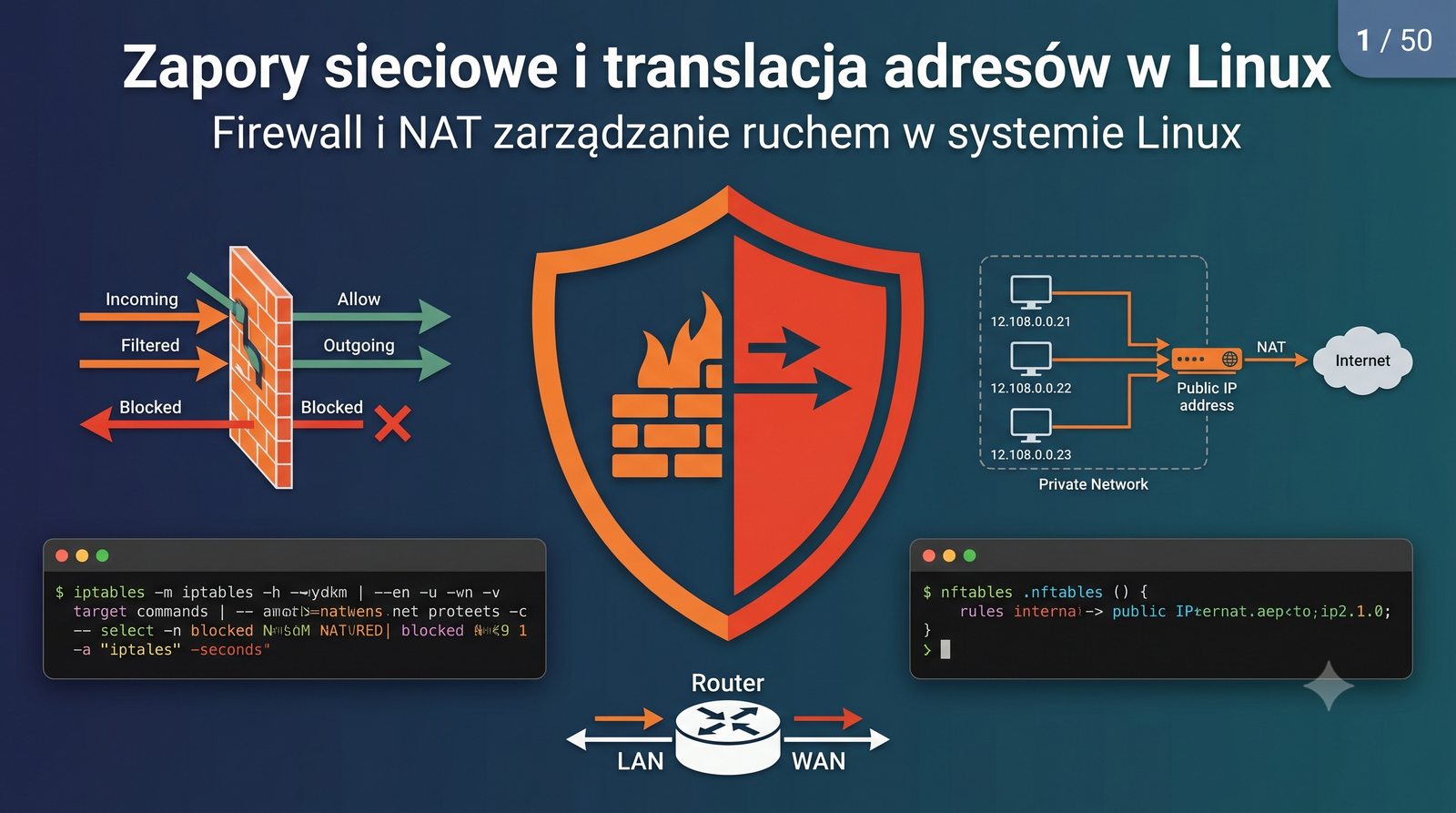
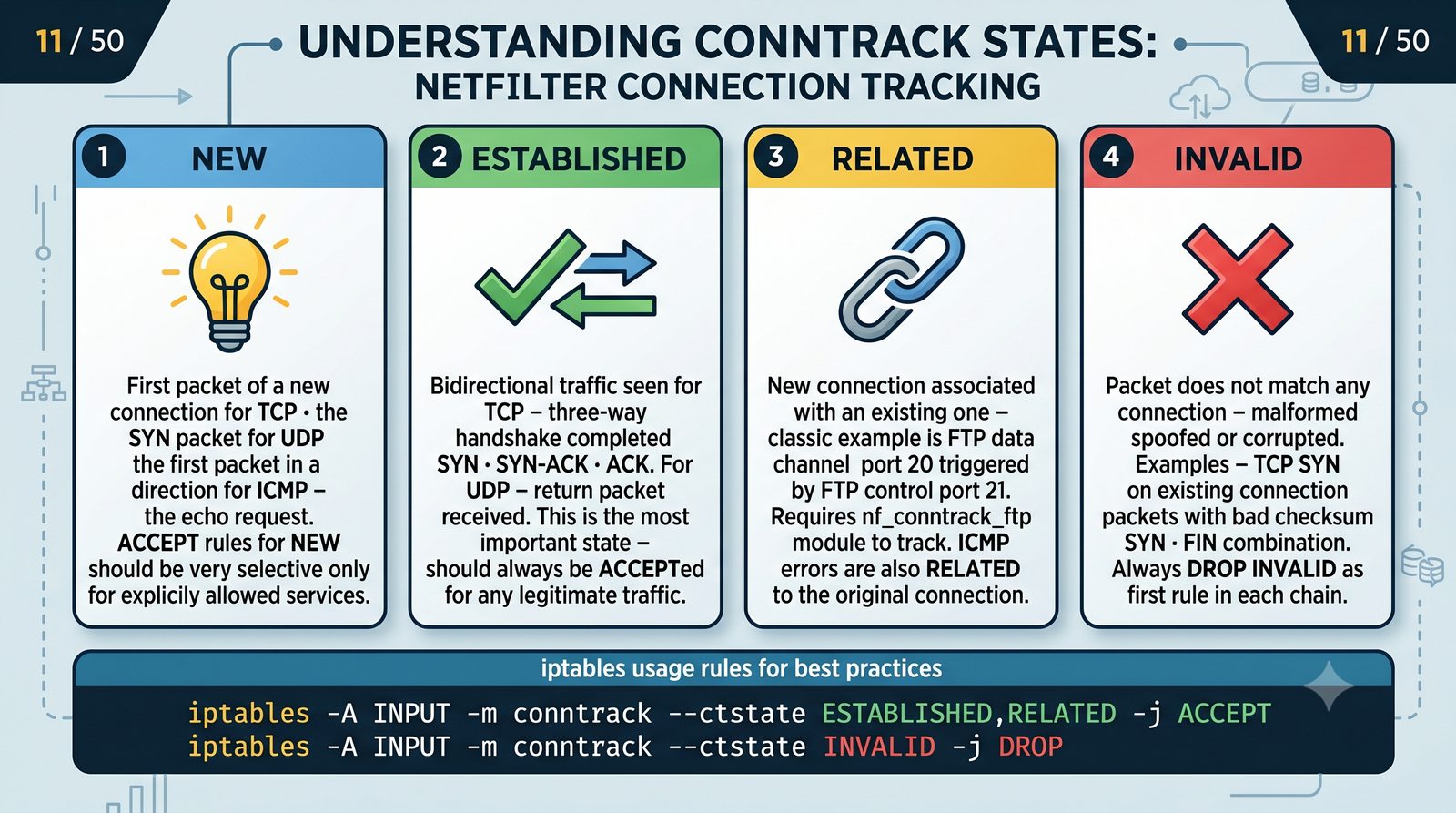
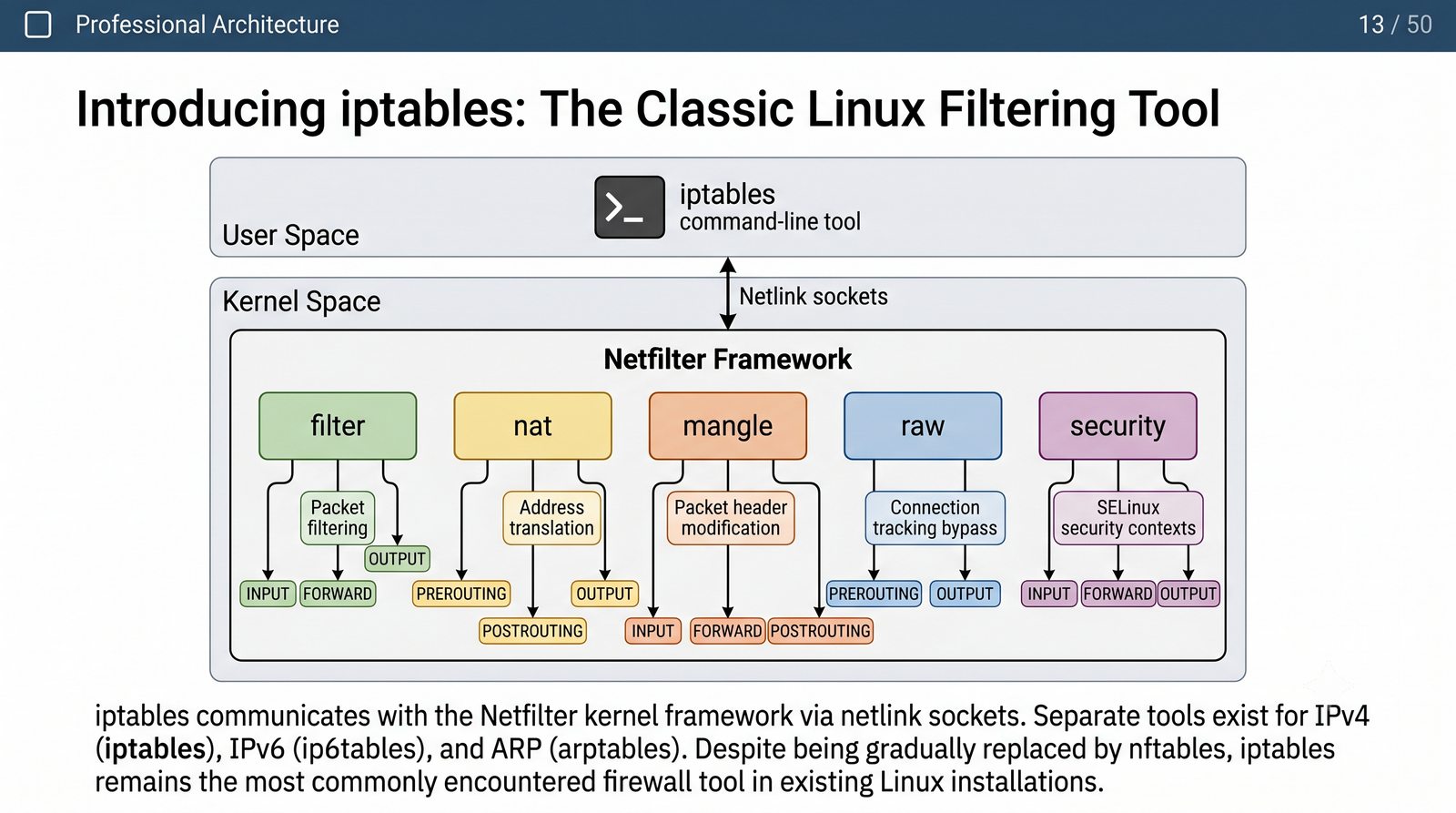
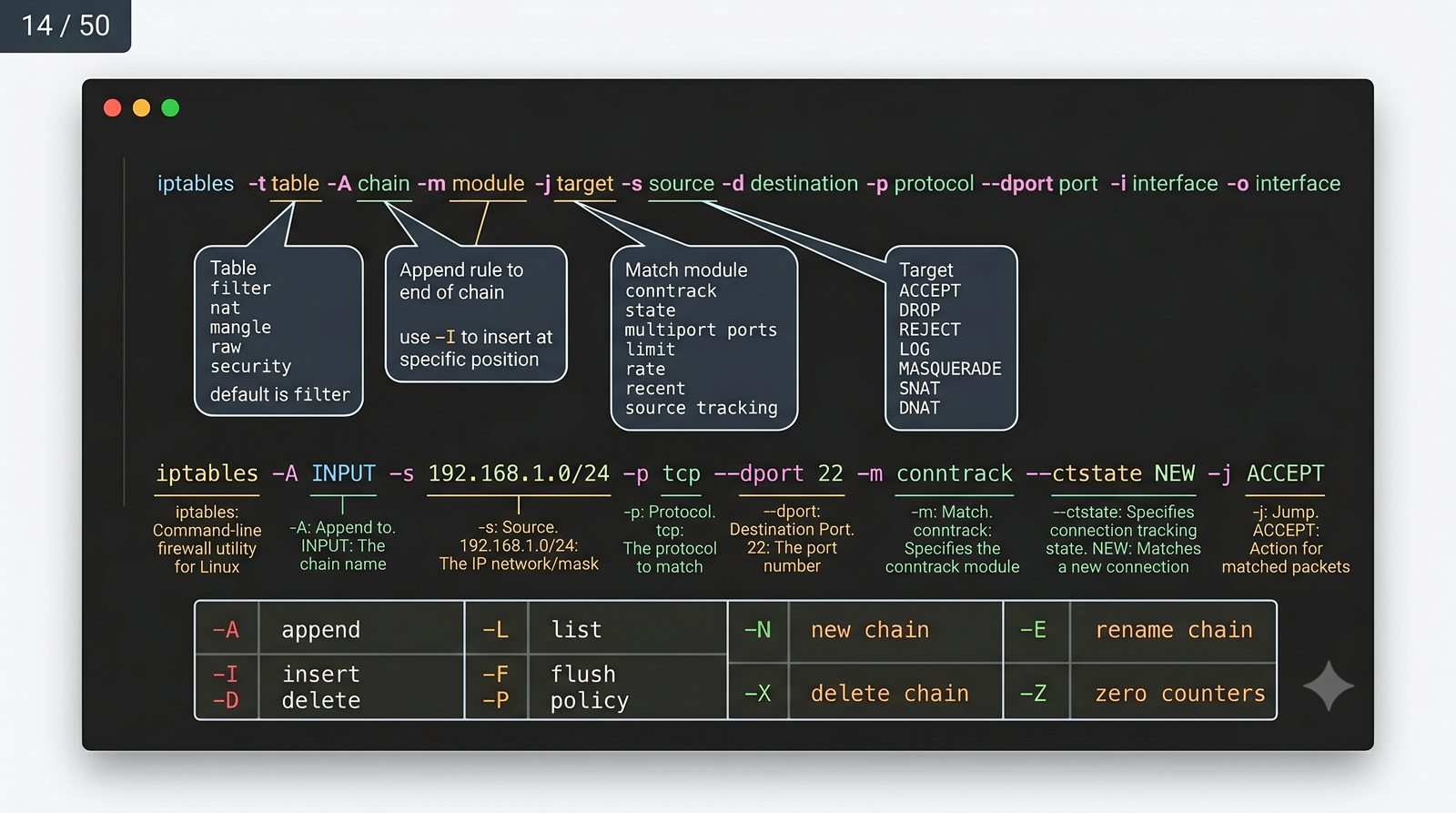
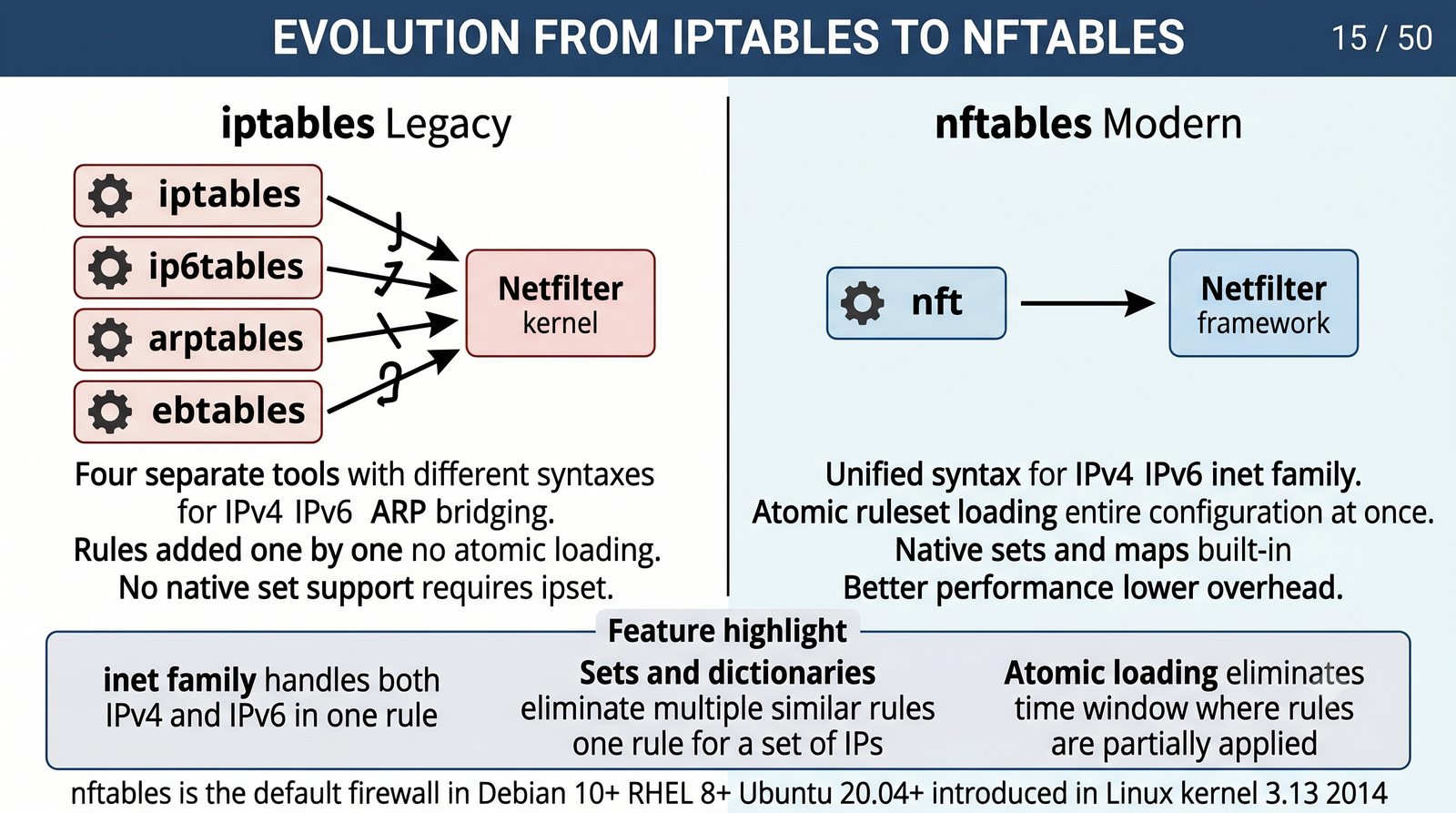
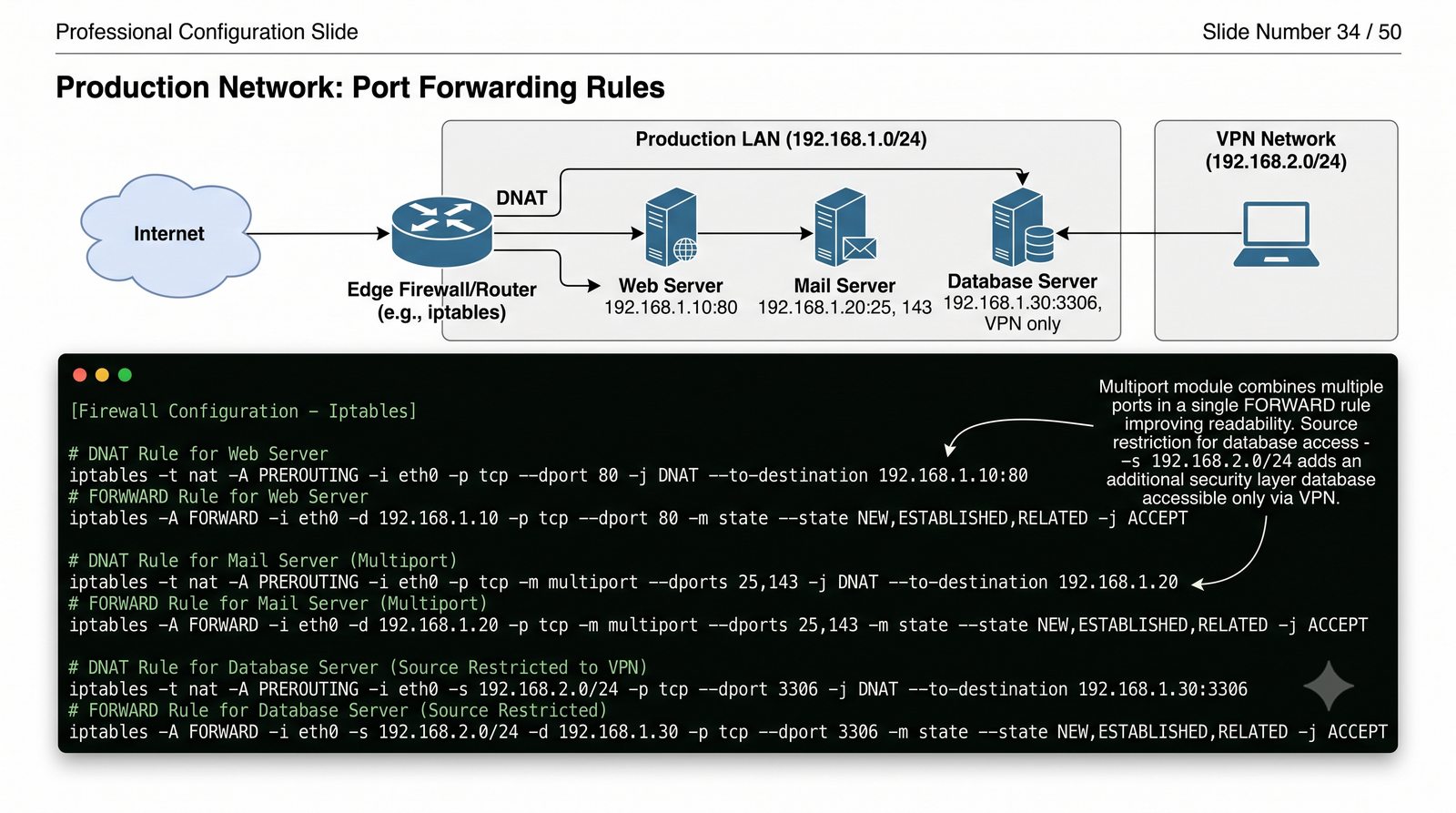
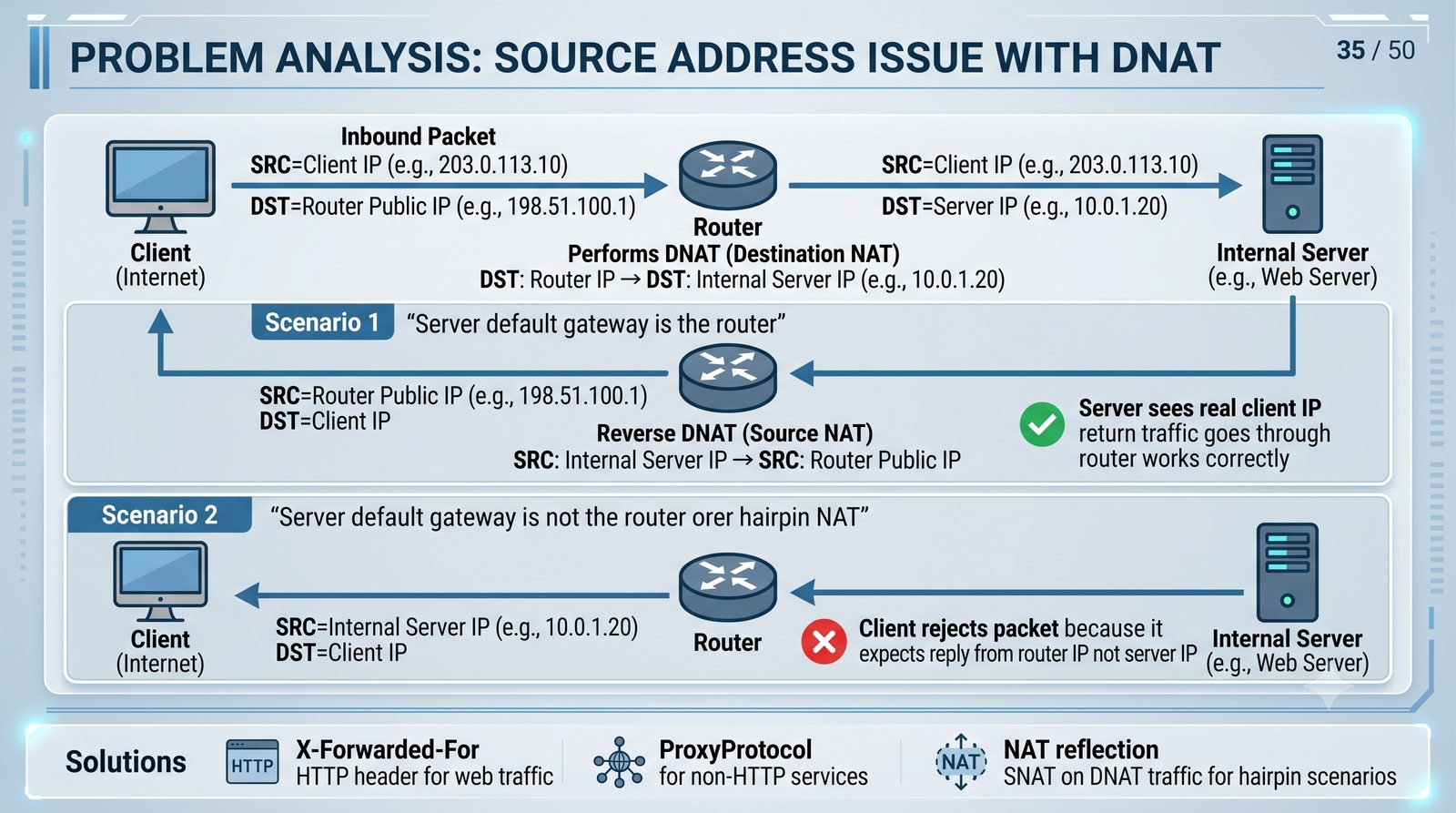
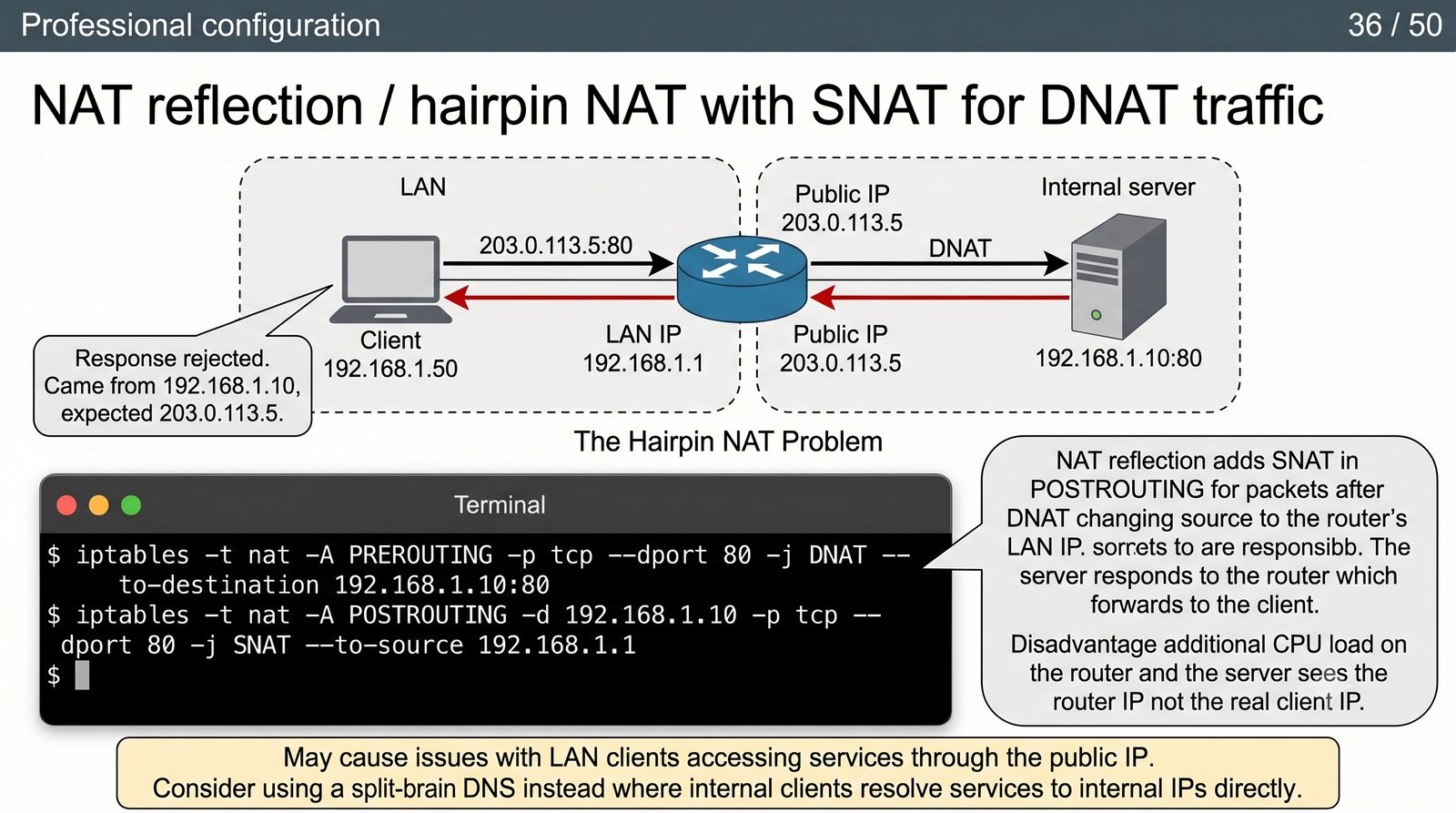
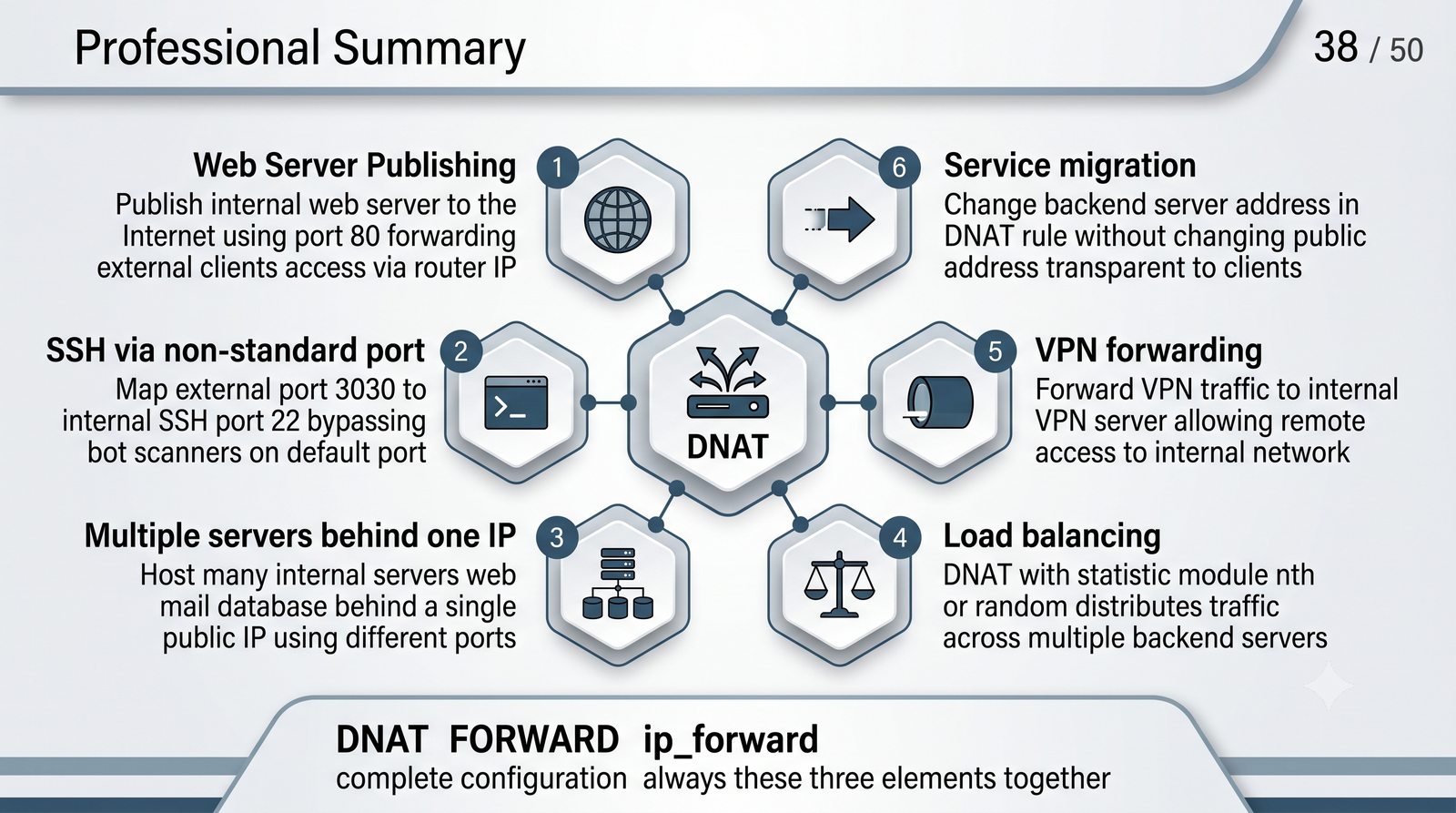
Ochrona sieci
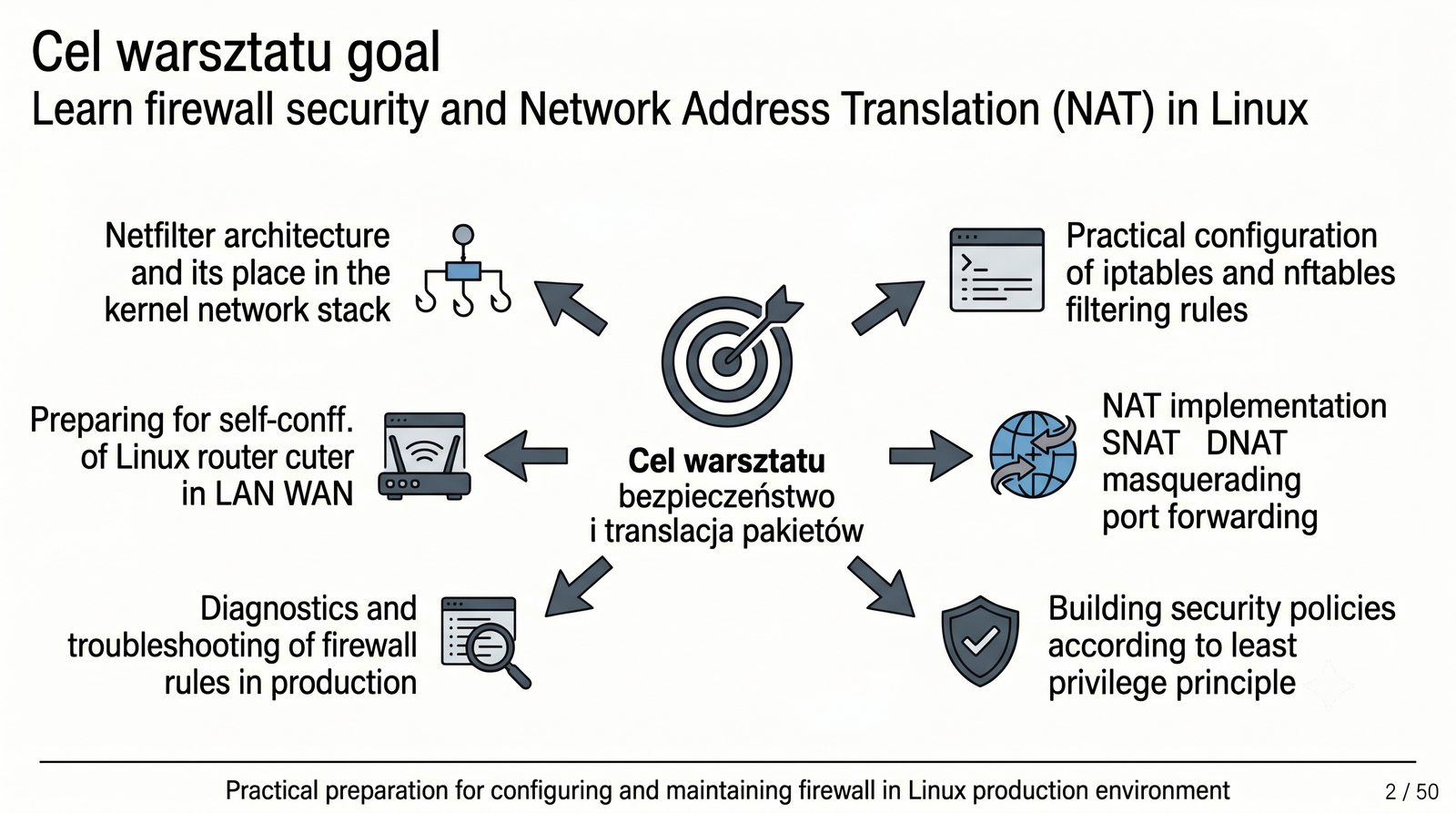
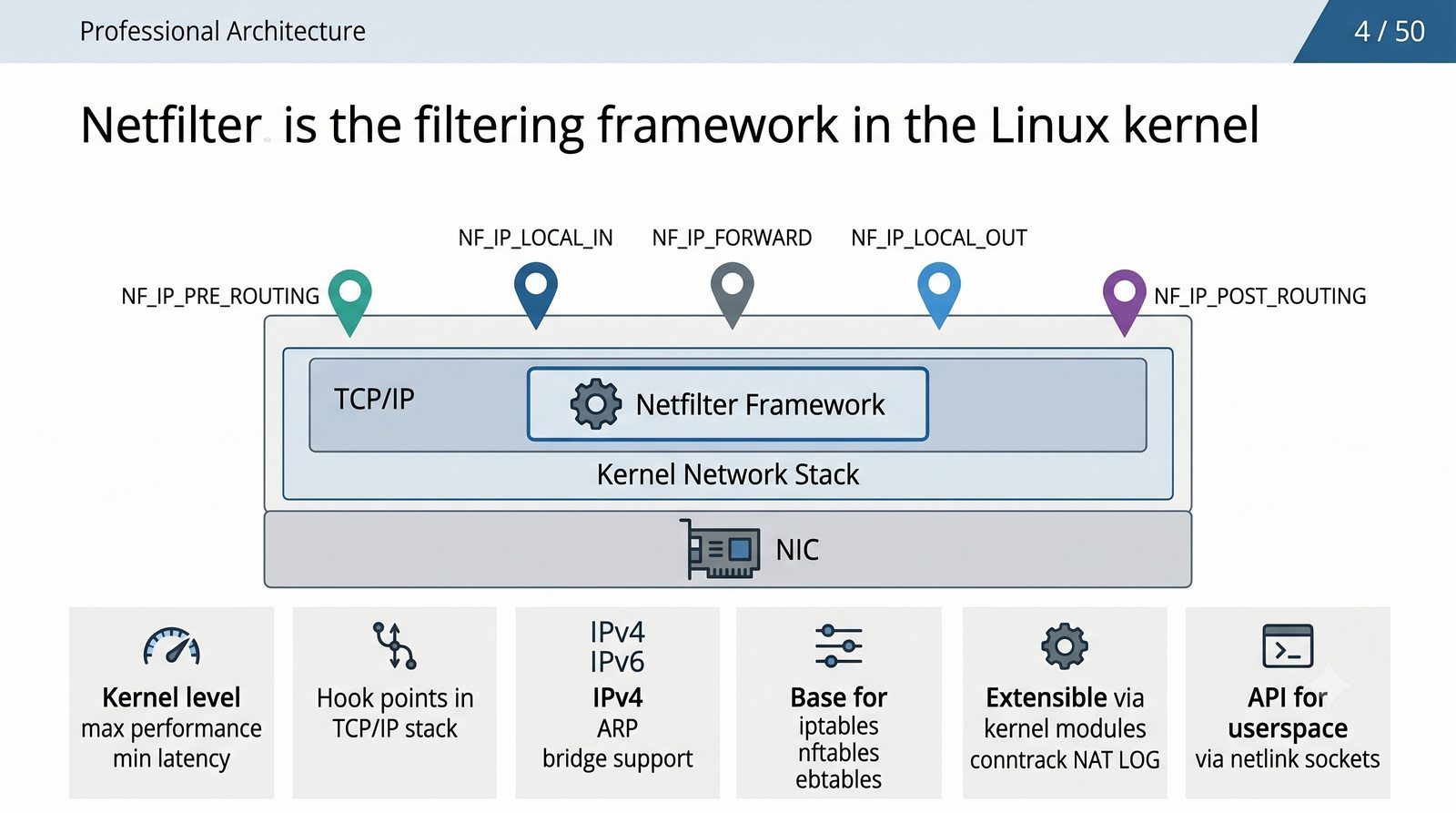
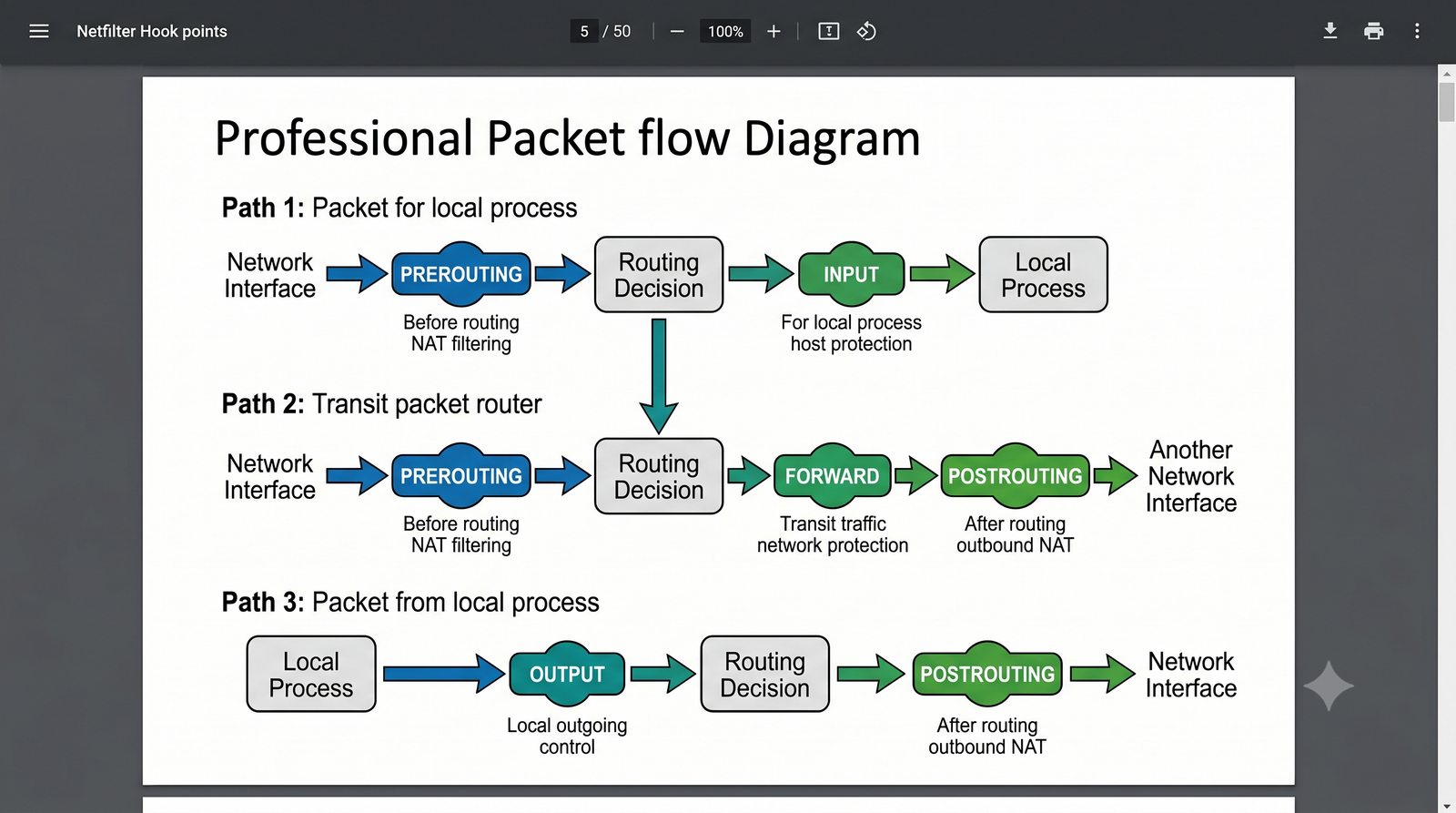
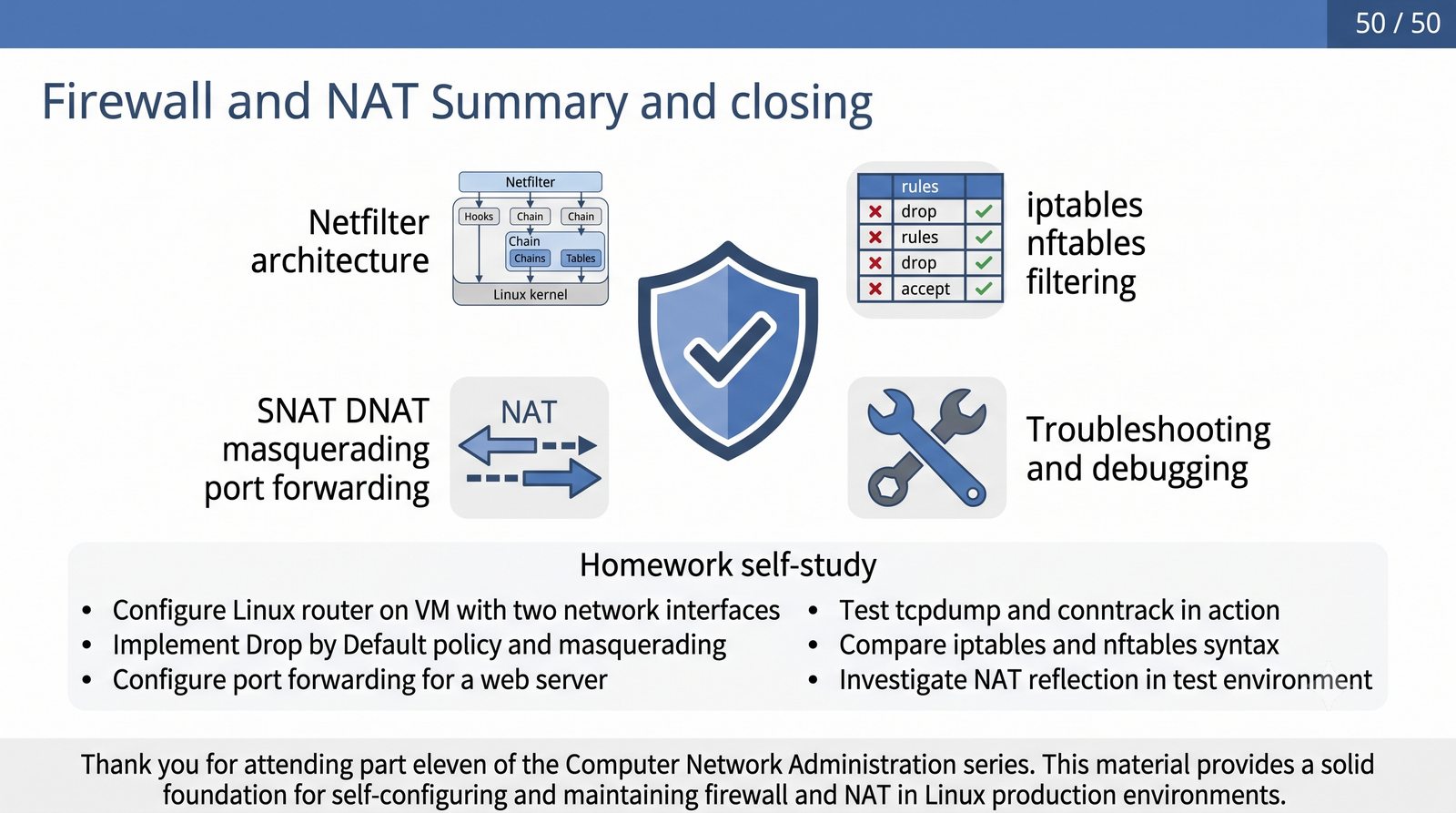
Prezentacja dotyczy zaawansowanego zarządzania ruchem sieciowym w systemie Linux z wykorzystaniem frameworku Netfilter oraz narzędzi iptables i nftables. Omówione zostaną architektura zapory stanowej i bezstanowej, mechanizmy translacji adresów NAT (SNAT, DNAT, masquerading) oraz przekierowanie portów w środowisku produkcyjnym. Jest to jedenasta część cyklu Administracja Sieci Komputerowych.