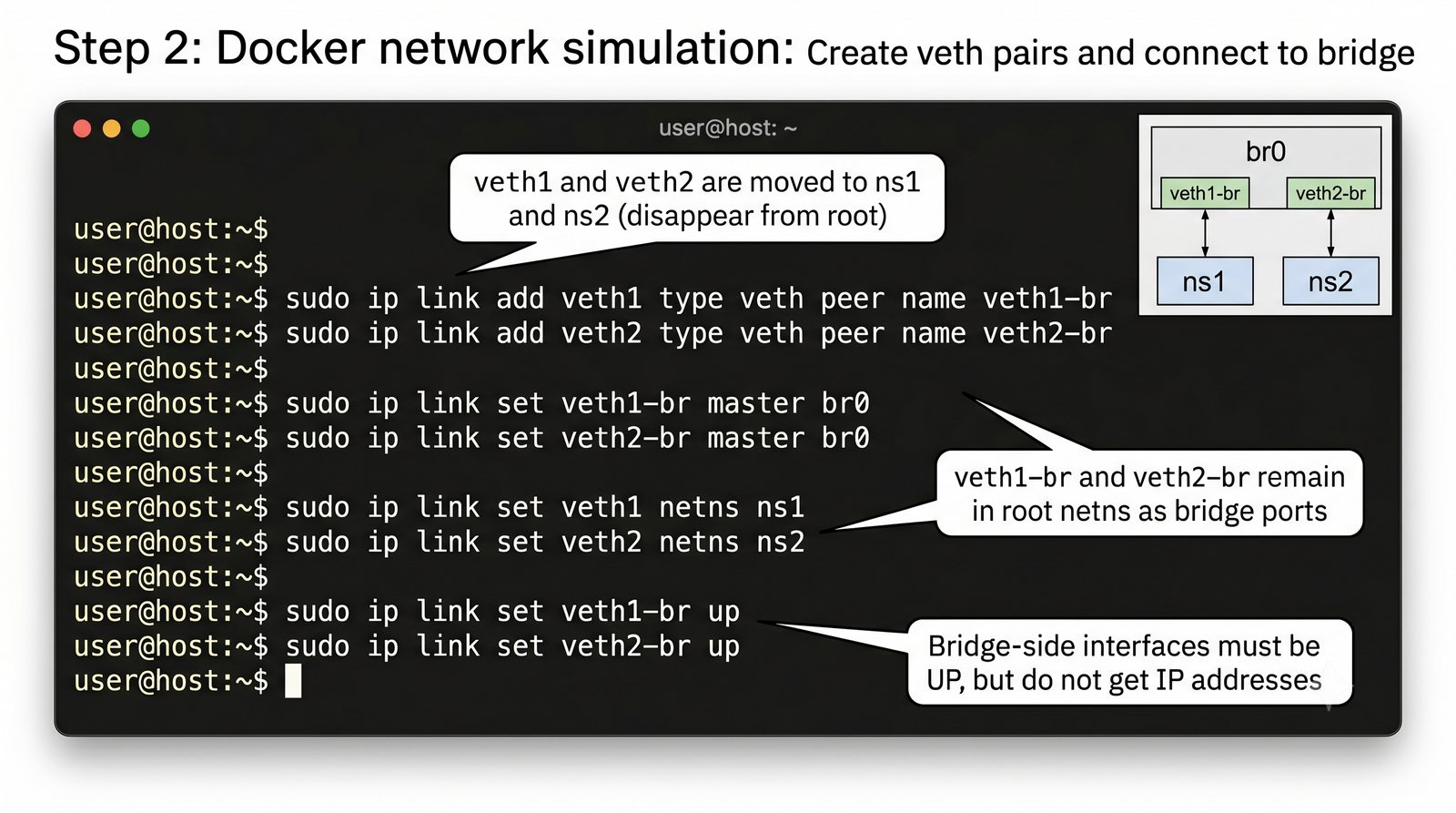
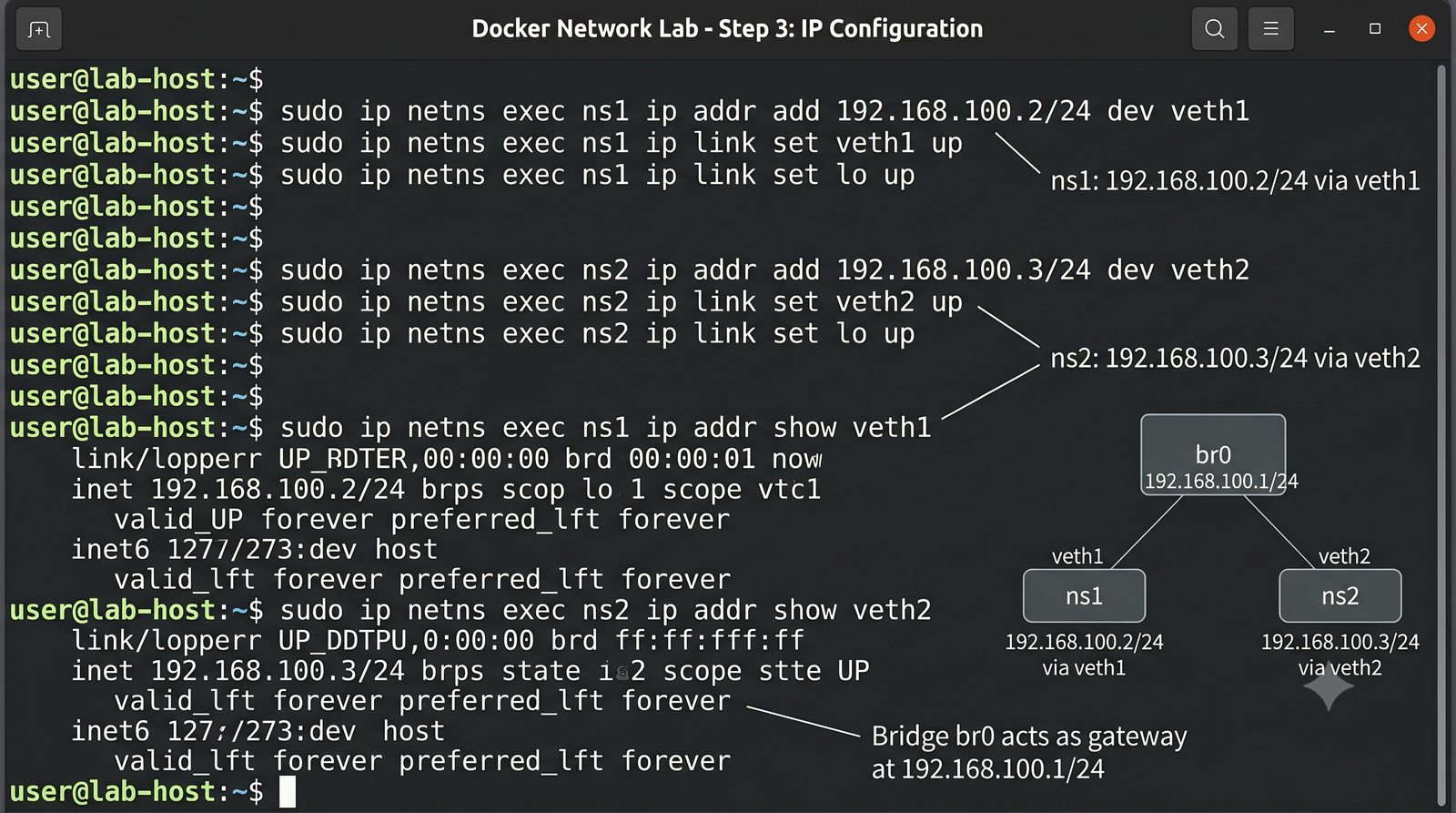
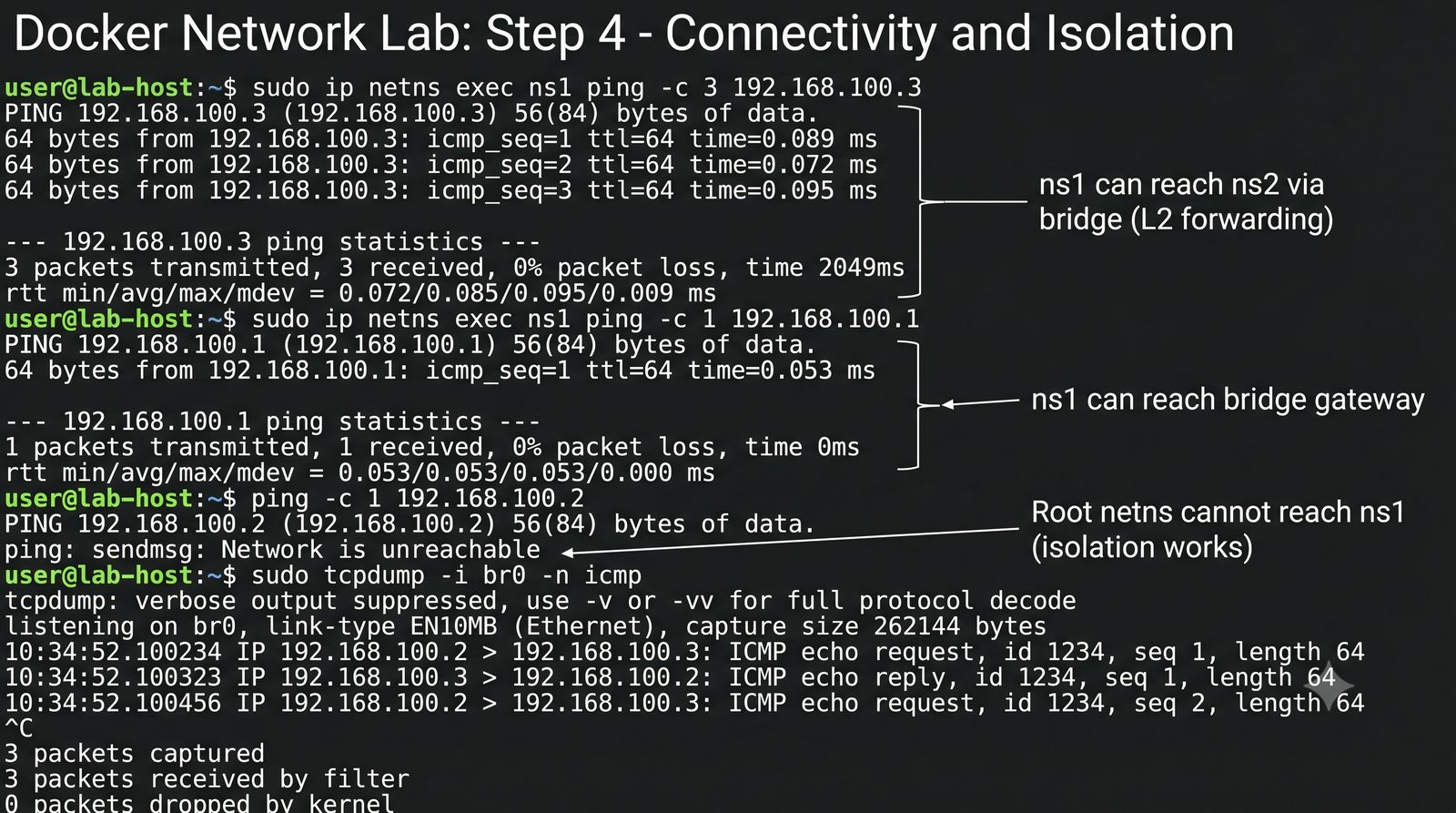
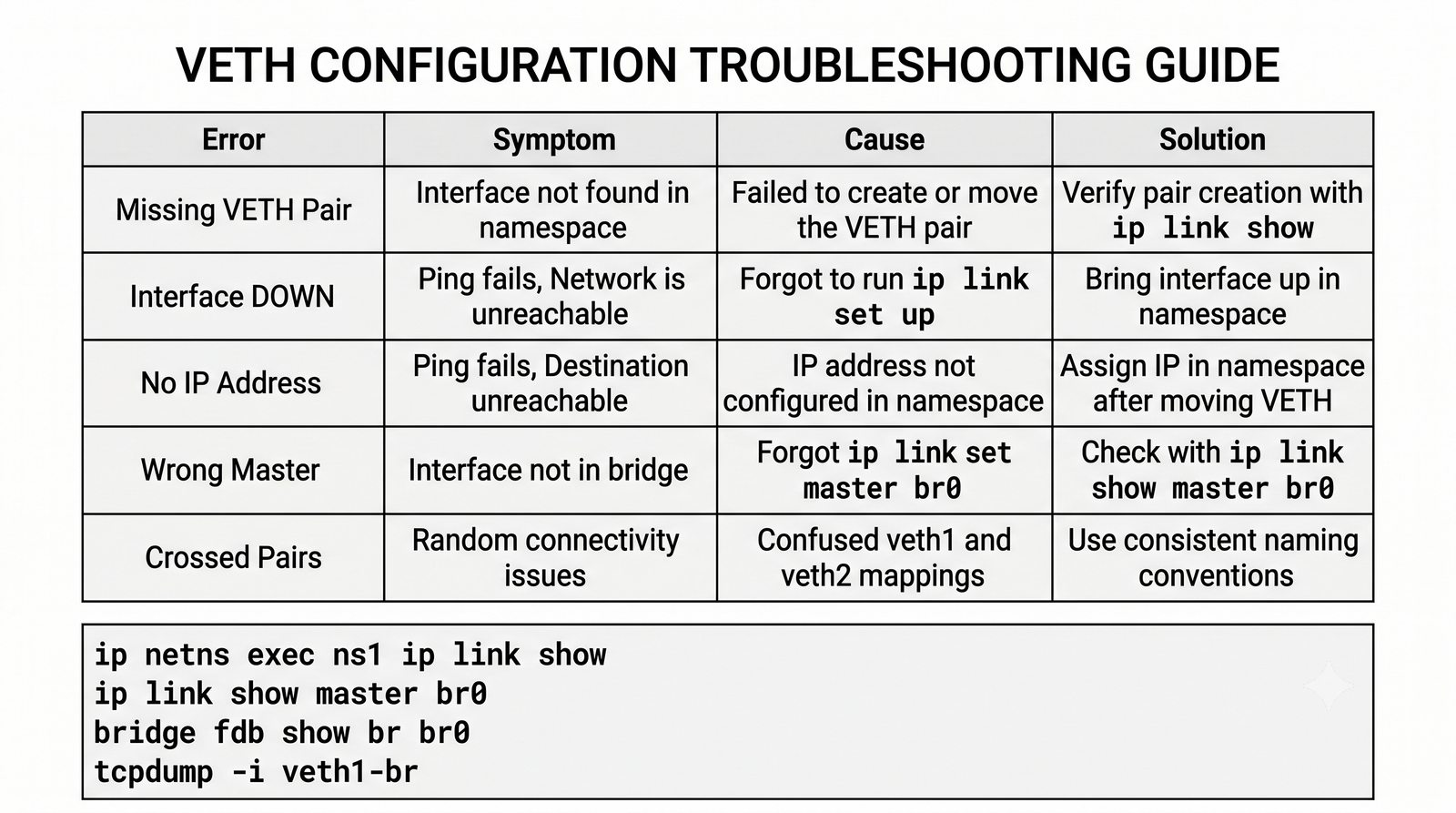
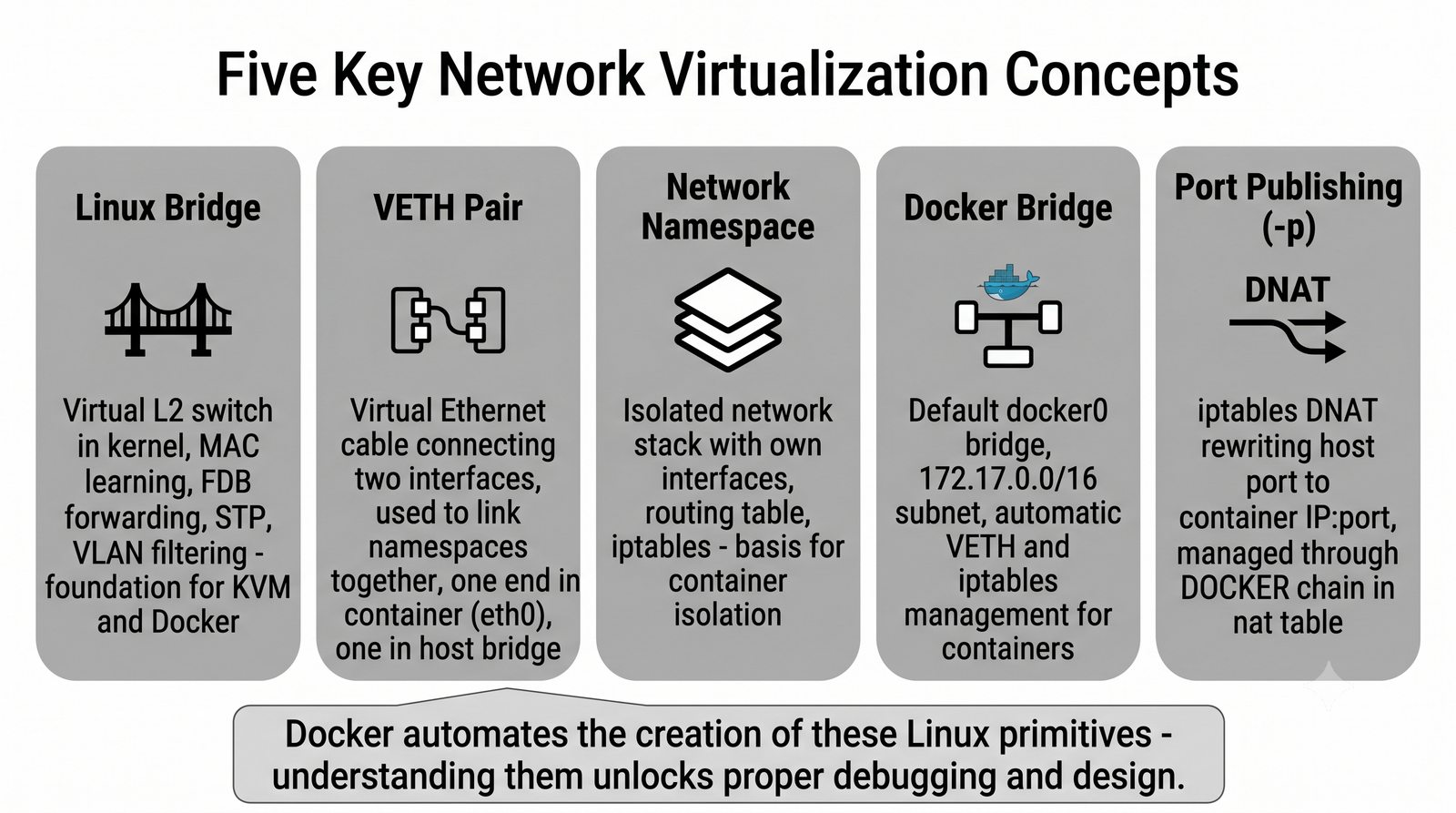
Wirtualizacja sieci stanowi fundament nowoczesnych centrów danych, umożliwiając izolację ruchu, elastyczne zarządzanie przepustowością oraz separację dzierżawców w środowiskach wielodostępnych. W ramach wykładu przeanalizujemy działanie mostka L2 w przestrzeni jądra oraz sposoby łączenia odizolowanych przestrzeni nazw sieciowych.
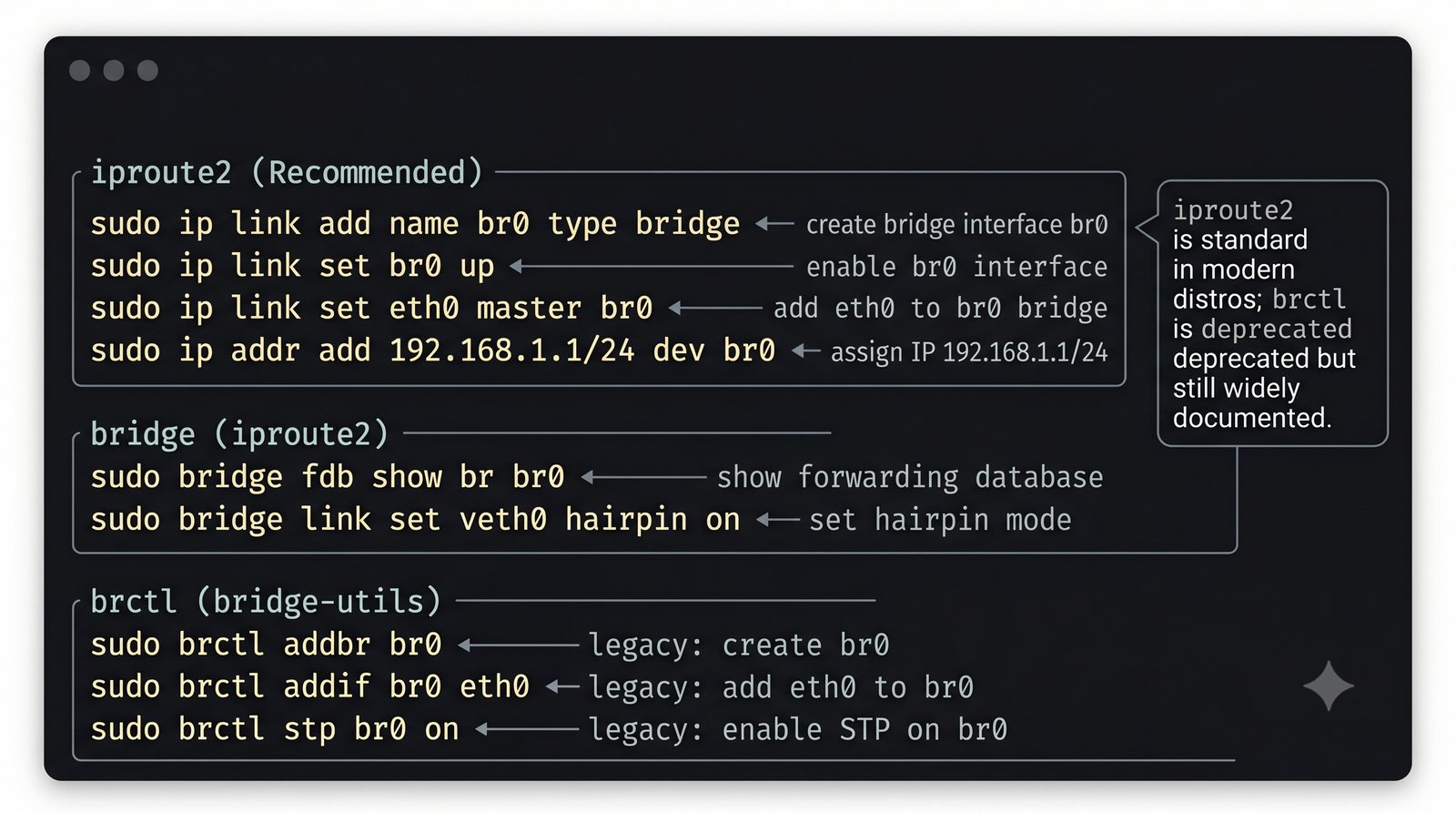
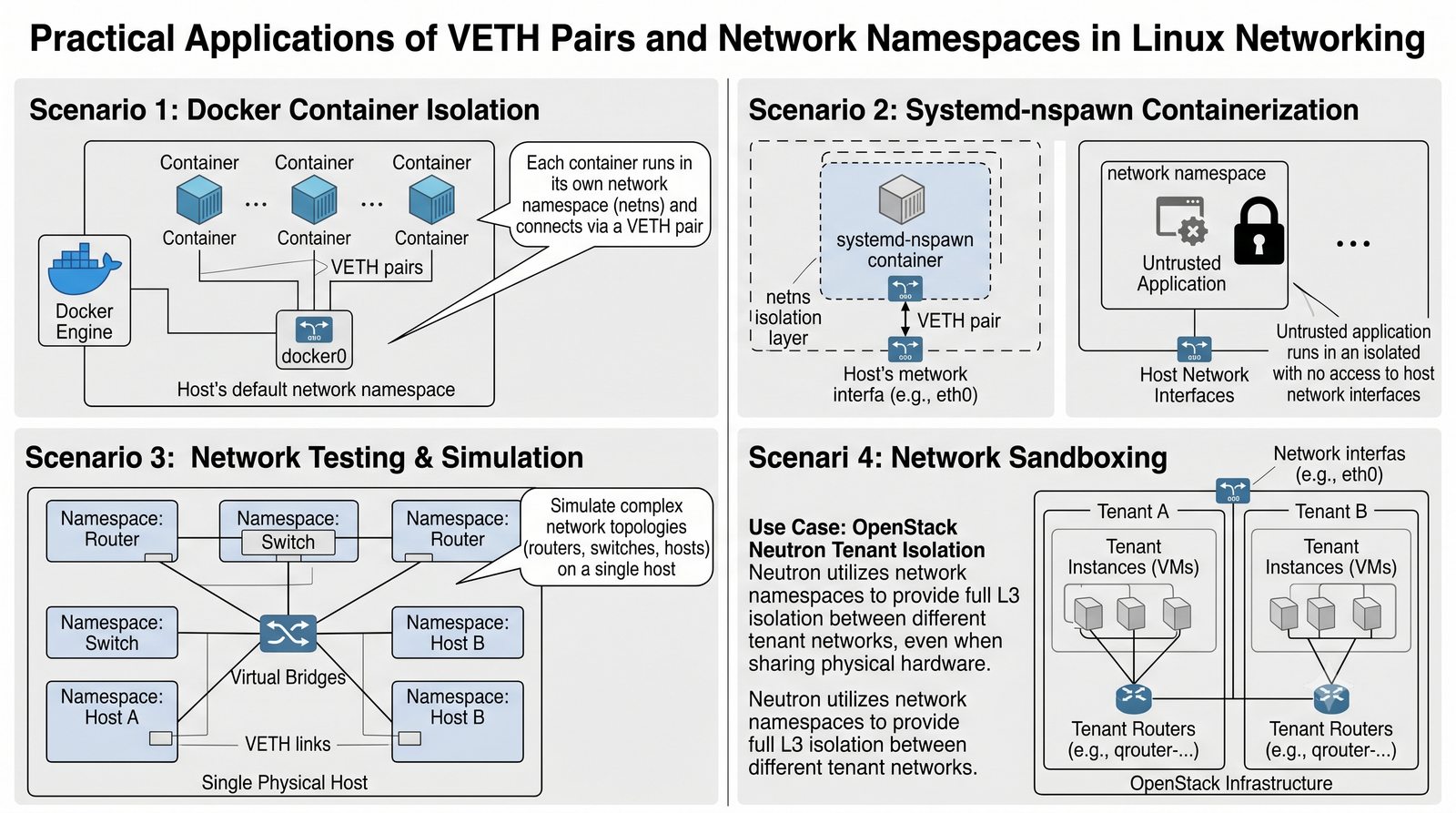
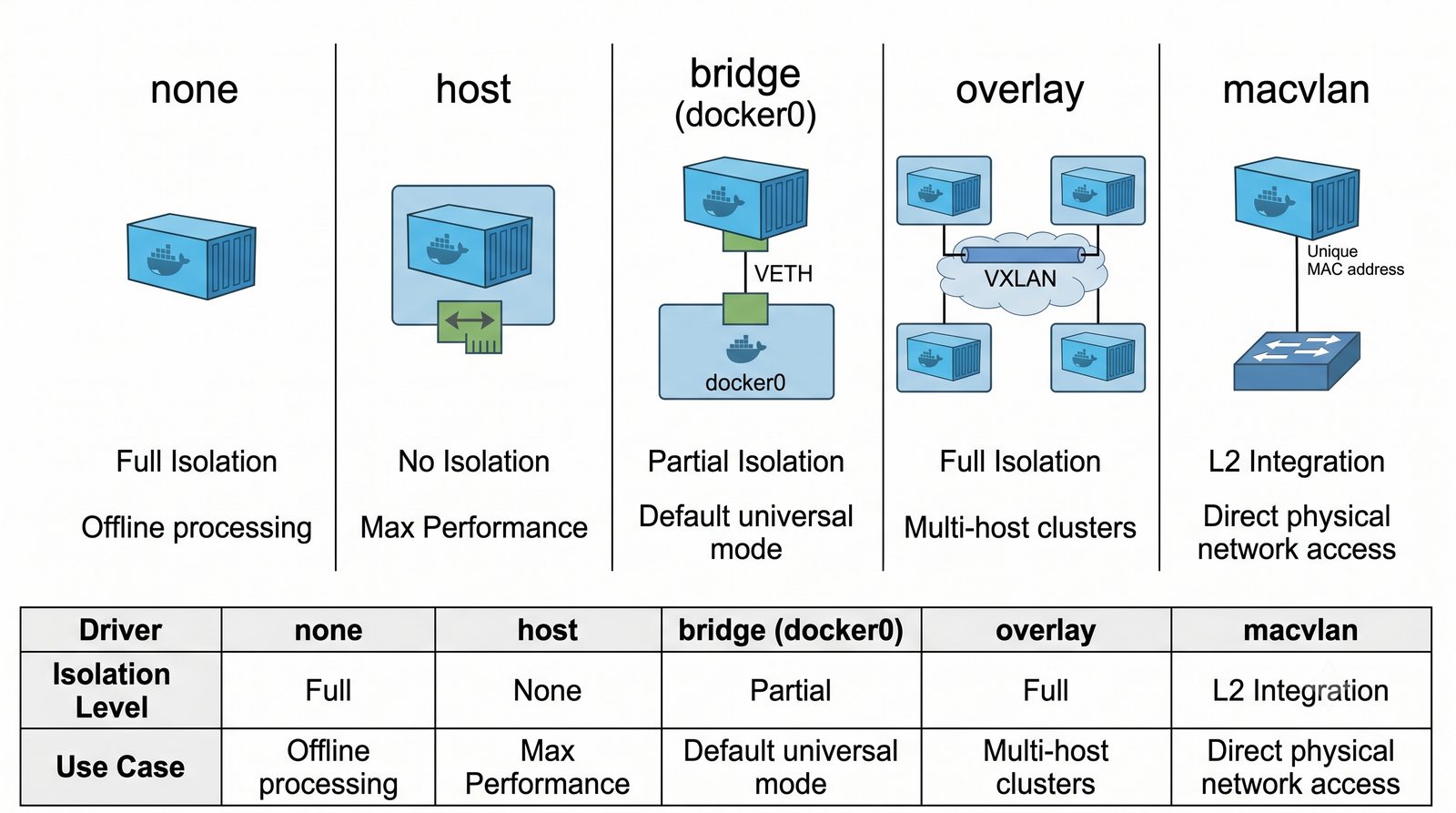
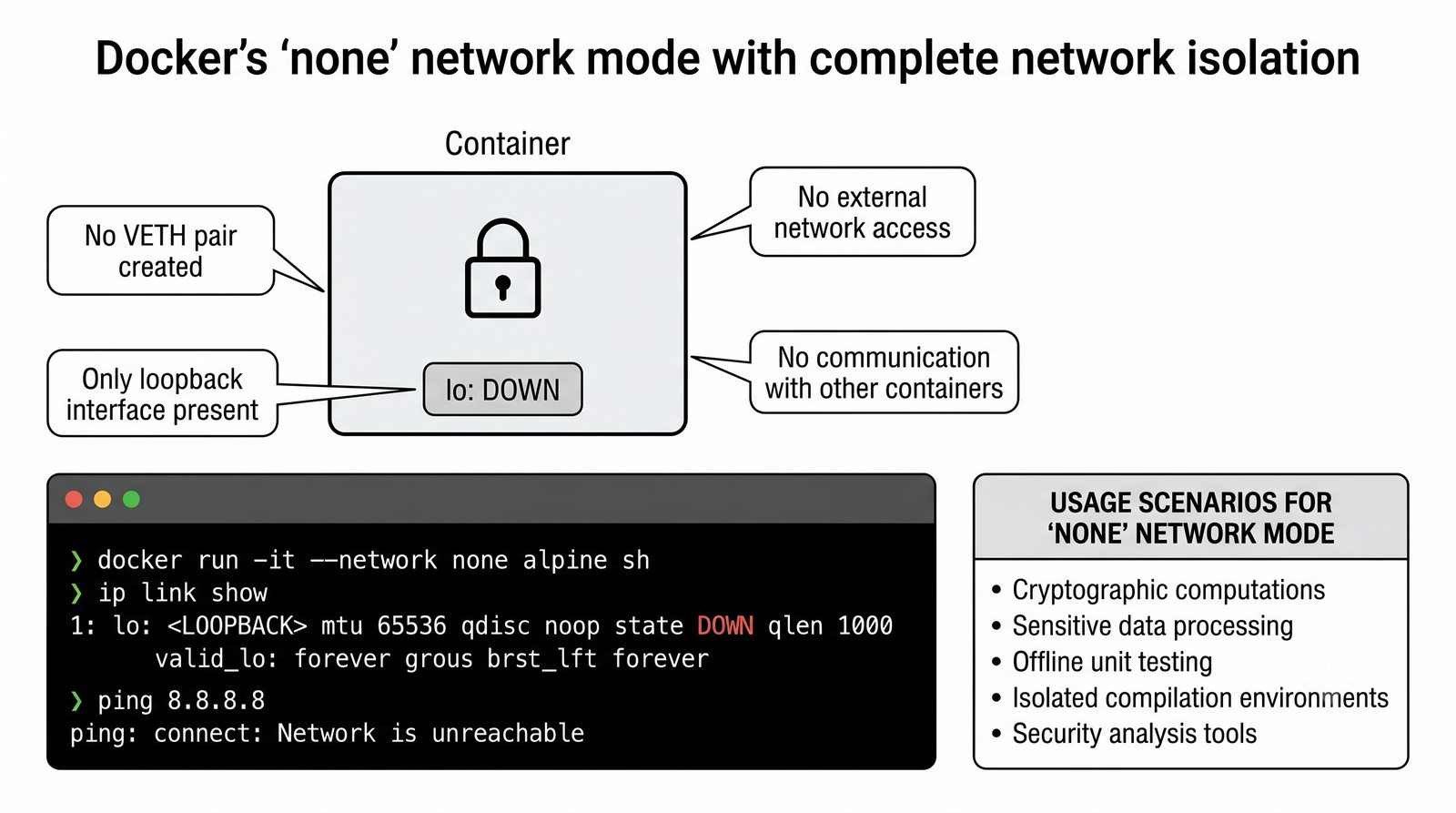
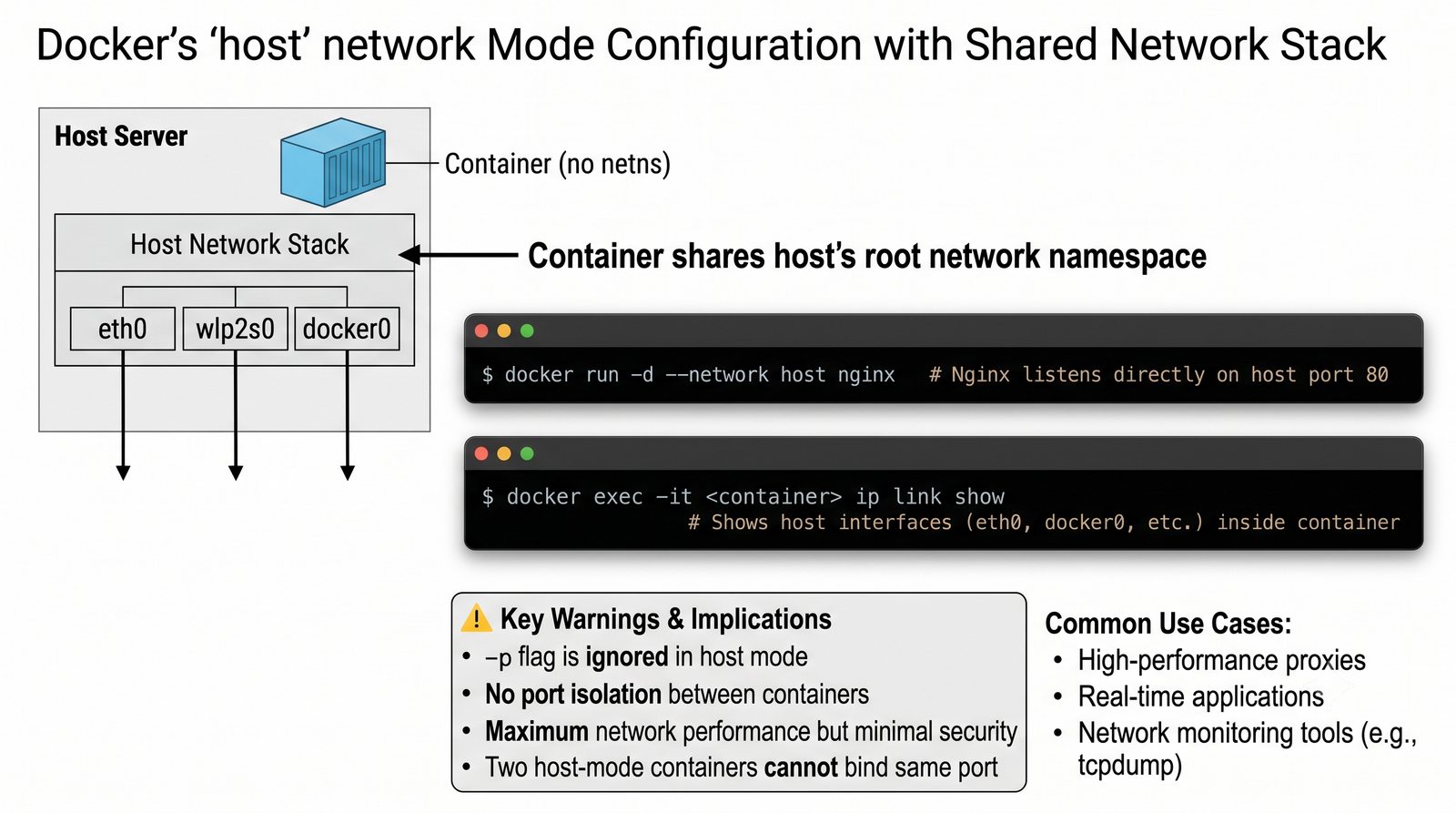
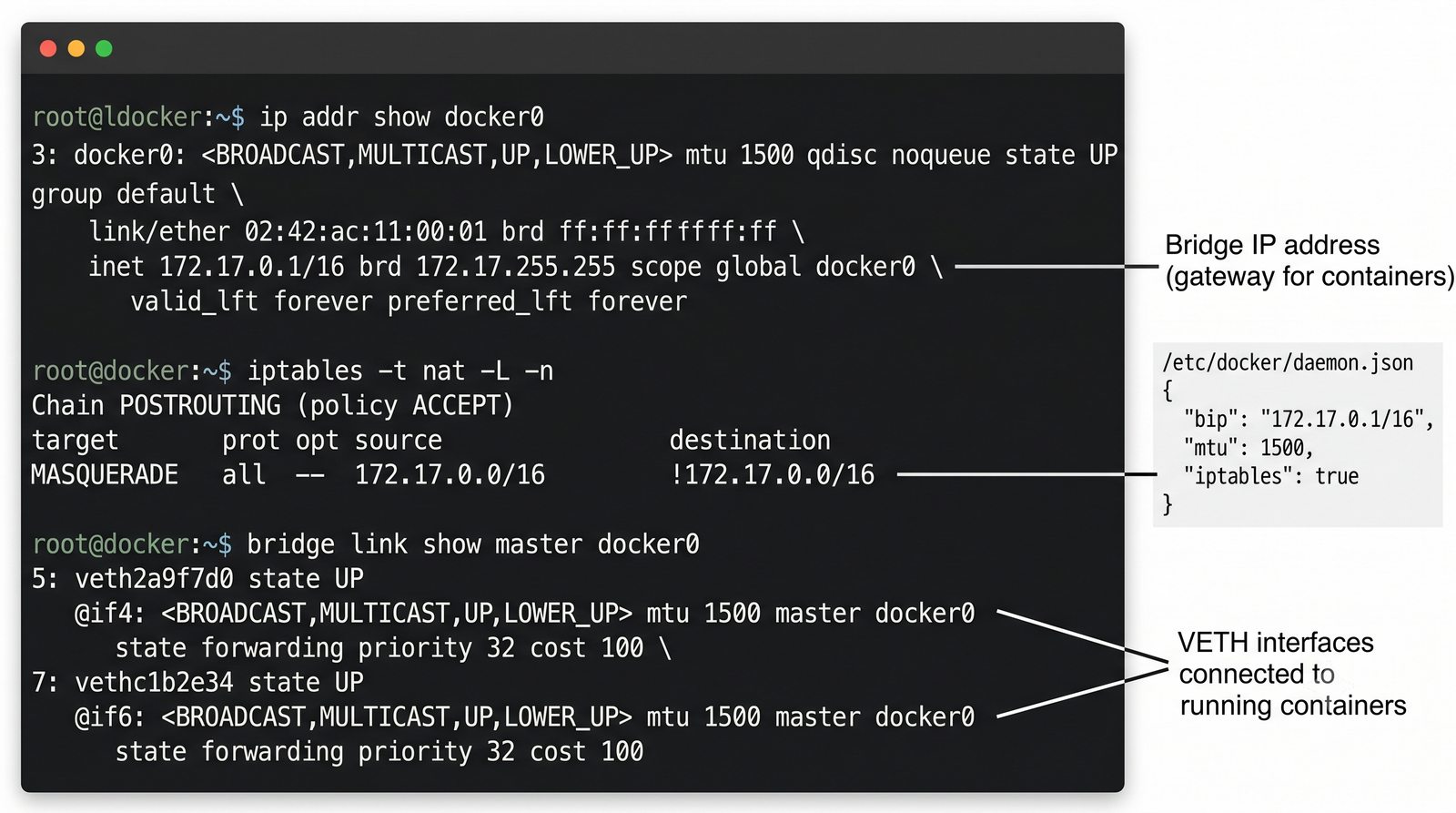
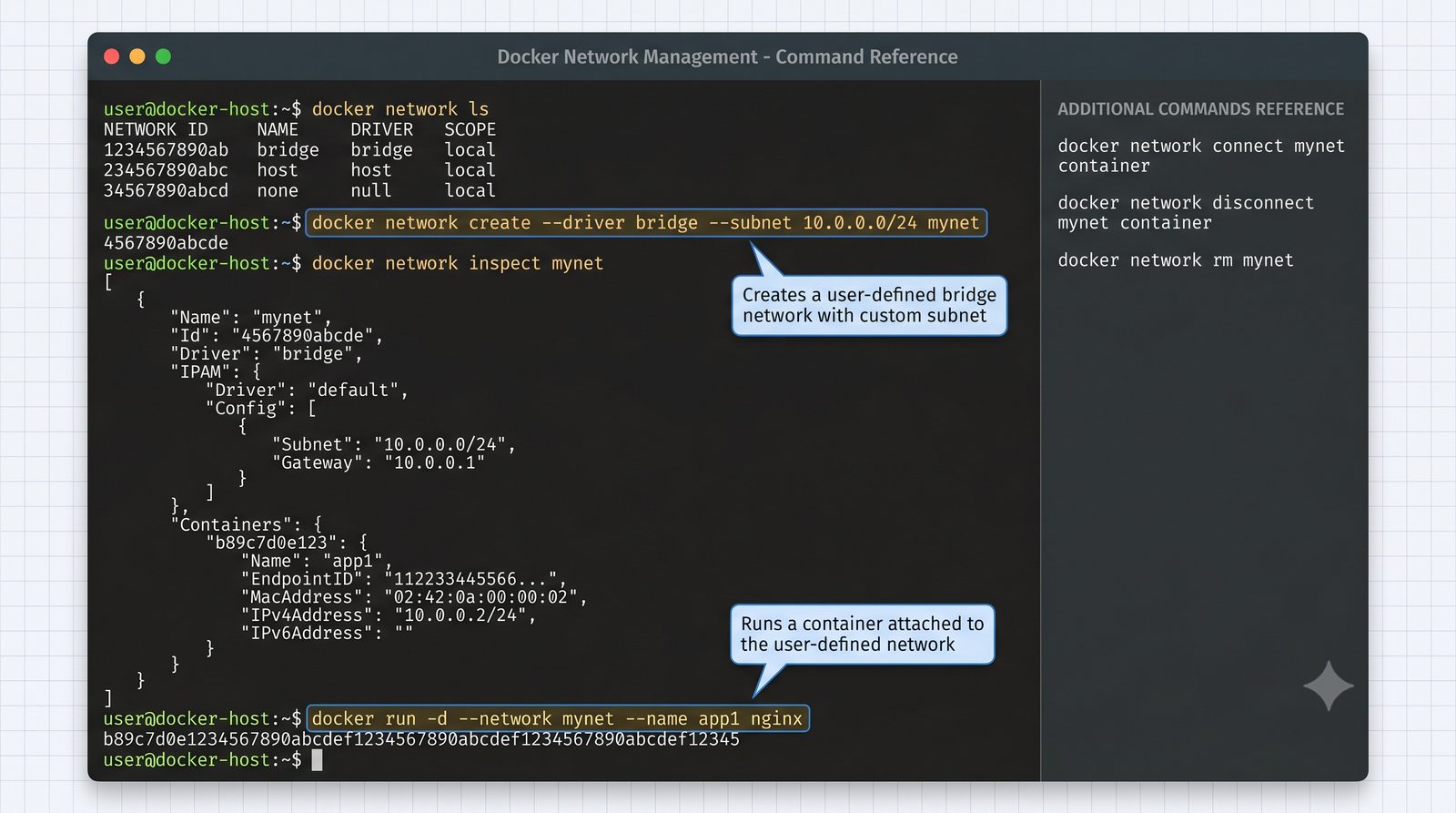
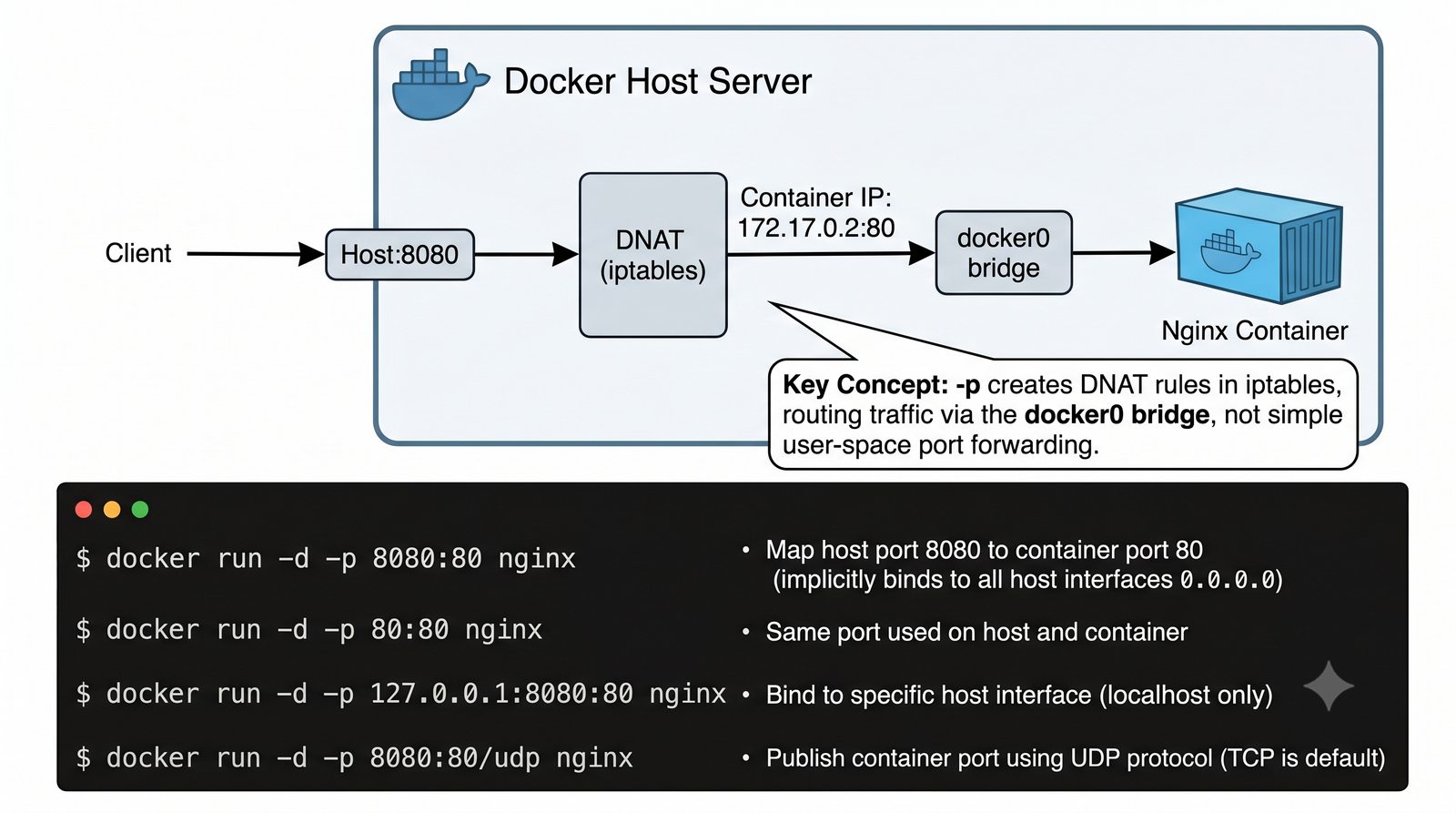
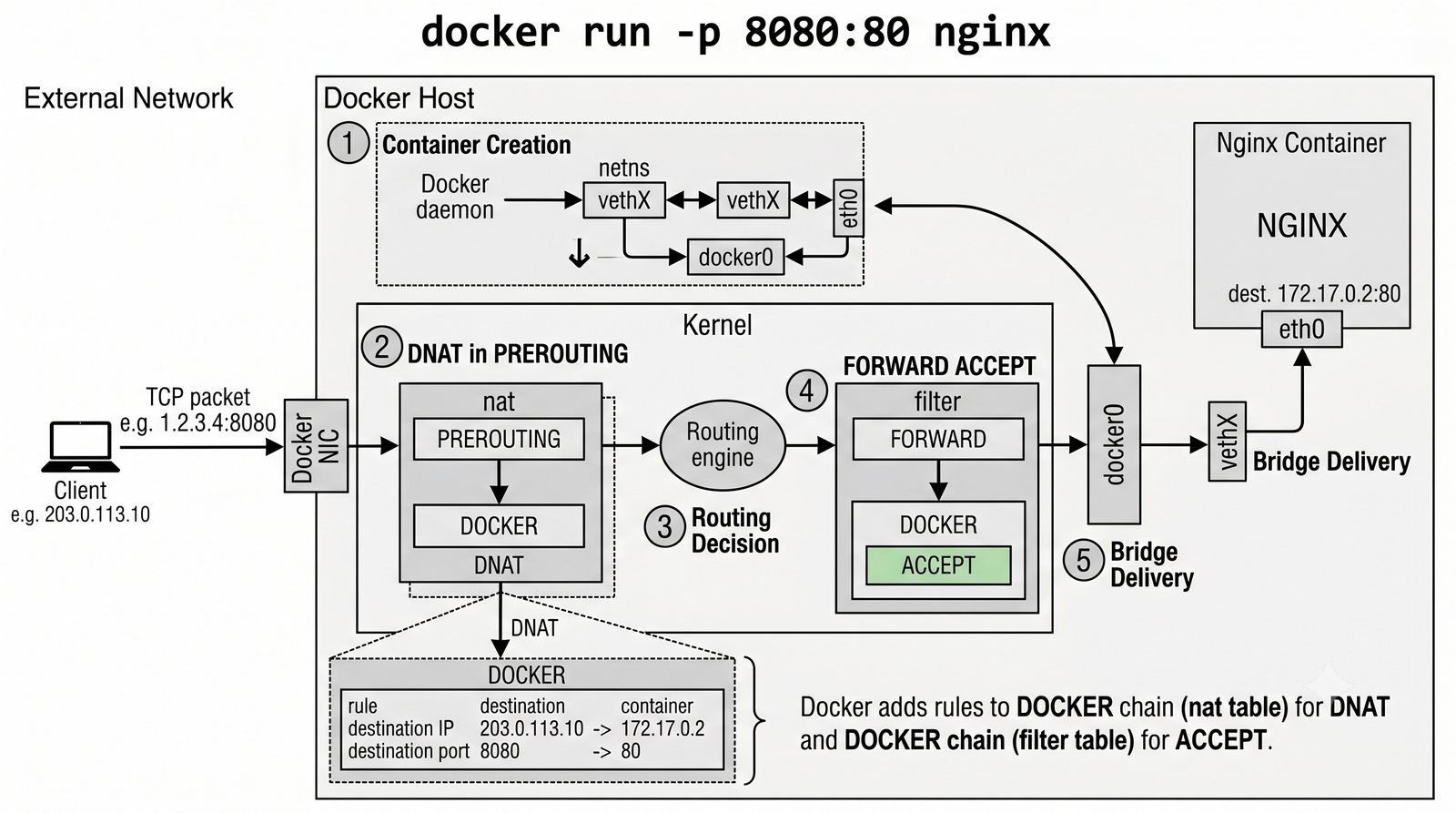
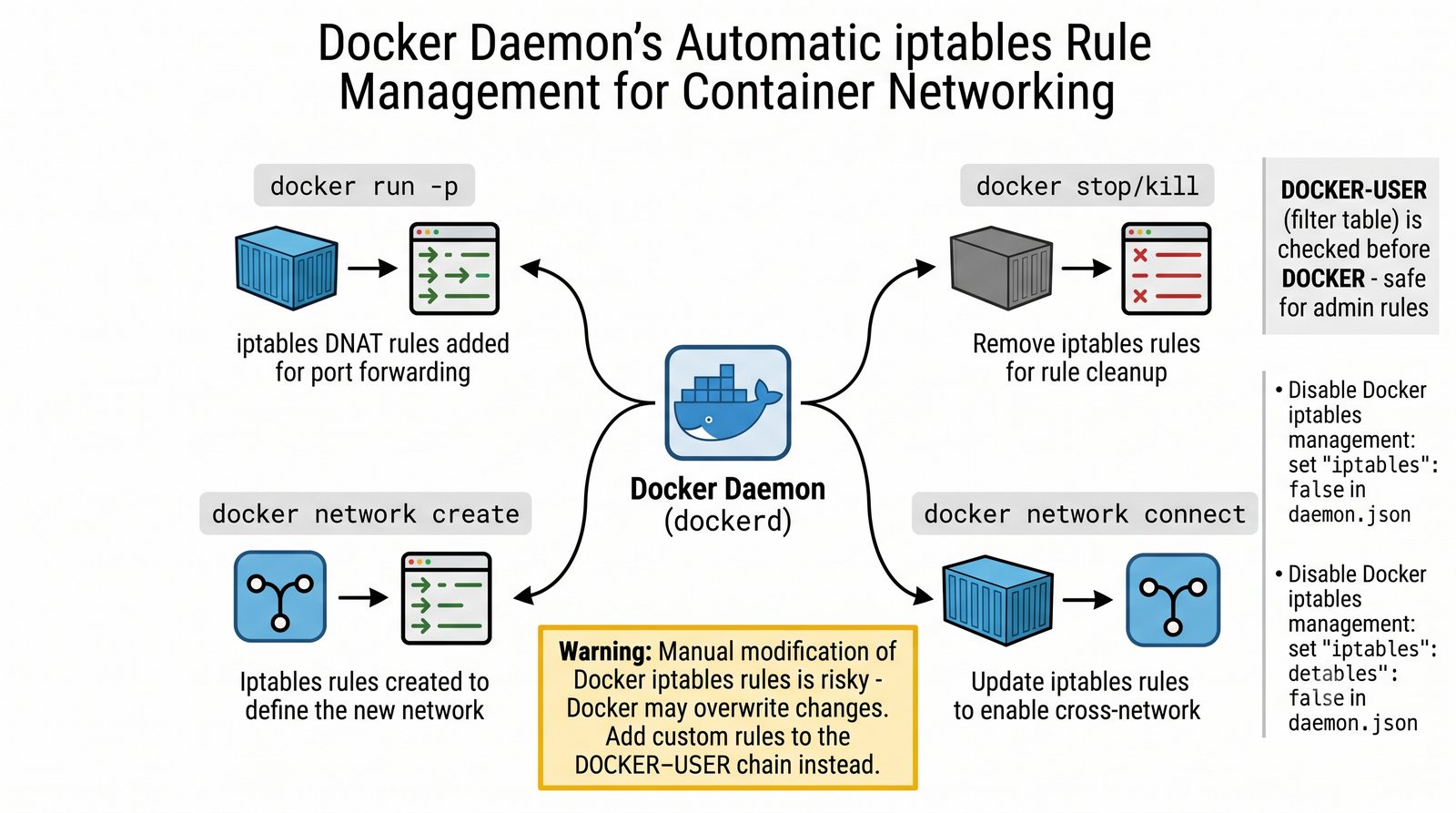
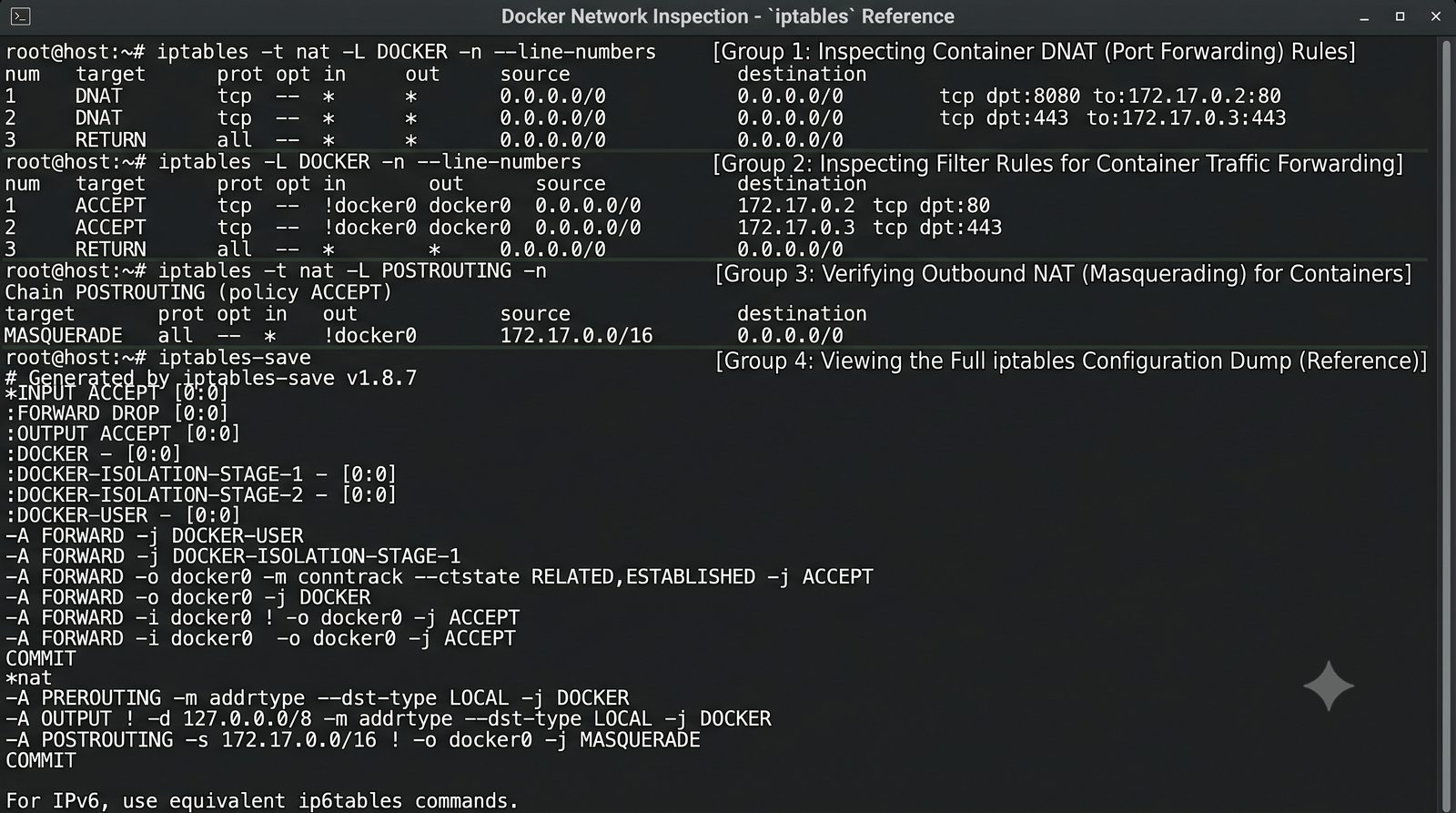
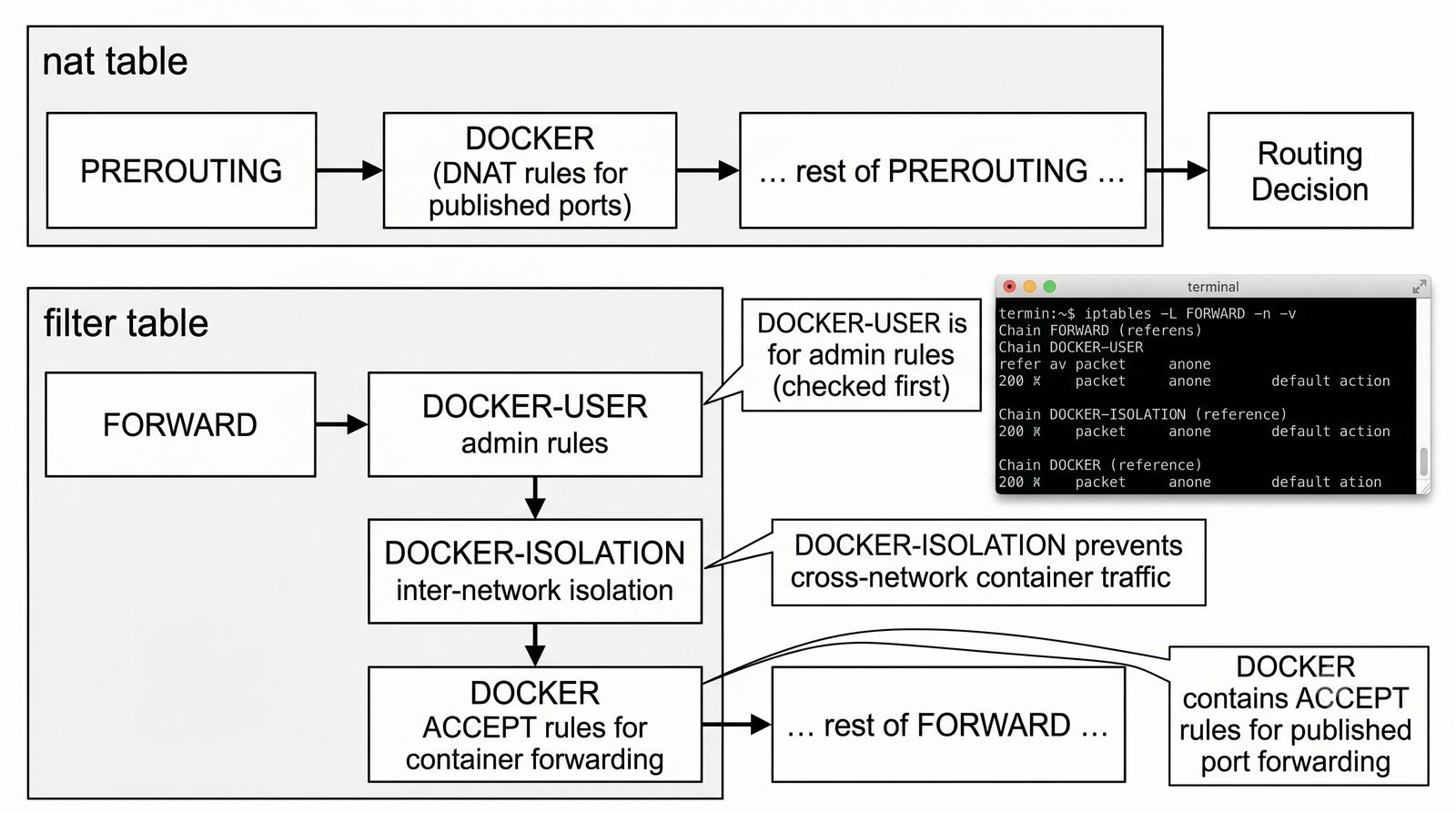
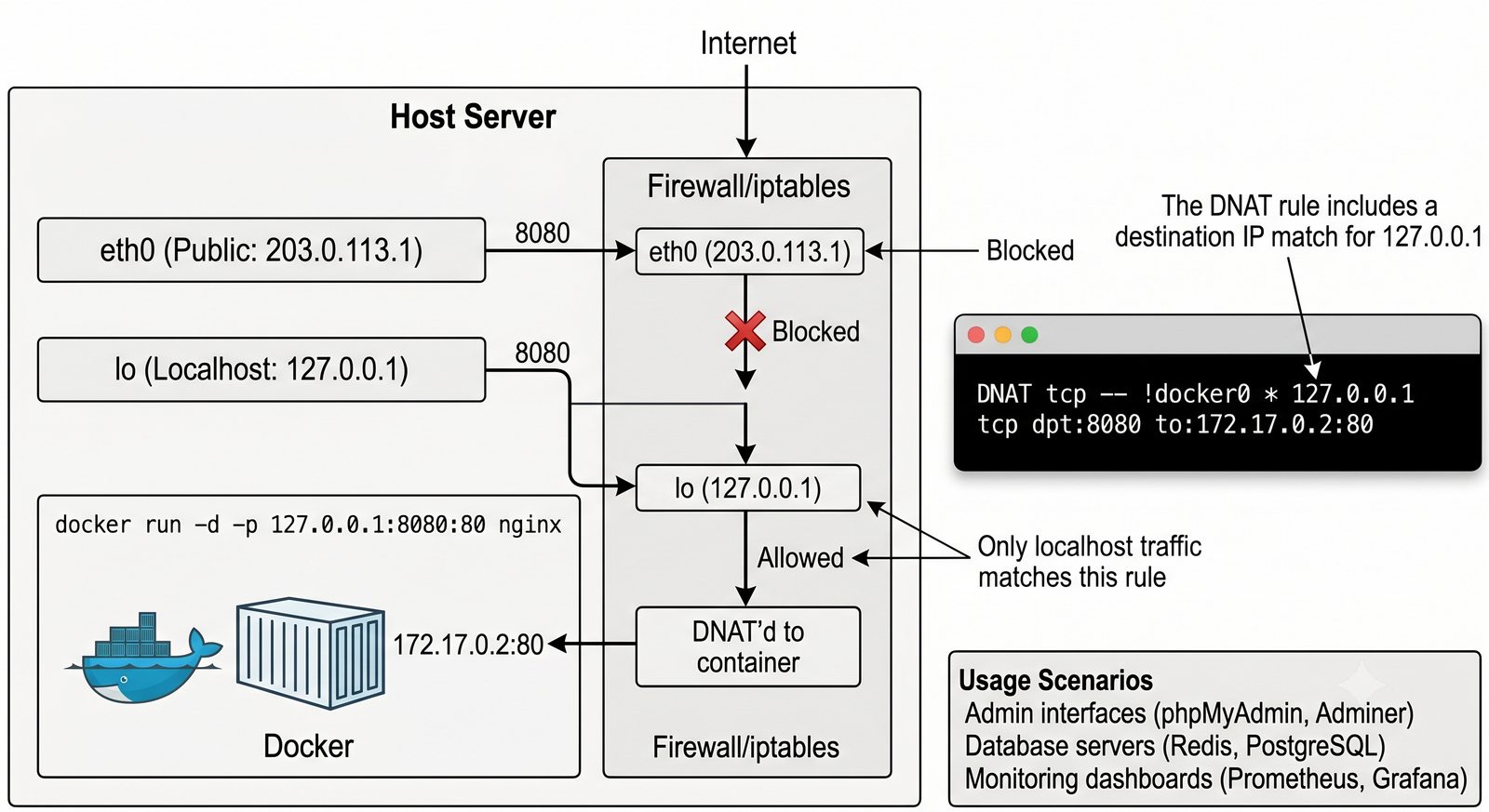
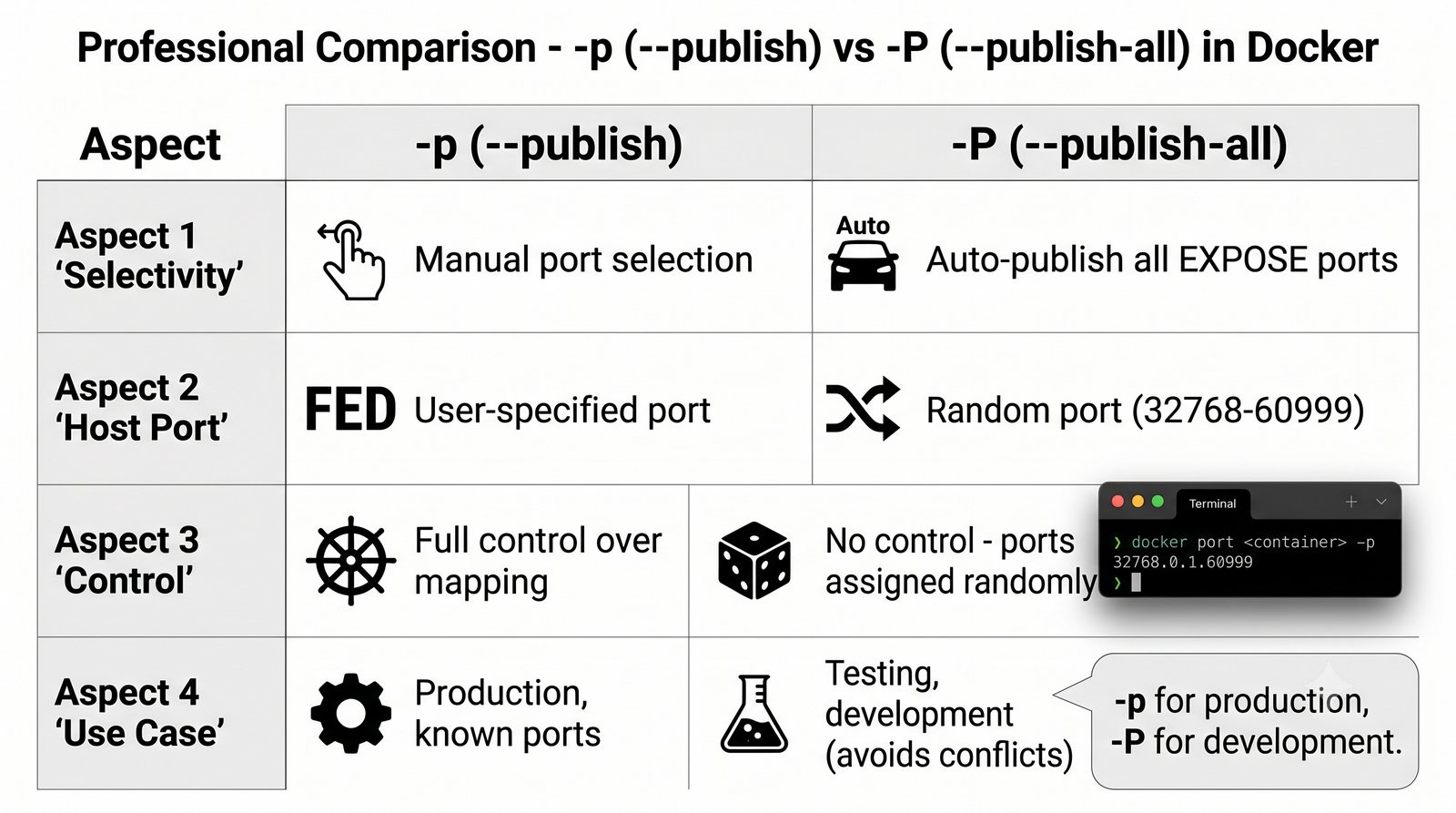
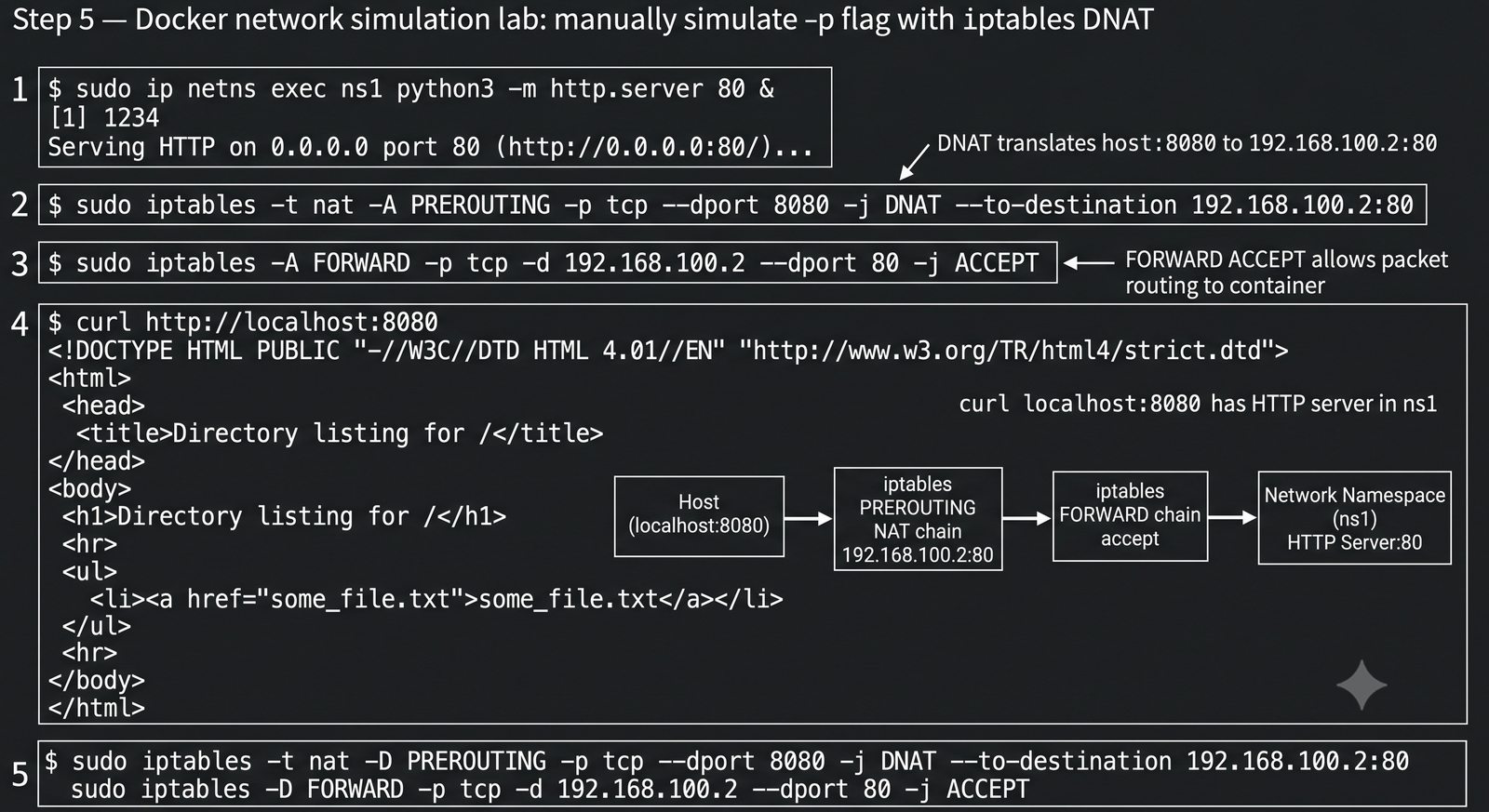
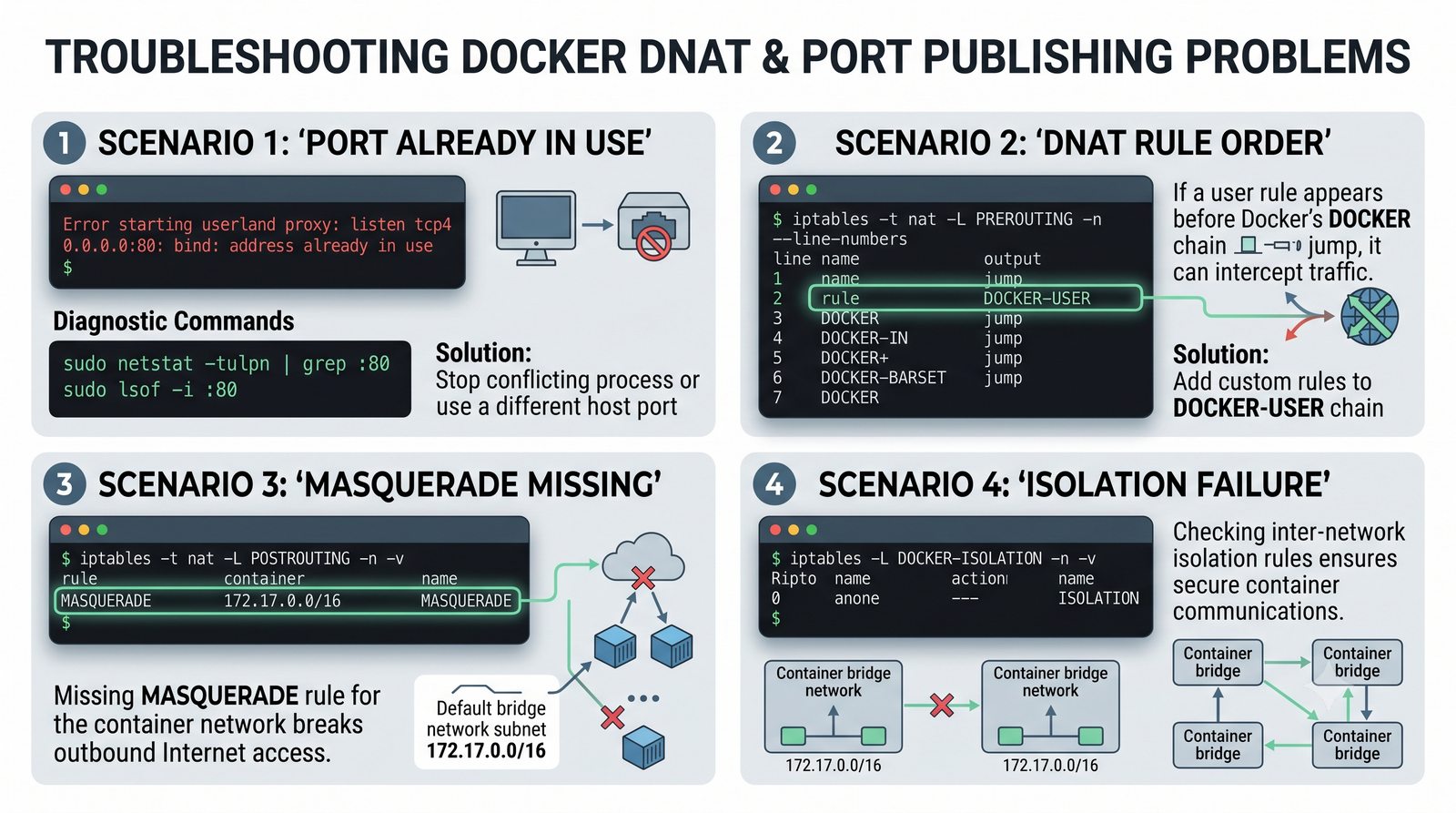
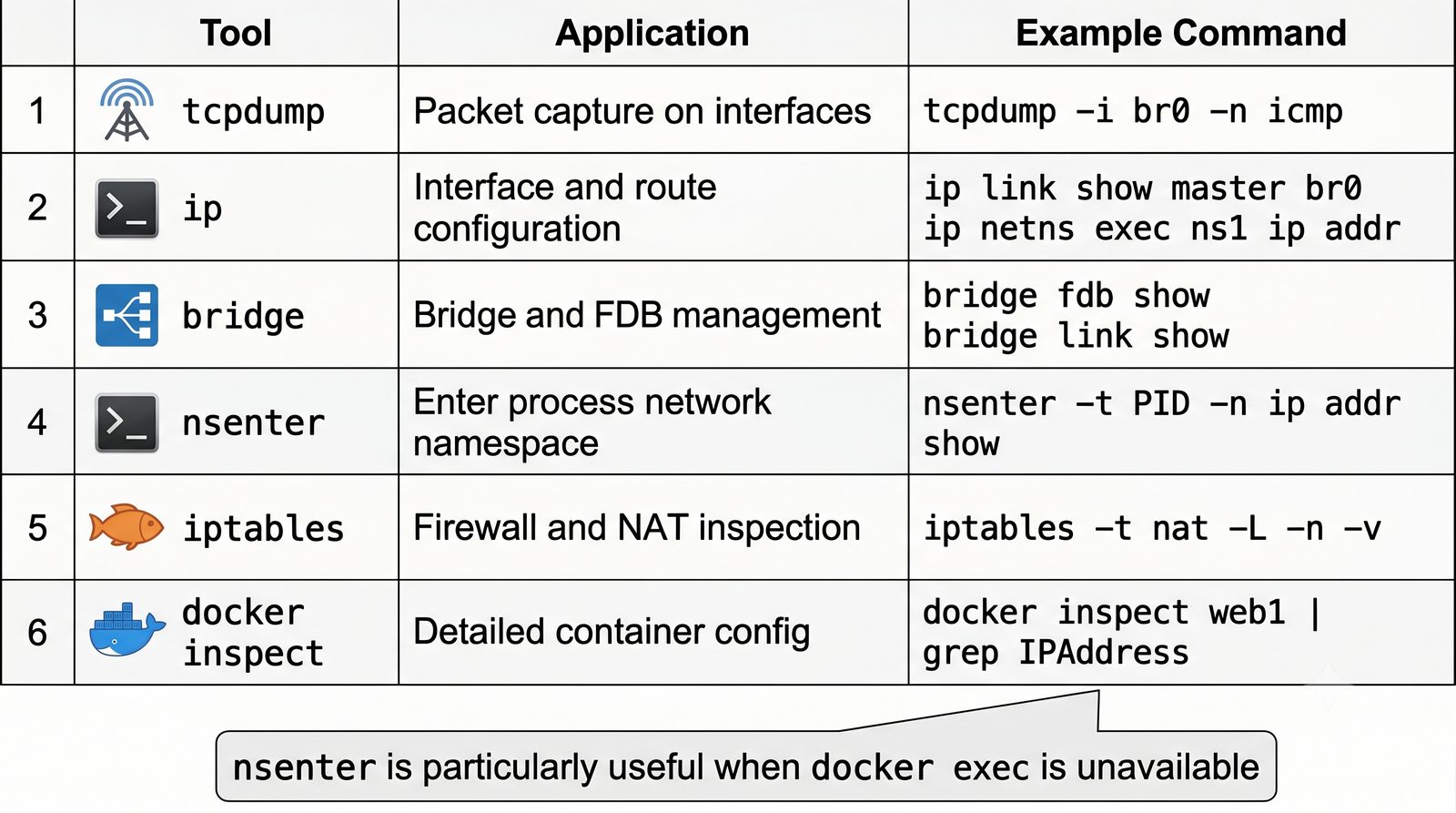
Szczególna uwaga poświęcona jest Dockerowi i jego stosowi sieciowemu: od trybu bridge przez host aż po mechanizm publikowania portów z użyciem DNAT w iptables. Każdy mechanizm jest ilustrowany rzeczywistymi poleceniami i przykładem wyjścia.